1. Introduction
Choosing tools/frameworks to scale your data pipelines can be confusing. If you have struggled with
Data pipelines that randomly crash
Finding guides on how to scale your data pipelines from the ground up
Then this post is for you. In this post, we go over what scaling is, the different types of scaling, and how to choose scaling strategies for your data pipelines.
2. What is scaling & why do we need it?
In this context, scaling refers to changing the number of machines or the size of the machine depending on the size of the data to be processed. Increasing the number of machines or the size of the machine is called scaling up, and decreasing them is called scaling down.
The main reasons for scaling up are to
- Increase the speed of data processing.
- Handle large input data.
Scaling down is done to keep costs low.
3. Types of scaling
There are two types of scaling
- Vertical scaling: Increasing memory and/or disk size of the data processing machine.
- Horizontal scaling: Using multiple processes to process a large data set.
- Independent processes: Used when independently processing multiple data sets in parallel. It involves one process per dataset.
- Distributed systems: Cluster of machines that operate as one unit to processes a data set.
Below is a comparison of the different scaling strategies.
| Vertical Scaling | Horizontal Scaling - Independent processes | Horizontal Scaling - Distributed systems | |
|---|---|---|---|
| Setup | Simple | Simple, if you are starting individual processes. If you are starting individual containers, you might need a service like Kubernetes, AWS Lambda, etc | Difficult to manage. Managed services that make this easier are available. |
| Autoscaling | No. Scaling requires a stop, scale, and restart. | Yes. Individual processes can be triggered asynchronously. Services like AWS Lambda make this much easier. | Yes, most OS (Spark, Flink) and vendor services (Snowflake) provides autoscaling support. |
| Data set size | Can handle data in the size of GBs. E.g. c5a.24xlarge has 192GB memory | Only bound by the individual processor size. Can handle data in the size of GBs. | Terabytes and above. |
| Example services | AWS EC2 | AWS Lambda, AWS EKS (Kubernetes), etc | AWS EMR (Apache Spark, Apache Flink), Snowflake, AWS Redshift, etc |
Cost depends on the type and number of machines used. You can estimate the cost using a cloud cost calculator.
Here is a representation of the different scaling strategies 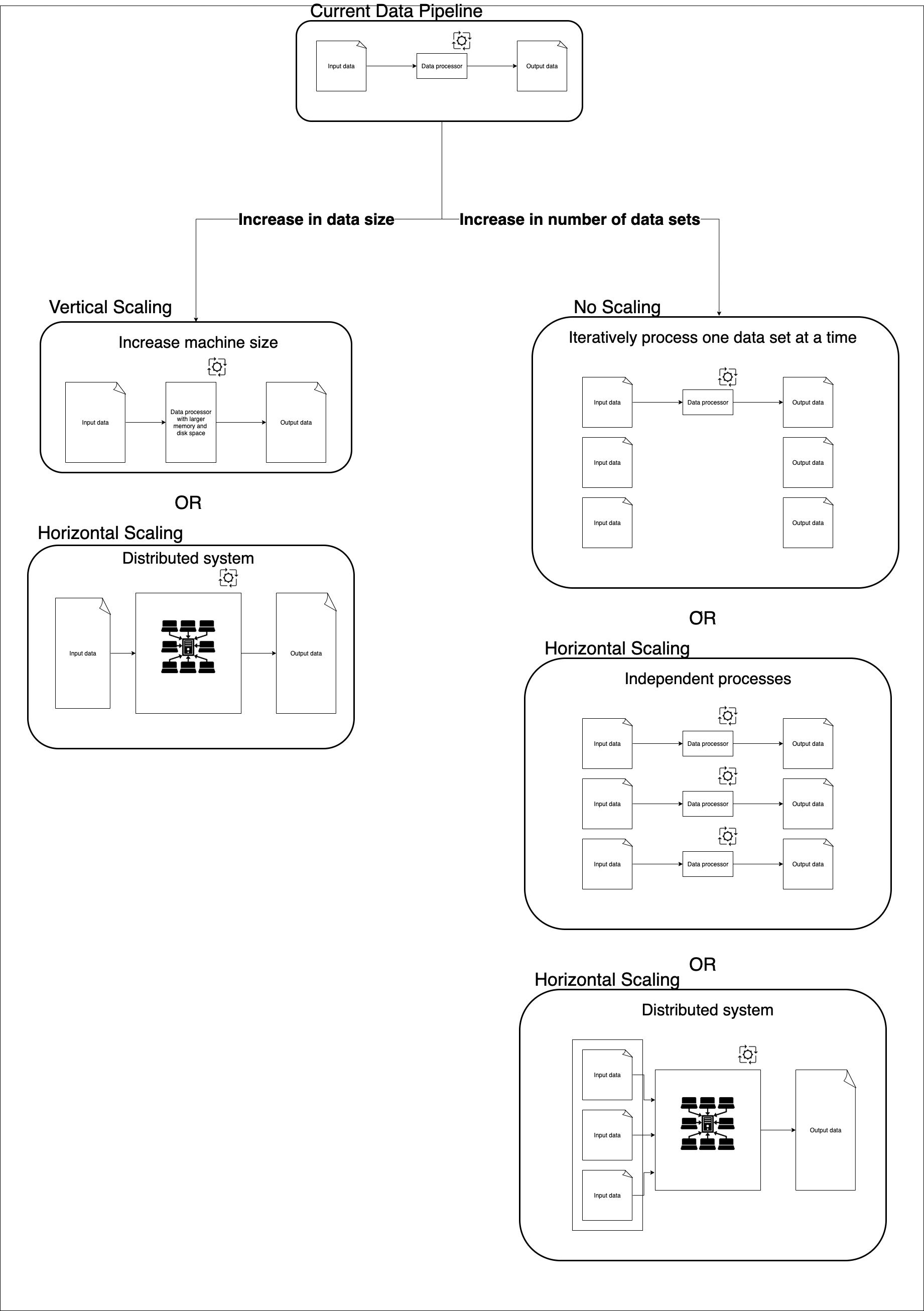
4. Choose your scaling strategy
The first step is to make sure that you need to scale. When processing a larger than memory data set, streaming through the rows and processing them may be sufficient for your use case.
Choosing the right scaling option depends on your data pipeline, data architecture, and organizational values. Use the following questions to come up with multiple possible solutions.
- Is increasing the machine size (vertical scaling) sufficient? Is it possible to get a large enough machine to process the input data? Note that some operations will not scale linearly with an increase in machine size, e.g.
cross join. - Can your data warehouse be leveraged to process this data? Is it possible to perform the transformations using SQL? Most data warehouse services also provide autoscaling. This is one reason why ELT is popular.
- Are there individual datasets that can be processed independently? Services like AWS lambda provide an easy and cheap way to autoscale your data pipelines.
- Does the data size, speed of processing, and complexity of transformation requirements necessitate setting up a Spark/Flink cluster? If you do not have a managed service, managing and optimizing a distributed system can be a lot of work.
Use the questions below to decide among the possible solutions.
- What are the costs (service cost, developer time cost, code complexity cost)? Are they justifiable for the performance gain?
- Is this an over optimization ?
- Can this strategy be used for other data pipelines in your company?
- Does code complexity increase or decrease?
- Is it possible to have a short-term(e.g. increase machine size) and long-term(e.g. independent processes for higher scalability) solution for this?
- Is it possible to combine multiple scaling strategies?
5. Conclusion
Hope this article gives you a good idea of scaling and how to scale your data pipelines. Scaling is a powerful concept to improve the health of your data pipelines, but premature optimization can lead to unnecessary code complexity. A good approach is to come up with multiple scaling strategies and eliminate most of them using the questions provided in this post.
As always, if you have any questions or comments, please feel free to leave them in the comments section below.