1. Introduction
If you are a student, analyst, engineer, or anyone in the data space, it’s important to understand what a data warehouse is. If you are wondering
What is a data warehouse?
When should I start using a data warehouse?
Then this post is for you. By the end of this post, you will have understood what a data warehouse is, what type of databases can be used as a data warehouse, and how to choose the right data warehouse for your use case.
2. Business requirements: dashboards and analytics
Let’s assume you work for an e-commerce company where the merchant can list their items and customers can purchase them. Let’s assume we have two microservices, that handle customers and merchants respectively.
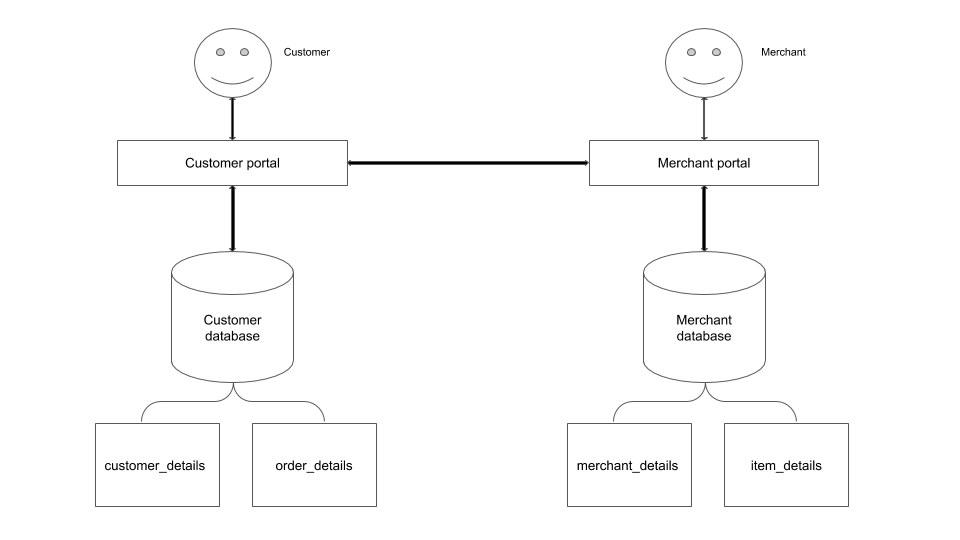
As our company grows, we may want to analyze data for various business goals. Merchants will also want to analyze performance and trends to optimize their inventory. Some of the questions and feature requests may be
- Get the 10 merchants, who have sold the most items?
- What is the average time for an order to be fulfilled?
- Identify the customers who purchased the same/similar items together.
- Create a merchant dashboard that shows the top-performing items per merchant
These questions ask about things that happened in the past, require reading a large amount of data, and aggregating data to get a result. These questions can be answered by querying a data warehouse.
3. What is a data warehouse
A data warehouse is a database that has all your company’s historical data and is used to run analytical queries. In our example, we cannot analyze item and merchant data in one database. We need to bring both of the datasets into our data warehouse, as shown below.
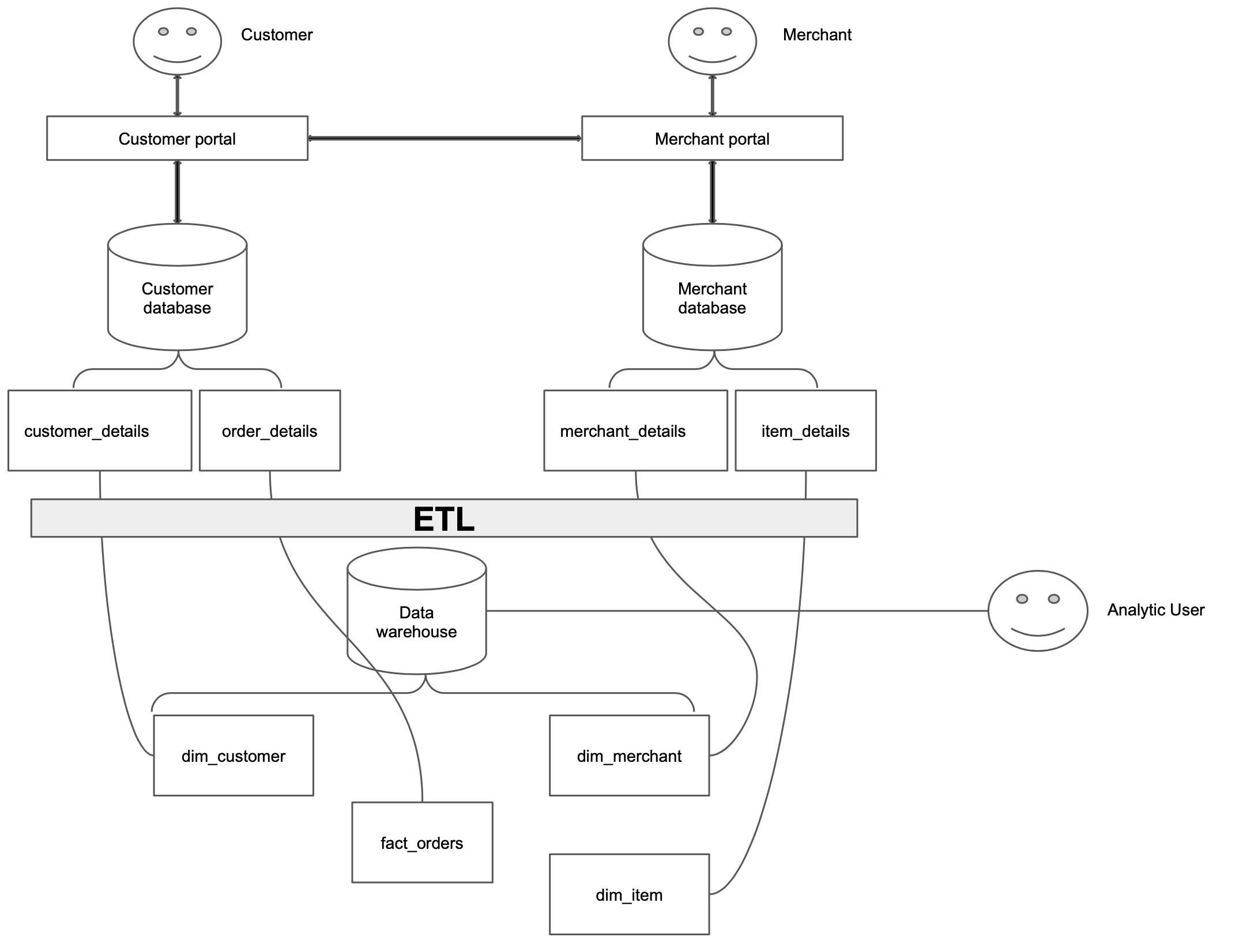
There are multiple design patterns for data warehouses, a few popular ones are
- Dimensional modeling - Kimball
- Data vault - Linstedt
- Data mart
- Flat table
In our data flow diagram, we have fct_* and dim_* models. These follow Kimball’s dimensional modeling.
Depending on the size of your data, using the application database for analytical queries may be perfectly valid. You can also have a read replica of your application database and run analytical queries on it to not affect application performance.
4. OLTP vs OLAP based data warehouses
There are two main types of databases: OLTP and OLAP. Their differences are shown below.
| OLTP | OLAP | |
|---|---|---|
| Stands for | Online transaction processing | Online analytical processing |
| Usage pattern | Optimized for fast CRUD(create, read, update, delete) of a small number of rows | Optimized for running select c1, c2, sum(c3),.. where .. group by on a large number of rows (aka analytical queries), and ingesting large amounts of data via bulk import or event stream |
| Storage type | Row oriented | Column-oriented |
| Data modeling | Data modeling is based on normalization | Data modeling is based on denormalization. Some popular ones are dimensional modeling and data vaults |
| Data state | Represents current state of the data | Contains historical events that have already happened |
| Data size | Gigabytes to Terabytes | Terabytes and above |
| Example database | MySQL, Postgres, etc | Clickhouse, AWS Redshift, Snowflake, GCP Bigquery, etc |
The major improvement in analytical queries on OLAP is due to its column store technique. Let’s consider a table items, with the data shown below.
| item_id | item_name | item_type | item_price | datetime_created | datetime_updated |
|---|---|---|---|---|---|
| 1 | item_1 | gaming | 10 | ‘2021-10-02 00:00:00’ | ‘2021-11-02 13:00:00’ |
| 2 | item_2 | gaming | 20 | ‘2021-10-02 01:00:00’ | ‘2021-11-02 14:00:00’ |
| 3 | item_3 | biking | 30 | ‘2021-10-02 02:00:00’ | ‘2021-11-02 15:00:00’ |
| 4 | item_4 | surfing | 40 | ‘2021-10-02 03:00:00’ | ‘2021-11-02 16:00:00’ |
| 5 | item_5 | biking | 50 | ‘2021-10-02 04:00:00’ | ‘2021-11-02 17:00:00’ |
Let’s see how this table will be stored in a row and column-oriented storage. Data will be stored as pages (group of records) on the disk.
Row oriented storage:
Let’s assume that there is one row per page.
Page 1: [1,item_1,gaming,10,'2021-10-02 00:00:00','2021-11-02 13:00:00'],
Page 2: [2,item_2,gaming,20,'2021-10-02 01:00:00','2021-11-02 14:00:00']
Page 3: [3,item_3,biking,30, '2021-10-02 02:00:00','2021-11-02 15:00:00'],
Page 4: [4,item_4,surfing,40, '2021-10-02 03:00:00','2021-11-02 16:00:00'],
Page 5: [5,item_5,biking,50, '2021-10-02 04:00:00','2021-11-02 17:00:00']Column-oriented storage:
Let’s assume that there is one column per page.
Page 1: [1,2,3,4,5],
Page 2: [item_1,item_2,item_3,item_4,item_5],
Page 3: [gaming,gaming,biking,surfing,biking],
Page 4: [10,20,30,40,50],
Page 5: ['2021-10-02 00:00:00','2021-10-02 01:00:00','2021-10-02 02:00:00','2021-10-02 03:00:00','2021-10-02 04:00:00'],
Page 6: ['2021-11-02 13:00:00','2021-11-02 14:00:00','2021-11-02 15:00:00','2021-11-02 16:00:00','2021-11-02 17:00:00']Let’s see how a simple analytical query will be executed.
In a row-oriented database
- All the pages will need to be loaded into memory
- Sum
pricecolumn for sameitem_typevalues
In a column-oriented database
- Only pages 3 and 4 will need to be loaded into memory
- Sum
pricecolumn for sameitem_typevalues
As you can see from this approach, we only need to read 2 pages in a column-oriented database vs 5 pages in a row-oriented database. In addition to this, a column-oriented database also provides
- Better compression, as similar data types are next to each other and can be compressed more efficiently.
- Vectorized processing
All of these features make a column-oriented database a great choice for storing and analyzing large amounts of data.
5. Conclusion
To recap, we saw
- What a data warehouse is.
- The business requirements for a data warehouse.
- Differences between using OLTP and an OLAP database as a data warehouse.
When choosing a data warehouse, it is always a good idea to choose one that is the best fit to handle the amount of data that you estimate to have in your data warehouse. E.g. choosing an expensive OLAP data warehouse when you only have a few GBs of data will not be the best choice.
The next time you are choosing a data warehouse, use this comparison table to make the right decision for your use case.
If you have any questions or comments, please leave them in the comment section below.