1. Introduction
If you are building data pipelines from the ground up, the number of available data engineering tools to choose from can be overwhelming. If you are thinking
Most of the tools seem to be doing the same/similar thing, which one should I choose?
How to choose the right tool for my data pipeline?
Then this post is for you. In this post, we go over the core components of data pipelines and how you can use your requirements to select the right tools.
We will go over
- Gathering requirements
- Identifying components of your data pipeline
- Shortlisting tools
- Filtering tool choices based on your use case
Note: In this post we use the term tool to denote programming language, library, framework, SAAS, cloud resource.
2. Requirements
Understanding the requirements of data pipelines helps in designing your data pipeline and choosing the right tool.
| Requirement | Questions to ask | Usual choices |
|---|---|---|
Real-time or Batch |
Do you need data processed continuously or on a schedule (usually with frequency > 10m)?. | {Batch, Stream} |
Data size |
What is the size of data to be processed per run? | {Batch: {MB, GB, TB, PB}, Stream: {records per second * size per record}} |
Pipeline frequency |
How frequently do you want the pipeline to run? This typically applies to batch pipelines. | {minutes, hours, days, months} |
Data processing speed |
How quickly do you want the data to be processed? This should be lower than the pipeline frequency to prevent clogging your compute resources. |
{seconds, minutes, hours} |
Latency requirements |
What is an acceptable wait time for an end-user querying your destination system? Typically measured using mean & 95th percentile values. | {5ms, 1s, 10s, 1min, 10min, 30min} |
Query patterns |
What types of queries will be run by the end-user? | {analytical, full text search, NoSQL, transactional, graph-based, combination} |
3. Components
With the requirements defined, you can design the data pipeline. Identify the components that make up your data pipeline.
| Component | Responsibility | Examples |
|---|---|---|
Scheduler |
Starting data pipelines at their scheduled frequency. | Airflow scheduler, cron, dbt cloud, etc |
Executor |
Running the data processing code. The executor can also call out other services to process the data. | python, data warehouse, Spark, k8s, dbt, etc |
Orchestrator |
Ensuring that the data pipeline tasks are executed in the right order, retrying on failures, storing metadata, and displaying progress via UI. | Airflow, Prefect, Dagster, dbt |
Source |
System where data is to be read from. | OLTP databases, cloud storage, SFTP/FTP servers, REST APIs, etc |
Destination |
Making data available for the end-user. | data warehouses, Elastic search, NoSQL, CSV files, etc |
Visualization/BI tool |
Enabling business users to look at data patterns and build shareable dashboards. | Looker, Tableau, Apache Superset, Metabase, etc |
Queue |
Accepting continuously incoming data (aka streaming) and making it available for the consuming system to read from. | Kafka, Pulsar, AWS Kinesis, Nats, RabbitMQ, etc |
Event triggers |
Triggering an action in response to a defined event occurring. | AWS lambda triggers, Watchdog, etc |
Monitoring & Alerting |
Continuously monitoring data pipelines and alerting in case of breakage or delay. | Datadog, Newrelic, Grafana, |
Data quality check |
Checking if data confines to your expectations. | custom scripts checking for data constraints & business rules, Great expectations, dbt tests, etc |
4. Choosing tools
After collecting requirements and identifying the components of your data pipeline you can use the below framework to identify tools that might be a good fit.
4.1 Requirement x Component framework
This involves creating a table with a list of all your components and requirements (as rows and columns) and filling them out with tools that can satisfy the requirement.
E.g. Let’s consider a data pipeline, where you pull data from 2 databases, join them and make them available for the end-user. The end-user usually joins this data with a large fact table that is in the data warehouse. The data should be made available every hour.
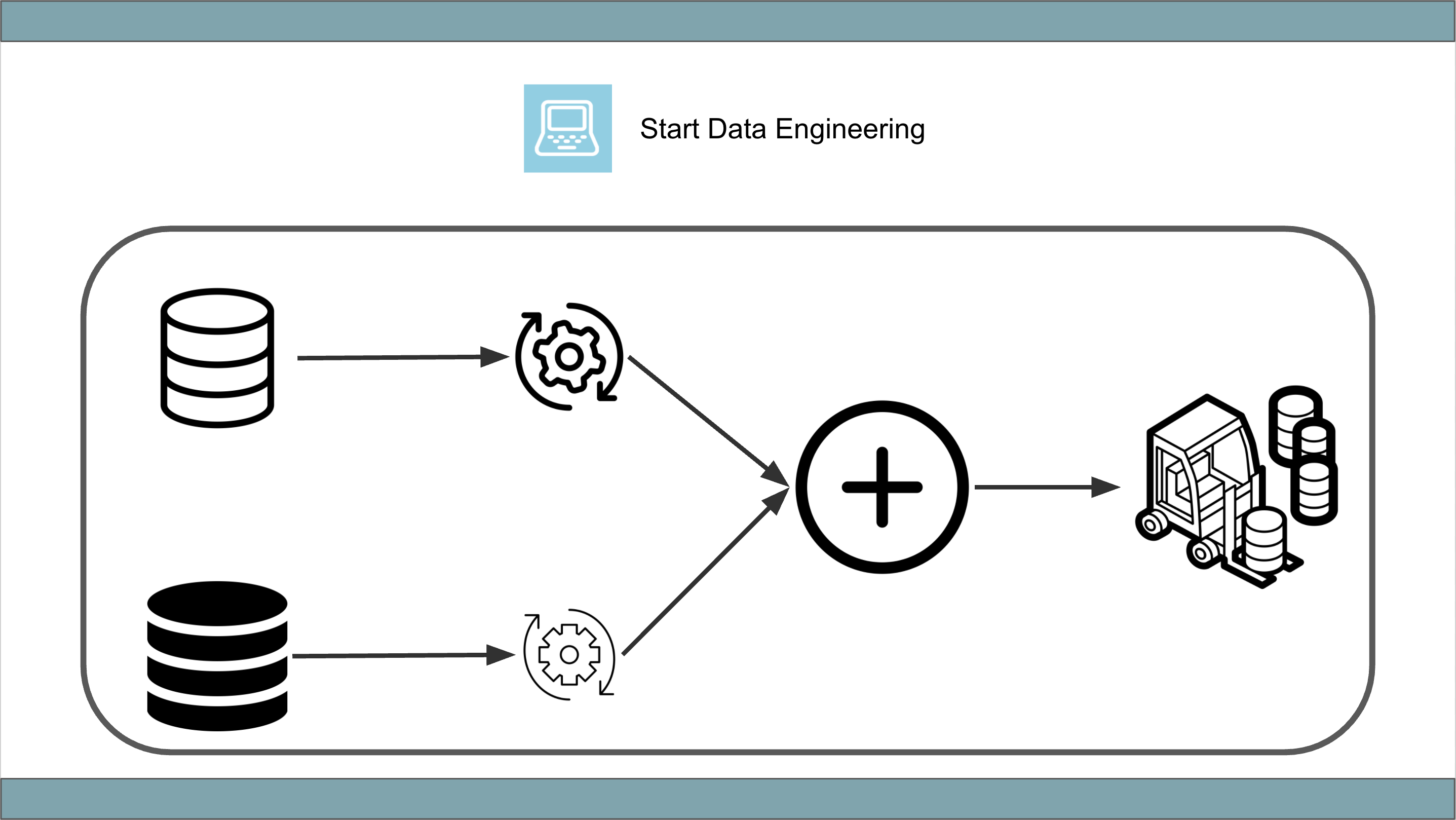
Let’s note down the components and note down some tools that can potentially meet our requirements.
Note that an missing fields in the table below denotes that a specific requirement does not apply to the corresponding component. For example, A requirement of sub 10s latency on the Latency requirement does not affect the Orchestrator component.
| Requirement | Source | Orchestrator | Scheduler | Executor | Destination | Monitor & Alert |
|---|---|---|---|---|---|---|
| Batch w Pipeline Frequency: 1h | - | Airflow (MWAA, Astronomer, Cloud composer), dbt, Dagster, Prefect, custom python | Airflow, dbt cloud, Databricks scheduler, Dagster, Prefect, cron | - | - | custom alerts, Datadog, newrelic, AWS cloudwatch, |
| Data Size: 10GB | - | - | - | Python, Airflow worker, k8s pod, Spark, Snowflake, Redshift, Dask, Databricks, AWS EMR, | - | papertrail, datadog, newrelic |
| Data processing speed: <=10m | - | - | - | Python, Airflow operator, k8s pod, Spark, Snowflake, Redshift, Databricks, AWS EMR, | - | papertrail, datadog, newrelic |
| Query pattern: Analytical | - | - | - | - | Data warehouse, Redshift, Snowflake, Bigquery, Clickhouse, Delta lake, | Alerts on query failures |
| Latency req: 10s | - | - | - | - | Data warehouse, Redshift, Snowflake, Bigquery, Clickhouse, Delta lake, | Alerts on query timeouts |
We now have a list of tools that we can use to build the data pipeline.
4.2 Filters
With so many tools, filtering is essential to eliminate tools that are not a good fit. Shown below are some common constraints that you might have, use these to eliminate tools that do not fit your scenario.
Existing infrastructure:If your existing infrastructure can handle your new data pipeline use it.Deadlines:Choose the tool that you have the time to set up. If you only have 2 days to build, test & deploy the data pipeline, it might not be a good idea to try to set up Airflow on Kubernetes.Cost:Most vendor tools/services costs money, make sure that the cost is acceptable. Another cost to think about is developer time.Data strategyDiscuss how the above requirements might evolve in the short, mid, and long term. While choosing a tool for the long term might seem like the best choice, it might not always be possible with deadlines and cost.Managed v self-hostedDo you have the ability/team to manage a data platform? This will include setting up CI/CD, scaling, reducing downtime, patching, handling system failures, etc. Does your company’s security policy allow the use of managed service?. Self-managing tools can be a lot of work.SupportDoes the tool have a good support system? Is it open source and popular? Is its code easy to read? Do they have good documentation? Do they have a great community(slack/Discord/Discourse)? A well-supported or documented service can speed up development velocity.Developer ergonomicsHaving good developer ergonomics such as git, local dev environment, ability to test locally, and CI/CD can significantly reduce the number of bugs, increase the speed of development and make the data pipeline a joy to work with. Beware of closed source vendor services, they are very hard to test locally.Number of toolsChoosing tools that satisfy most of the requirements can be beneficial in keeping the pipeline complexity low. This helps with onboarding new engineers, faster development time, and simpler management.
Asking these questions for the tools you had chosen will allow you to narrow down your choices.
5. Conclusion
In summary, when building a data pipeline
- Start with the requirements
- Identify components
- Use the requirement x component framework to choose your tools
- Use the list of filters to choose the right tool for your use case
Hope this article gives you a good idea of how to choose the right tools for your data pipelines. Whether you are building a practice data pipeline or building out your company’s data infrastructure, start from the requirements and filter out tools that don’t fit your scenario.
If you have any questions or comments or would like me to add more components/requirements/filters please leave them in the comment section below.