Introduction
If you are using a data warehouse, you would have heard of fact and dimension tables. Simply put, fact tables are used to record a business event and dimension tables are used to record the attributes of business items(eg user, item tables in an e-commerce app). This is also referred to as a star schema or dimension modeling.
For example, in an e-commerce website, a fact table would contain information about orders, such as when the order was placed, the items in that order, who placed that order, etc. The dimension tables would be an item table (containing item id, item price, size, etc) and an user table (containing user id, user name, user address etc).
If you are wondering
how can I store my table’s history over time ?
how can I join a fact table and an SCD2 dimension table ?
Then this post is for you. For a detailed explanation of what a data warehouse is, checkout this article.
What is an SCD2 table and why use it?
The dimensional data in a data warehouse are usually derived from an application’s database. There are 7 common types of ways to model and store dimensional data in a data warehouse. In this post, we will look exclusively at Type 2: Add New Row.
SCD2 stands for slowly changing dimension type 2. In this type, we create a new row for each change to an existing record in the corresponding transaction table. Each row in the SCD2 dimension table will have row effective and row expiration datetime columns to denote the range within which that row represents the state of the data.
Application table
Assume in our e-commerce applications database that we have a user table to store user attributes.
| user | column definition |
|---|---|
| user_id | unique identifier for a user (primary key) |
| first_name | first name of the user |
| last_name | last name of the user |
| address | address of the user |
| zipcode | zipcode of the user |
| created_datetime | Date and time when the user was created |
| updated_datetime | Date and time when this user data was last modified |
Let’s say that a user with user_id=b0cc9fde-a29a-498e-824f-e52399991beb has a zip code of 10027 until 2020-12-31, after which, the user changes address and the new zip code is 10012. In our application table, this would mean that the record with user_id=b0cc9fde-a29a-498e-824f-e52399991beb now has a zip code of 10012.
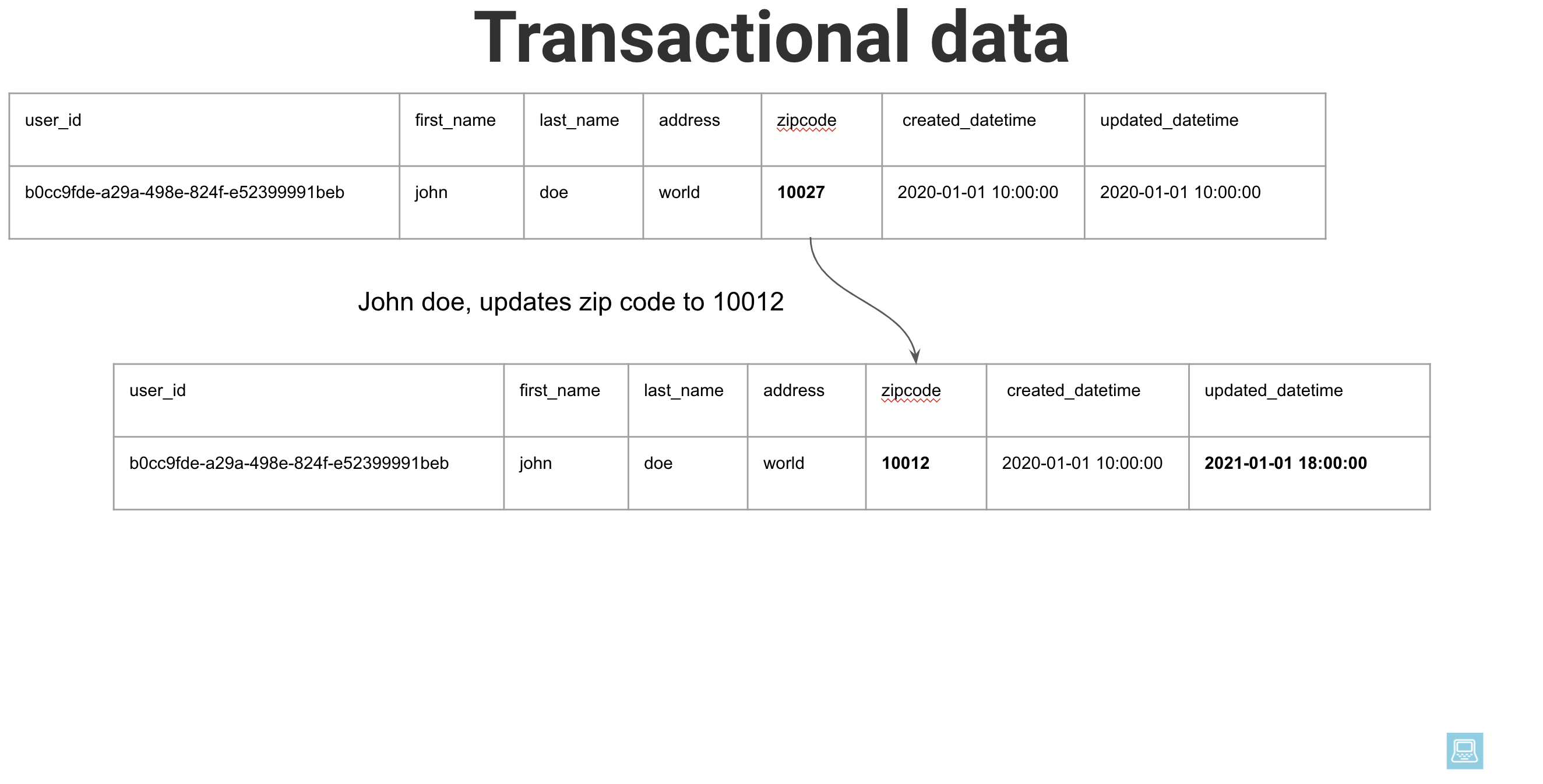
Dimension table
In the data warehouse, we need to ensure that we have access to historical data to run historical analyses. For example, if an end user want to check how many of our users lived in the zip code 10027 for the month of Dec 2020, we need to make sure that the user with user_id=b0cc9fde-a29a-498e-824f-e52399991beb is counted towards 10027 and not 10012, because that is where that user was, as of December 2020.
To store this historically changing data in our data warehouse, we create a new row for each change. Let’s consider our user_dim(user dimension) table in our data warehouse. This corresponds to the user table in our application database.
| user_dim | column definition |
|---|---|
| user_id | unique identifier for a user (primary key) |
| first_name | first name of the user |
| last_name | last name of the user |
| address | address of the user |
| zipcode | zipcode of the user |
| created_datetime | Date and time when the user was created |
| updated_datetime | Date and time when this user data was last modified |
| row_effective_datetime | The date and time from which this row is the effective data for this user_id |
| row_expiration_datetime | The date and time until which this row is the effective data for this user_id |
| current_row_indicator | Indicator denoting if this row is the most current state of the data for this user_id |
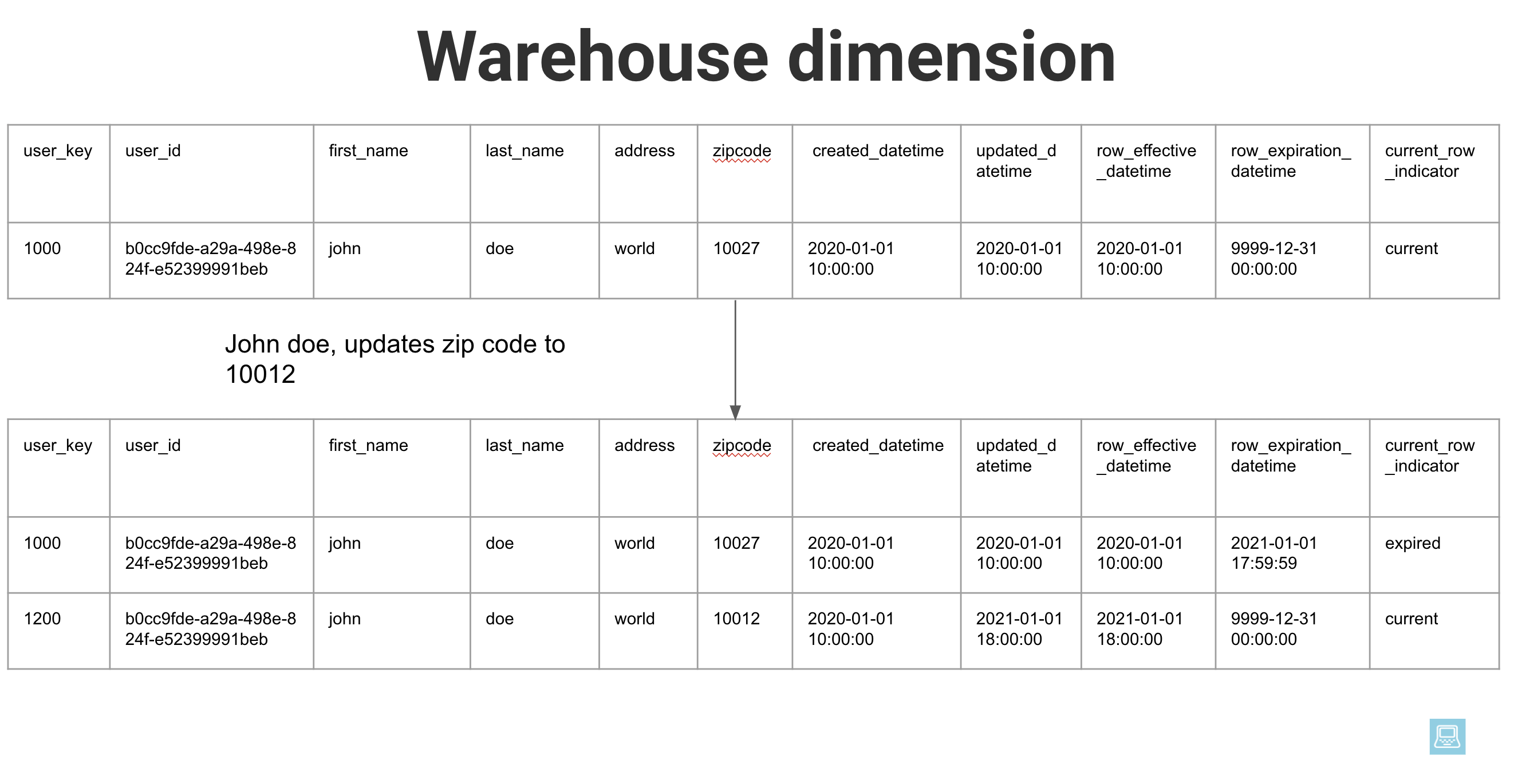
We do not update the value of an existing row, but we add a new record to indicate the new state. We also set the old record’s row_expiration_datetime and set current_row_indicator to expired.
For the new record, we set the updated_datetime as row_effective_datetime and set end of time as row_expiration_datetime and set current for current_row_indicator to reflect the current state. # Setup
We will use PostgreSQL on a docker container for our data warehouse and pgcli to connect to it.
From your terminal, run
Now, login to the running postgres instance as shown below. The password is password
Let’s create a simple user_dim table and an items_purchased fact table in our data warehouse.
CREATE DATABASE warehouse;
USE warehouse;
DROP TABLE IF EXISTS user_dim;
CREATE TABLE user_dim (
user_key BIGINT,
user_id VARCHAR(40),
first_name VARCHAR(10),
last_name VARCHAR(10),
address VARCHAR(100),
zipcode VARCHAR(10),
created_datetime TIMESTAMP,
updated_datetime TIMESTAMP,
row_effective_datetime TIMESTAMP,
row_expiration_datetime TIMESTAMP,
current_row_indicator VARCHAR(10)
);
INSERT INTO user_dim (
user_key,
user_id,
first_name,
last_name,
address,
zipcode,
created_datetime,
updated_datetime,
row_effective_datetime,
row_expiration_datetime,
current_row_indicator
)
VALUES (
1000,
'b0cc9fde-a29a-498e-824f-e52399991beb',
'john',
'doe',
'world',
10027,
'2020-01-01 10:00:00',
'2020-01-01 10:00:00',
' 2020-01-01 10:00:00',
'2021-01-01 17:59:59',
'expired'
),
(
1200,
'b0cc9fde-a29a-498e-824f-e52399991beb',
'john',
'doe',
'world',
10012,
'2020-01-01 10:00:00',
'2021-01-01 18:00:00',
'2021-01-01 18:00:00',
'9999-12-31 00:00:00',
'current'
);
DROP TABLE IF EXISTS items_purchased;
CREATE TABLE items_purchased (
item_purchased_id VARCHAR(40),
order_id VARCHAR(40),
user_id VARCHAR(40),
item_id VARCHAR(40),
item_cost decimal(10, 2),
purchased_datetime TIMESTAMP -- and other fact information
);
INSERT INTO items_purchased (
item_purchased_id,
order_id,
user_id,
item_id,
item_cost,
purchased_datetime
)
VALUES (
'nljbac724bbskd',
'order_id_1',
'b0cc9fde-a29a-498e-824f-e52399991beb',
'item_id_1',
1500.00,
'2020-12-28 12:30:00'
),
(
'ljbkcfvbj6758njh',
'order_id_23',
'b0cc9fde-a29a-498e-824f-e52399991beb',
'item_id_45',
20.00,
'2021-01-28 09:30:00'
),
(
'sjbv09uy7njhbvvj',
'order_id_100',
'11111111-2222-3333-44444444444',
'item_id_12',
32.00,
'2021-02-01 11:00:00'
);We now have an items_purchased fact table and a user_dim dimension table, with some sample data.
Joining fact and SCD2 tables
Let’s say our data analysts wants to answer questions like
- I want to see the distribution of our high spending users by month, year and zip code(at time of purchase)
- I want to see the high spending users first name, last name, zip code along with how long they lived at each zip code(
duration_of_stay). If they are currently living at a zip code then theduration_of_stayshould beNull.
High spending user is defined as any user who has spent at least 1000$ on our website.
We can write a query to answer question 1, as shown below
WITH high_spenders AS (
SELECT user_id
FROM items_purchased
GROUP BY user_id
HAVING sum(item_cost) > 1000
),
user_items AS (
SELECT ip.item_purchased_id,
ip.user_id,
ip.item_cost,
ud.zipcode,
ip.purchased_datetime
FROM items_purchased ip
JOIN user_dim ud ON ip.user_id = ud.user_id
AND ip.purchased_datetime BETWEEN ud.row_effective_datetime AND ud.row_expiration_datetime
)
SELECT EXTRACT(
YEAR
FROM ui.purchased_datetime
) yr,
EXTRACT(
MONTH
FROM ui.purchased_datetime
) mnth,
ui.zipcode,
COUNT(DISTINCT ui.user_id) num_high_spenders
FROM user_items ui
JOIN high_spenders hs ON ui.user_id = hs.user_id
GROUP BY yr,
mnth,
ui.zipcode
ORDER BY yr DESC,
mnth DESC;Let’s look at each of the individual CTEs, high_spenders and user_items.
high_spenders

We can see that the user with user_id=b0cc9fde-a29a-498e-824f-e52399991beb is a high spender, because they spent a total of 1520.00 during their entire time in our application.
user_items
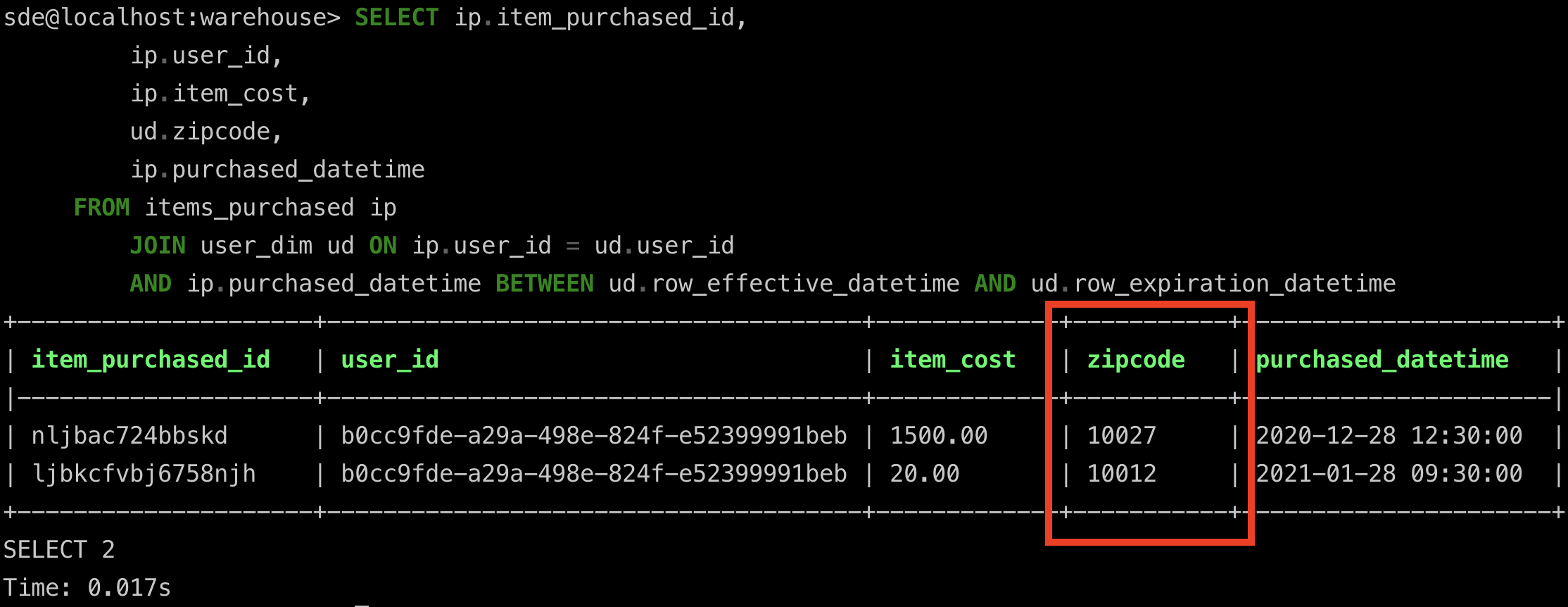
We can see how the user with user_id=b0cc9fde-a29a-498e-824f-e52399991beb is associated with the zip code of 10027 for purchases made in the month of December 2020 and zip code of 10012 for purchases made in the month of January 2021.
The fact to SCD2 dimension table join happens in the user_items CTE.

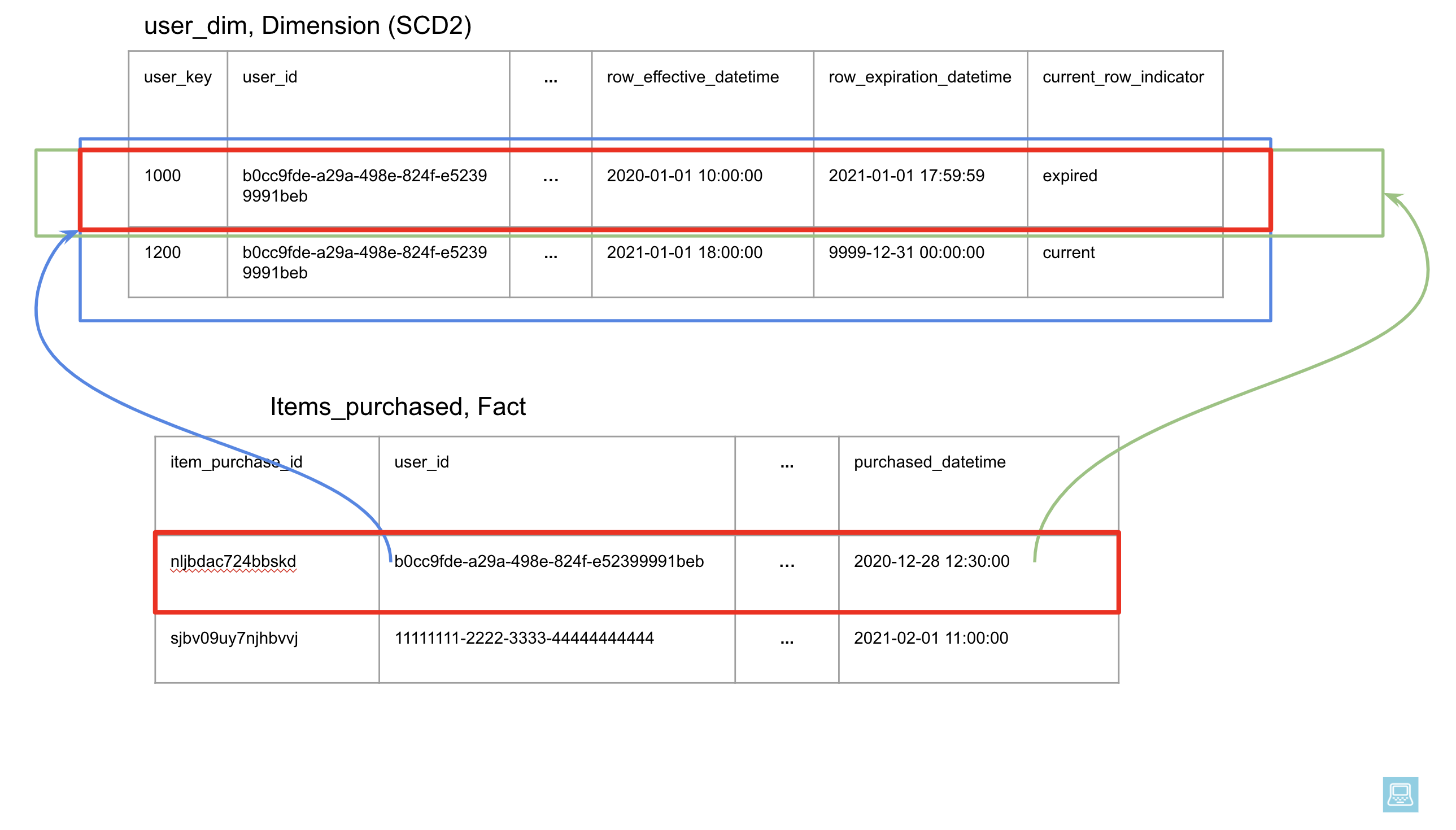
We know that for any given row in the user_dim table, the row_effective_datetime and row_expiration_datetime define the ranges between which the row represents the state of data at that point in time.
This enables us to uniquely join a row in the fact table to the state of the user at the time the purchase was made.
The distribution of our high spending users by month, year, and zip code, will be as shown below.
| yr | mnth | zipcode | num_high_spenders |
|---|---|---|---|
| 2021.0 | 1.0 | 10012 | 1 |
| 2020.0 | 12.0 | 10027 | 1 |
Answering question number 2 is left as an exercise for the reader. Comment your answers in the comment section below to check the implementation.
To stop and remove the docker containers, run
Educating end users
When using a slowly changing dimension, it is crucial to educate the end user on how to use the data. You can try to encapsulate its complexity by creating a view or a function on top of your slowly changing dimension table. However ultimately, any users of data should be aware of what SCD2 is, how to use, and how not to use them.
Conclusion
Hope this article gave you a good understanding of how to join fact tables with SCD2 dimension tables to get point in time information. Most end user questions arise from the inability to have point in time information which makes the results of their queries inaccurate and confusing.
The next time you are modeling a dimension table in your data warehouse, try SCD2 to store historical changes that will be required for running analytical queries later.
Further reading
- Common Table Expressions (CTEs)
- What is a data warehouse
- Mastering window functions
- DBT support for SCD2
References: