Introduction
Loading data into a data warehouse is a key component of most data pipelines. If you are wondering
How to handle SQL loads
What are the patterns used to load data into a data warehouse?
Then this post is for you. In this post, we go over 4 key patterns to load data into a data warehouse. Data pipelines typically tend to use one or a combination of the patterns shown below. Recognizing these patterns can help you design better data pipelines and understand existing data pipelines.
Patterns
1. Batch Data Pipelines
These are data pipelines that run with a scheduled interval of at least 5 minutes or more.
1.1 Process => Data Warehouse
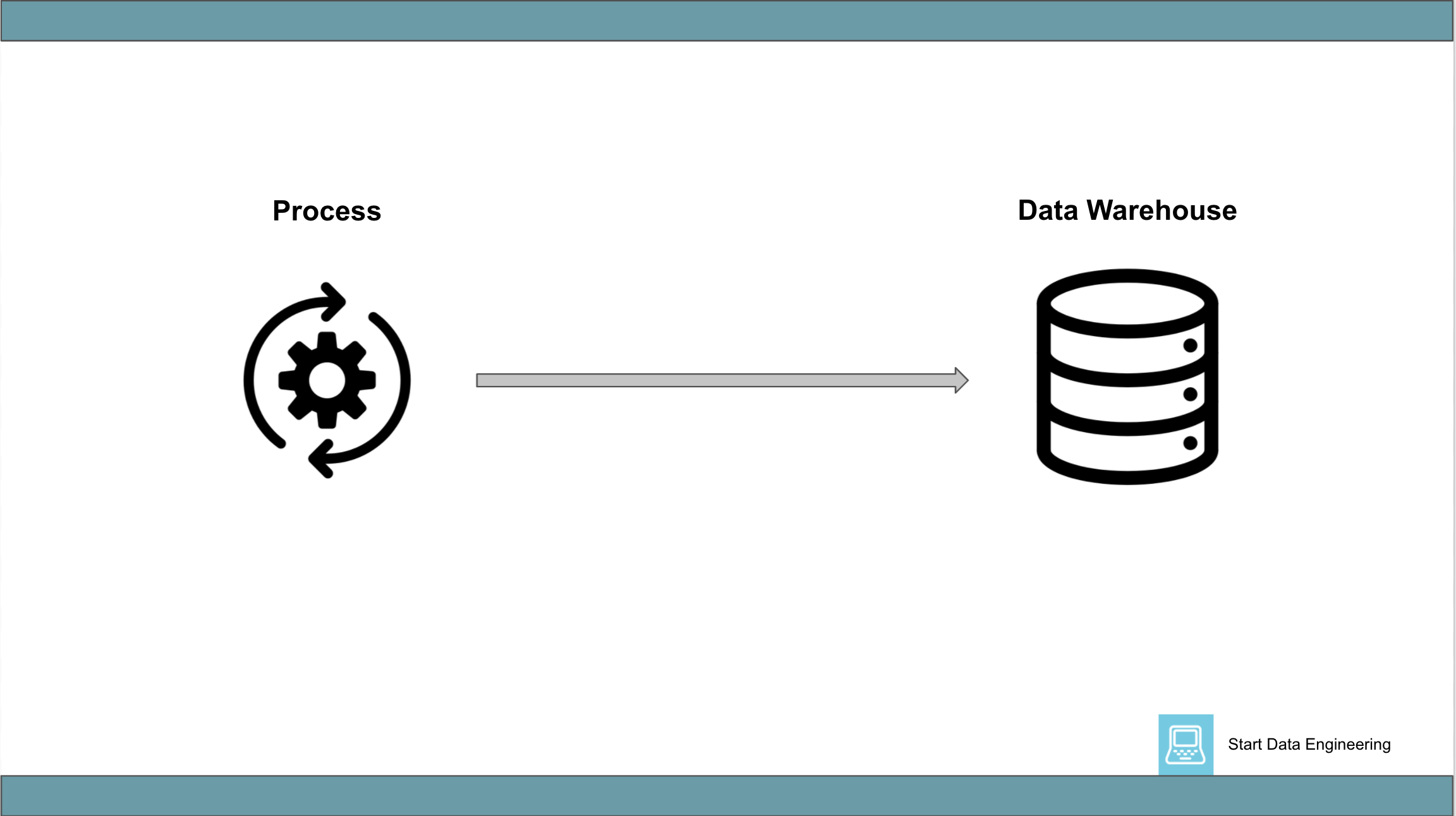
This generally involves a single process that extracts data from some source and loads it into a data warehouse. The number of network round trips to the data warehouse should be kept low by batching together multiple (or all, if process memory allows) inserts into a single insert-database call (ie micro/mini batching).
For example, if you are using python and Postgres (as a data warehouse) you might use execute_values to insert multiple rows with one network call.
Pros:
- Simple to set up, run, monitor, and debug.
- Large machines can handle a significant amount of data.
Cons:
- Does not scale beyond a single machine. This will become an issue if your data size is very large.
- Inserts into the data warehouse will be a bottleneck. This can be mitigated by running multiple processes in parallel. However, this can introduce incorrect ordering of inserts, if not careful.
1.2 Process => Cloud Storage => Data Warehouse
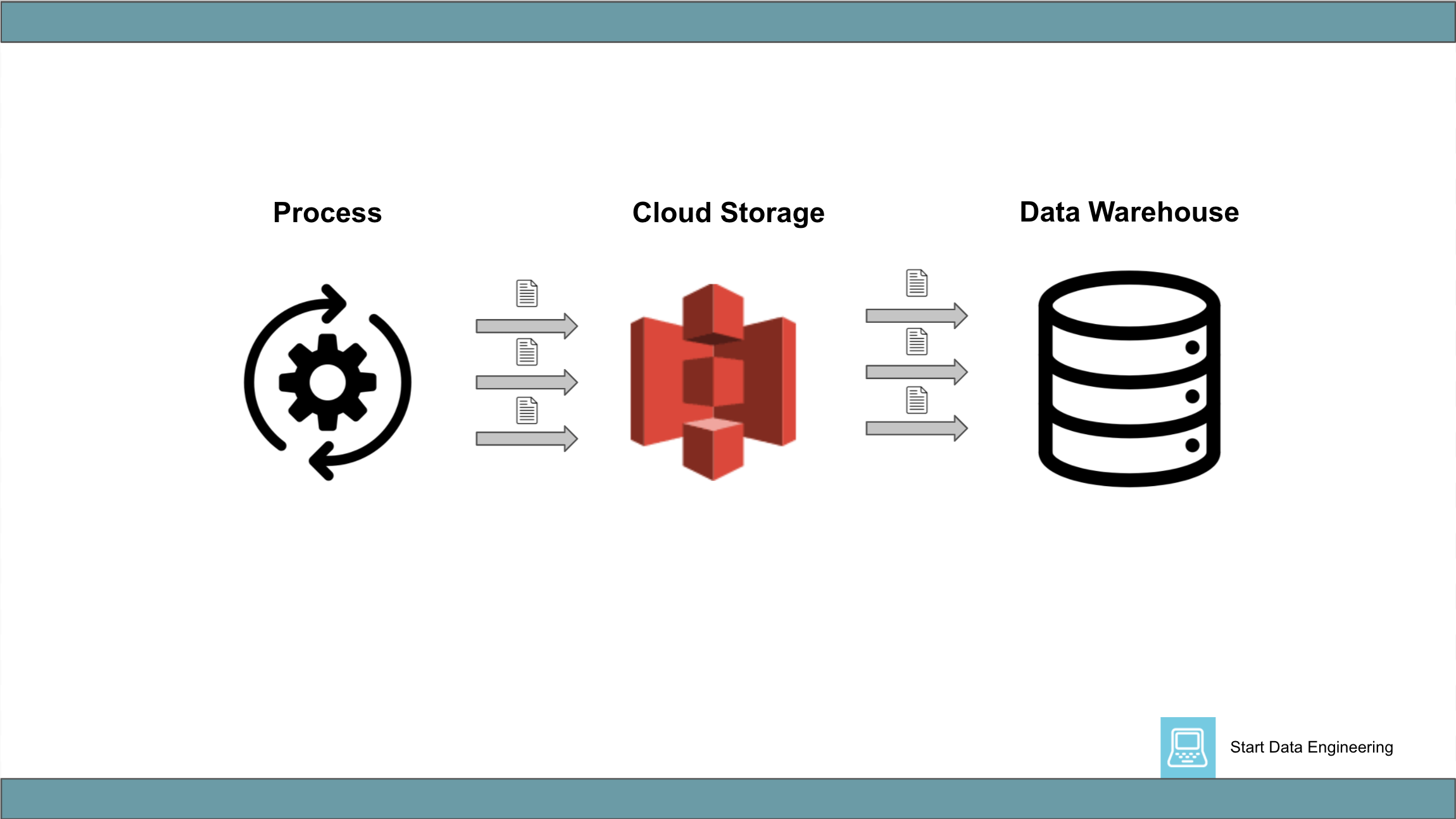
This generally involves a distributed process (sometimes a single process) that writes data in parallel to a cloud storage system. This is then followed by a process to COPY the data in parallel from the cloud storage system into a data warehouse.
Some data warehouses support external tables, which enable reading data directly from S3. This will remove the need to run the COPY command.
Pros:
- Can load very large amounts of data.
- Writing to a cloud storage system and inserting it into a data warehouse are parallelized, making this approach fast.
Cons:
- Managing a distributed systems cluster can be expensive.
- With external tables, new partitions can require running an
ALTER TABLE ADD PARTITIONcommand.
2. Near Real-Time Data pipelines
These are data pipelines that are constantly running. Typically the time between data generation and its availability in the data warehouse will be less than a minute. Eg) A data pipeline to ingest clicks, impressions from a website into a data warehouse.
2.1 Data Stream => Consumer => Data Warehouse
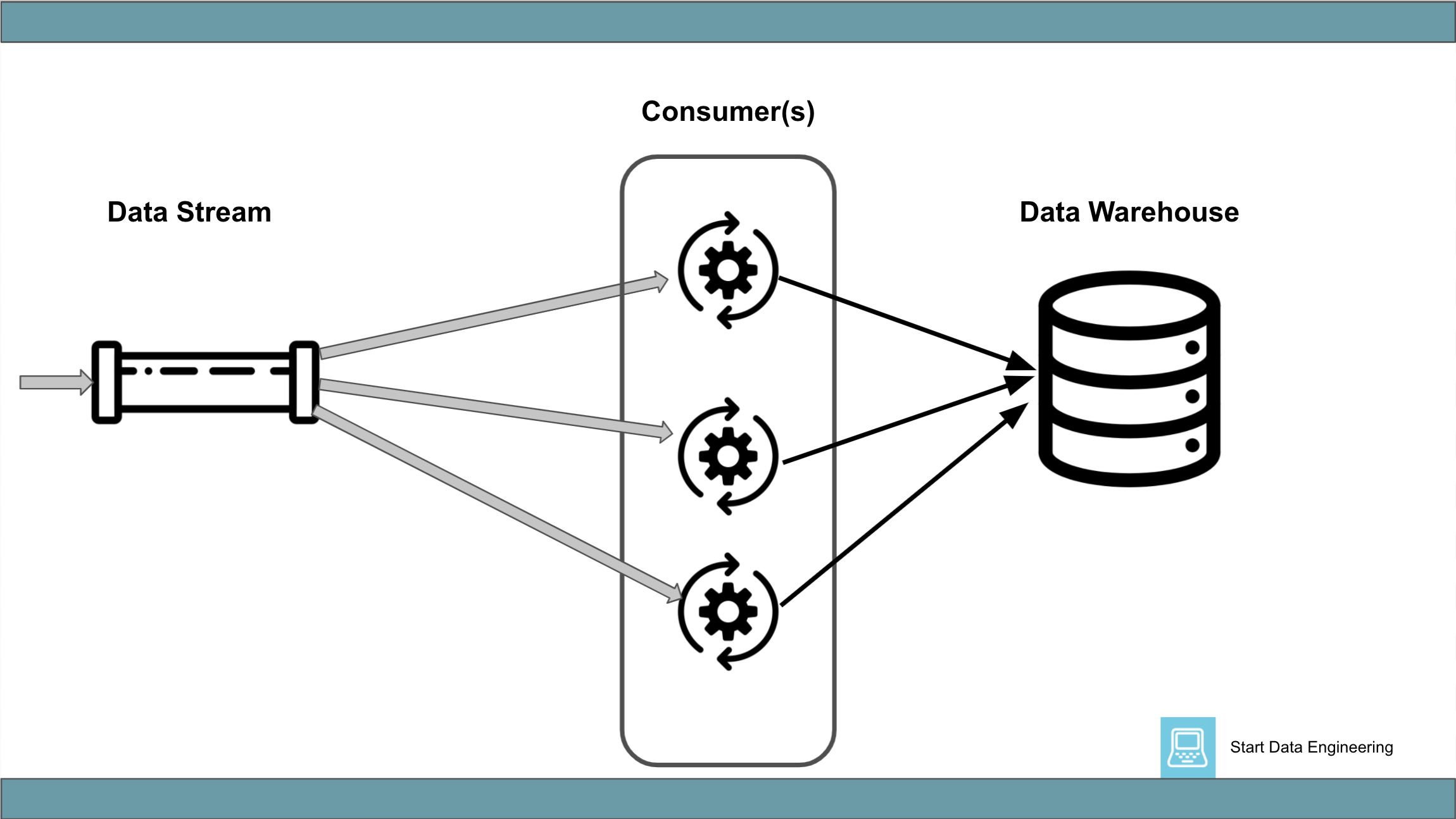
This generally involves a data stream (being fed by another process) and a consumer of this data stream. The consumer process consumes records, performs data enrichment (optional), collects a batch of records in memory, and inserts it into a data warehouse.
Note: Some projects like ksqldb and clickhouse lets you directly query data in a Kafka topic. These are however not substitutes for a data warehouse.
Pros:
- Wide range of ready use connectors.
- Most data warehouses have established connectors (e.g. Snowflake Kafka Connector).
- The consumer can be parallelized easily with consumer groups.
Cons:
- Pay close attention to at least once insertion semantics, as required by your system.
- With multiple consumers inserting data into a data warehouse, the order of insertion is not guaranteed to be the same as it enters the data stream. You will need to handle this carefully if needed. Ref: Message ordering in Kafka.
2.2 Cloud Storage => process => Data Warehouse
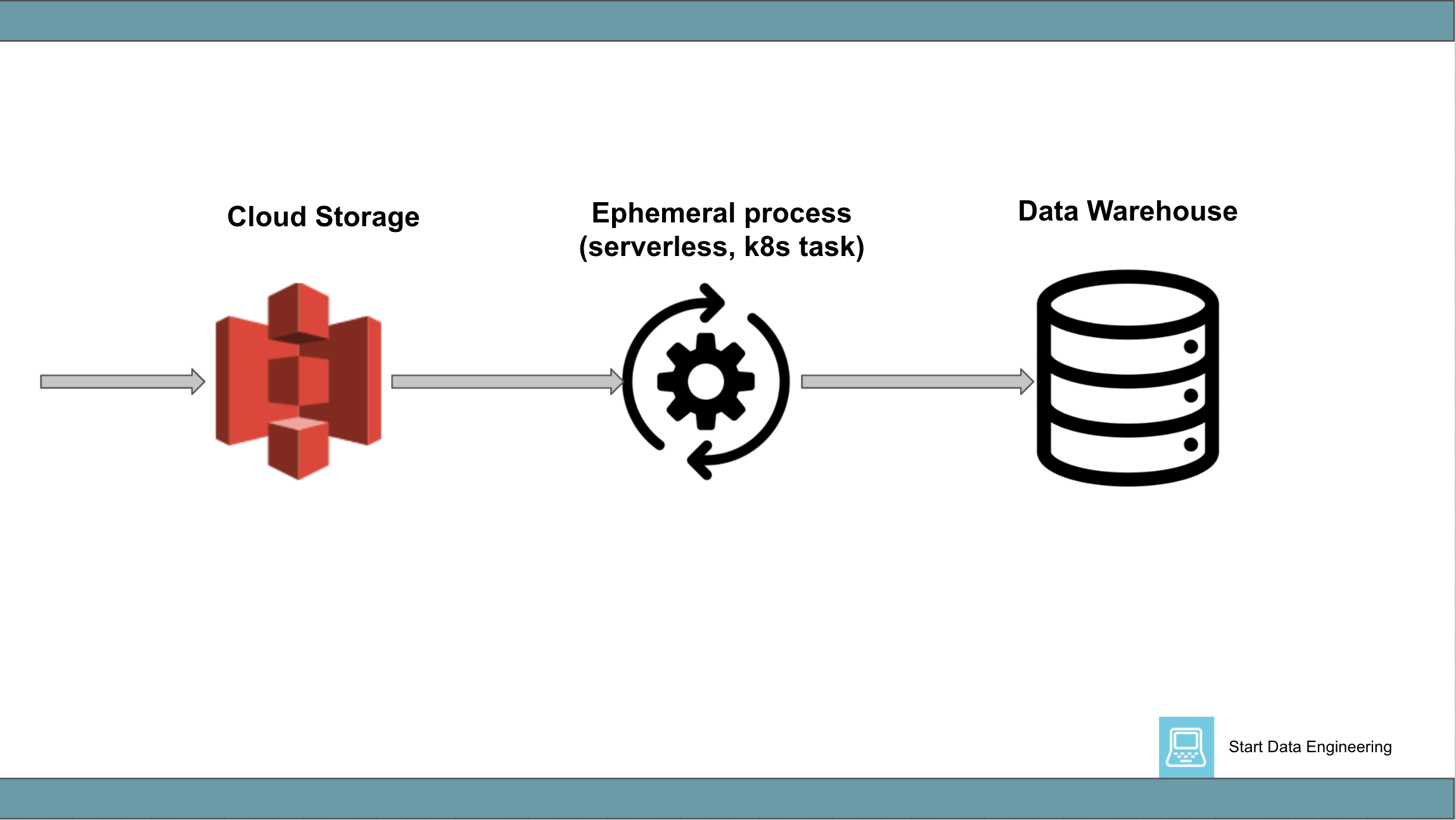
This generally involves data (usually a small batch of rows) landing in a cloud storage system (being fed by another process) and a monitoring system that detects this and triggers a process to insert that data into a data warehouse.
For example, you might set up an s3 trigger to start a lambda process to insert the data into a data warehouse, when data lands in S3.
Pros:
- Most cloud service providers have support to monitor their cloud storage system and trigger a process (usually called serverless).
- Some data warehouses also support this patter (e.g. Snowpipe).
- The raw data stored in the cloud storage system provides additional data redundancy.
Cons:
- Pay close attention to limits on the number of processes that can be triggered, during high traffic.
- With multiple processes inserting data into a data warehouse, the order of insertion is not guaranteed to be the same as it lands in the cloud storage system. You will need to handle this carefully if needed.
Conclusion
Hope this article gives you a good idea of the general patterns that are used to load data into a data warehouse. In most cases, one or a combination of the above patterns is used.
The next time you are building a pipeline to load data into a data warehouse, try one of these loading patterns. You will be surprised by how most tools, cloud providers, and orchestration frameworks support and promote these patterns.
If you have used another pattern or have any questions or comments please leave them in the comments section below.