Objective
It can be difficult to know where to begin when starting a data engineering side project. If you have wondered
What data to use for your data project?
How to design your data project?
Then this post is for you. We will go over the key components, and help you understand what you need to design and build your data projects. We will do this using a sample end-to-end data engineering project.
Setup
Let’s assume that we work for an online store and have to get customer’s and orders data ready for analysis using a data visualization tool. The data pipeline architecture is shown below.
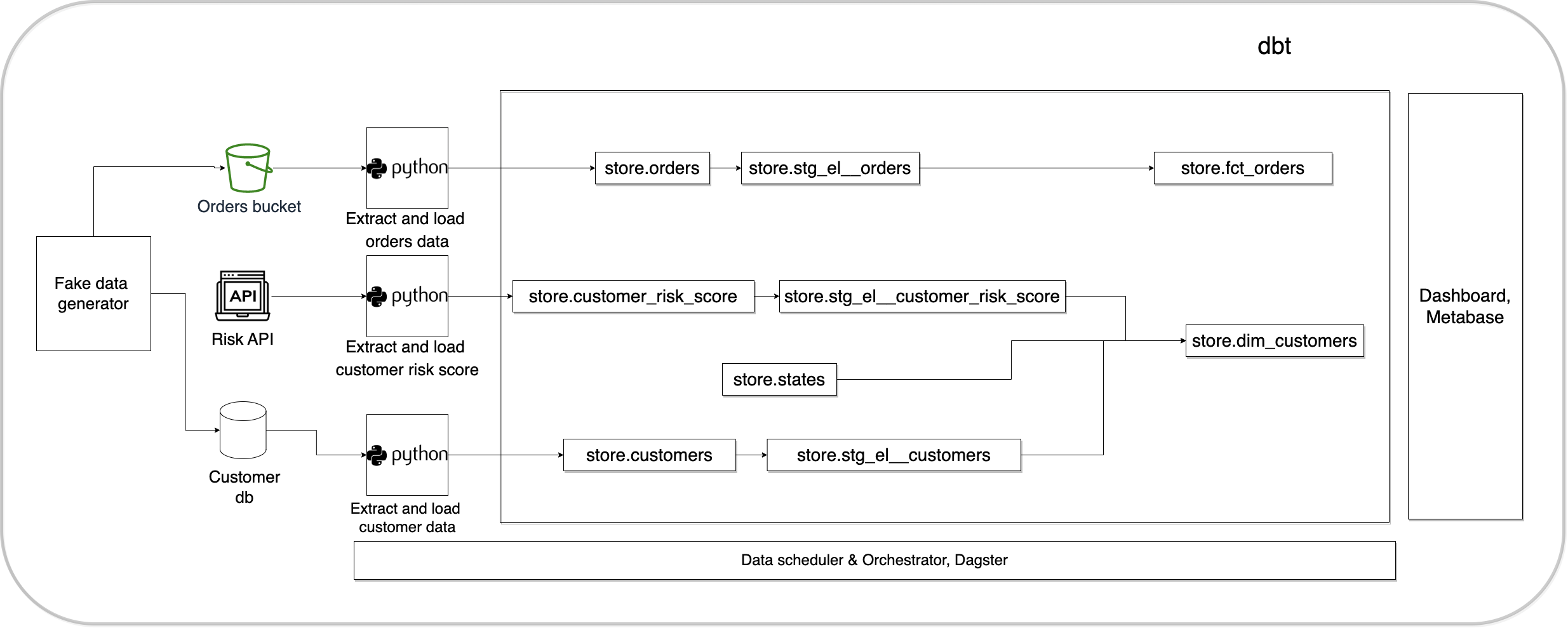
This is a standard ELT pattern, as all of the code is in python and SQL you can modify them for your data project.
Pre-requisites
- git
- Github account
- Terraform
- AWS account
- AWS CLI installed and configured
- Docker with at least 4GB of RAM and Docker Compose v1.27.0 or later
Read this post, for information on setting up CI/CD, DB migrations, IAC(terraform), “make” commands and automated testing.
Run these commands to setup your project locally and on the cloud.
# Clone the code as shown below.
git clone https://github.com/josephmachado/online_store.git
cd online_store
# Local run & test
make up # start the docker containers on your computer & runs migrations under ./migrations
make ci # Runs auto formatting, lint checks, & all the test files under ./tests
# Create AWS services with Terraform
make tf-init # Only needed on your first terraform run (or if you add new providers)
make infra-up # type in yes after verifying the changes TF will make
# Wait until the EC2 instance is initialized, you can check this via your AWS UI
# See "Status Check" on the EC2 console, it should be "2/2 checks passed" before proceeding
make cloud-metabase # this command will forward Metabase port from EC2 to your machine and opens it in the browser
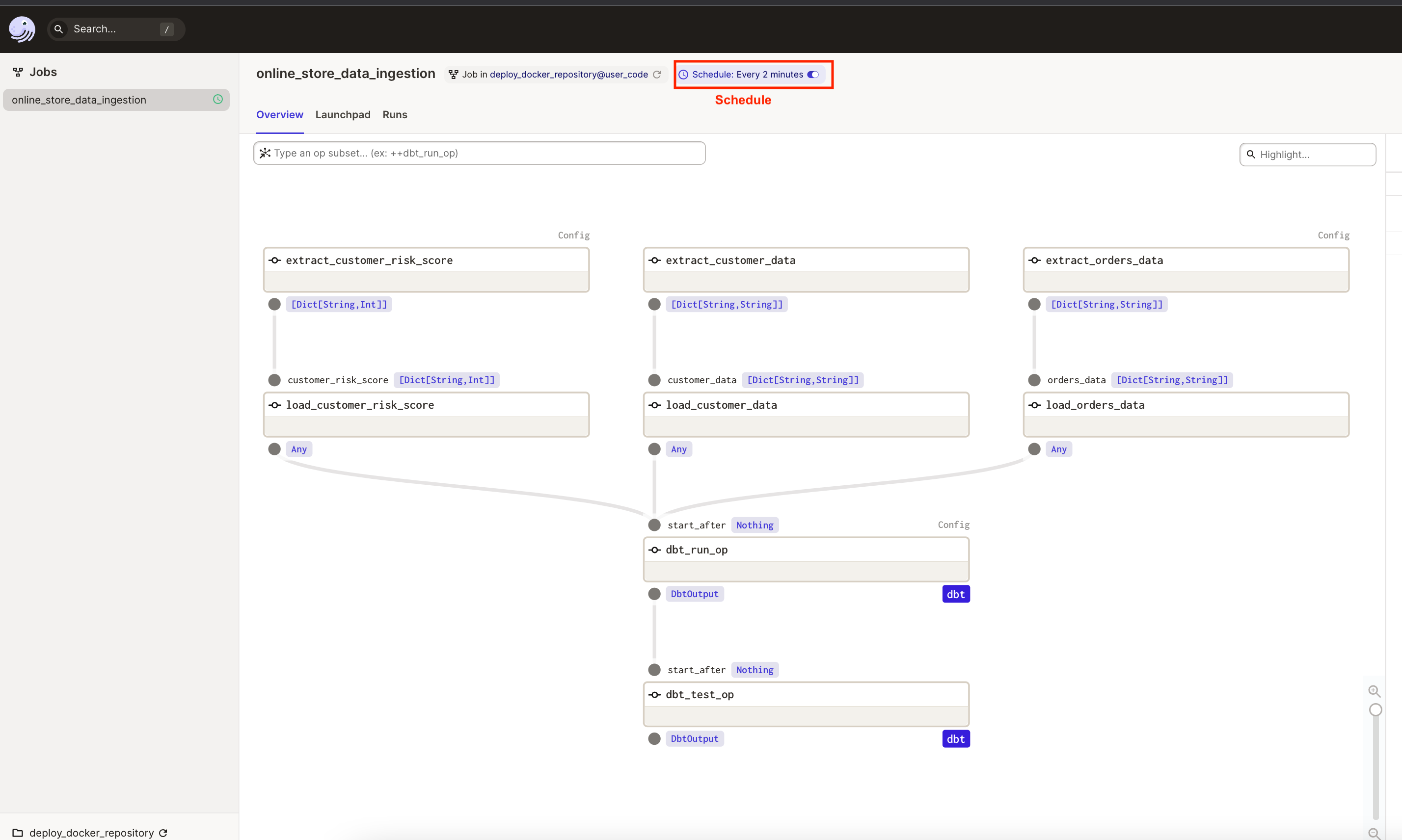
make cloud-dagster # this command will forward Dagster port from EC2 to your machine and opens it in the browserWe use Dagster as our orchestrator and scheduler. In your cloud dagster instance (open this using make cloud-dagster) turn on the schedule button near the top of the screen.

You can connect metabase (open this using make cloud-metabase) to the warehouse with the following credentials
Create database migrations as shown below.
For the continuous delivery to work, set up the infrastructure with terraform, & defined the following repository secrets. You can set up the repository secrets by going to Settings > Secrets > Actions > New repository secret.
SERVER_SSH_KEY: We can get this by runningterraform -chdir=./terraform output -raw private_keyin the project directory and paste the entire content in a new Action secret called SERVER_SSH_KEY.REMOTE_HOST: Get this by runningterraform -chdir=./terraform output -raw ec2_public_dnsin the project directory.REMOTE_USER: The value for this is ubuntu.
Components
In this section, we will look at the main components of our data pipeline. The idea here is to use these as a starting point for your data project.
Source systems
In real data pipelines, you will use sources such as your internal database, APIs, files, cloud storage systems, etc. We use a data generator that creates fake source data, and a fast API server to serve fake customer risk scores. The tables are created when we spin up docker containers using the customer DB setup script and warehouse tables setup script.
If you cannot find publicly available datasets for your problem of interest, generating fake data is a good alternative.
Schedule & Orchestrate
Orchestrator is the tool/framework used to ensure that the tasks are executed in order, retrying on failures, storing metadata, and displaying progress via UI.
The scheduler is responsible for starting data pipelines at their scheduled frequency.
We use Dagster as our scheduler and orchestrator due to its ease of use and setup. A few key concepts to understand about Dagster are:
ops: These are code that does the computation. In our case, this includes are the extract, load, and transform (with inbuiltdbtop) code. Our ops are defined here.jobs: We use a job to define the order of execution of operations. Our data ingestion job is defined here.schedules: Schedules define the frequency of a job run. Our schedule is defined here.repository: Jobs and schedules are organized into repositories. Our repository is defined here.
Given below is the code that chains together ops to create our job.
Notice how our python job shown above creates the data pipeline shown below.
Extract
Extractors pull data from the source system. We extract customer data from our application’s customer database, orders data from s3, and customer risk scores from an API endpoint.
Load
Loaders load data into the destination system(s). We load our orders, customers, and customer risk score data into store.orders, store.customers, and store.customer_risk_score warehouse tables respectively.
We can also load data into other systems as needed. E.g. load customer data into an elastic search cluster for text-based querying, orders into graph database for graph-based querying, cache systems, etc.
The code for extract and load components are present here as load_* functions.
Transform
Transformers clean, apply business logic and model the data ready to be used. This transformed data is used by our stakeholders.
We use dbt to execute our transformation scripts. We de-duplicate the data, cast columns to the correct data types, join with other tables (customer risk score and states), and create the fct_orders and dim_customers views as shown below (based on Kimball modeling).
dim_customers 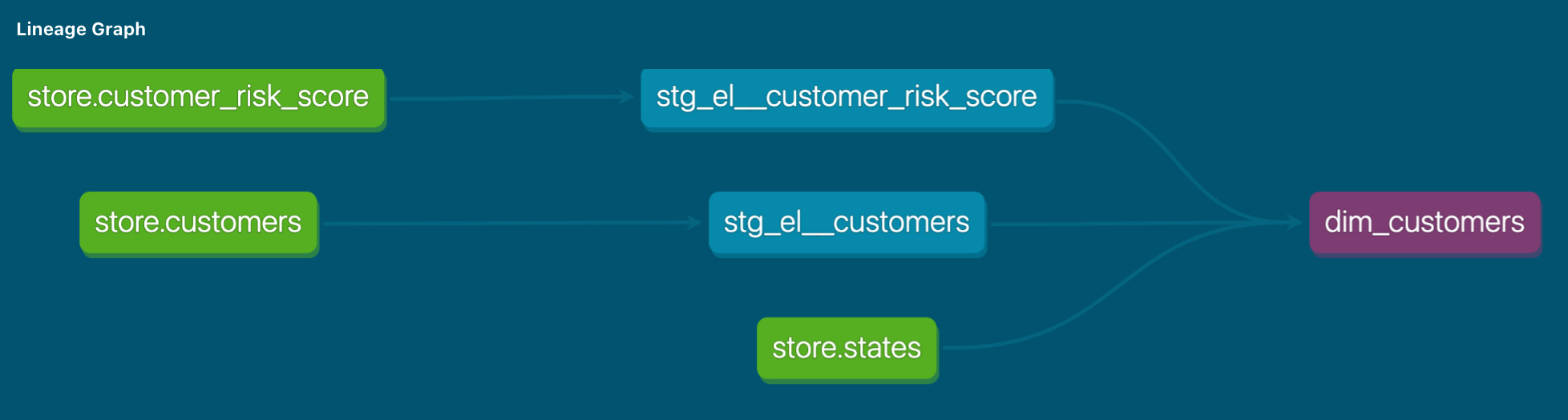
fct_orders 
Recommended reading:
Data visualization
Data visualization tools enable business users, analysts, engineers to generate aggregates at different levels, create sharable dashboards, write sql queries, etc. They do not have to connect directly to our warehouse.
We use metabase as our data visualization tool.
Choosing tools & frameworks
We have used open-source software to make development easy, free, and configurable. You may want to switch out tools as necessary. E.g. Fivetran instead of our custom code, etc.
Recommended reading:
Future work & improvements
While we have a working data pipeline, there are a lot of possible improvements. Some of the crucial ones are listed below.
Idempotence: In thecustomerload step we insert all the data for the past 5 minutes into our warehouse. This process will result in duplicate data since our pipeline runs every 2 minutes. Making the load step idempotent will prevent duplicate data. Read this article on how to make your data pipelines idempotent for more details.Backfills: Backfilling is an inevitable part of data engineering. To learn more about backfills and how to make our data pipeline backfill-able, read this articleChange data capture & Slowly changing dimensions: A key feature of having a data warehouse is storing queryable historical data. This is commonly done with a modeling technique called slowly changing dimension which requires us to know all the create, delete and update operations happening on the source table. We can use a technique called change data capture (CDC) to capture all the create, delete and update operations happening on the source table. Read how to implement CDC, and how to create SCD2 tables with dbt.Testing: We have a unit test and post processing dbt test for our pipeline. Read how to add tests, and how to set up CI tests to take our testing capabilities to the next level.Scale: When passing data between functions, dagster stores them in a temporary file (default). In our load steps, we load the entire data into python process memory and then insert them into the warehouse, while this works for small data sets, it will not work if the data is larger than the process memory. Read how to stream data in your python process and how to scale your data pipeline for ideas on how to handle big data.
Please feel free to create an issue or open a PR here.
Conclusion
To recap we saw
- The key components of a data pipeline
- Generating fake data
- How to design your data project
- Future work & improvements
For your data project choose the tools you know the best or would like to learn. Use this project’s infrastructure and architecture as a starting point to build your data project.
Hope this article gives you a good understanding of the key components of a data pipeline and how you can set up your data project. If you have any questions, comments, or ideas please leave them in the comment section below.
Further reading
- Want to understand what the data pipeline components are and how to choose them? Read this article.
- Read this article for a quick introduction to data warehouses.
- Curious about ways to load data into a data warehouse? Checkout this article.
- Want to do a similar project with Airflow? Checkout this article.