Introduction
Testing data pipelines are different from testing other applications, like a website backend. If you
Have inherited a data pipeline that has no tests
Have to start adding new features to a data pipeline that doesn’t have any tests
Then this post is for you. In this post we go over 2 overarching types of tests to ensure data quality and correctness:
- Testing for data quality after processing and before it’s available to end-users.
- Standard tests, such as systems, unit, integration, and contract tests.
We also go over monitoring & alerting to ensure that we get alerted on data size skews, pipeline breakages, etc.
Testing your data pipeline
Let’s assume you have inherited a data pipeline that has no tests. It is very unlikely that you will get enough time to write tests to get to 100% code coverage. In such cases, it’s crucial to identify and test the key outputs of your data pipeline. A common order for adding tests is shown below
- End-to-end system testing
- Data quality testing
- Monitoring and alerting (not technically testing, but crucial to detect data size skews, pipeline breakages, etc)
- Unit and contract testing
Notice how we start testing the system as a whole first and then add tests to individual components. While this order of test implementation is generally recommended, depending on your situation, you may choose to skip or change the order of implementation of these tests.
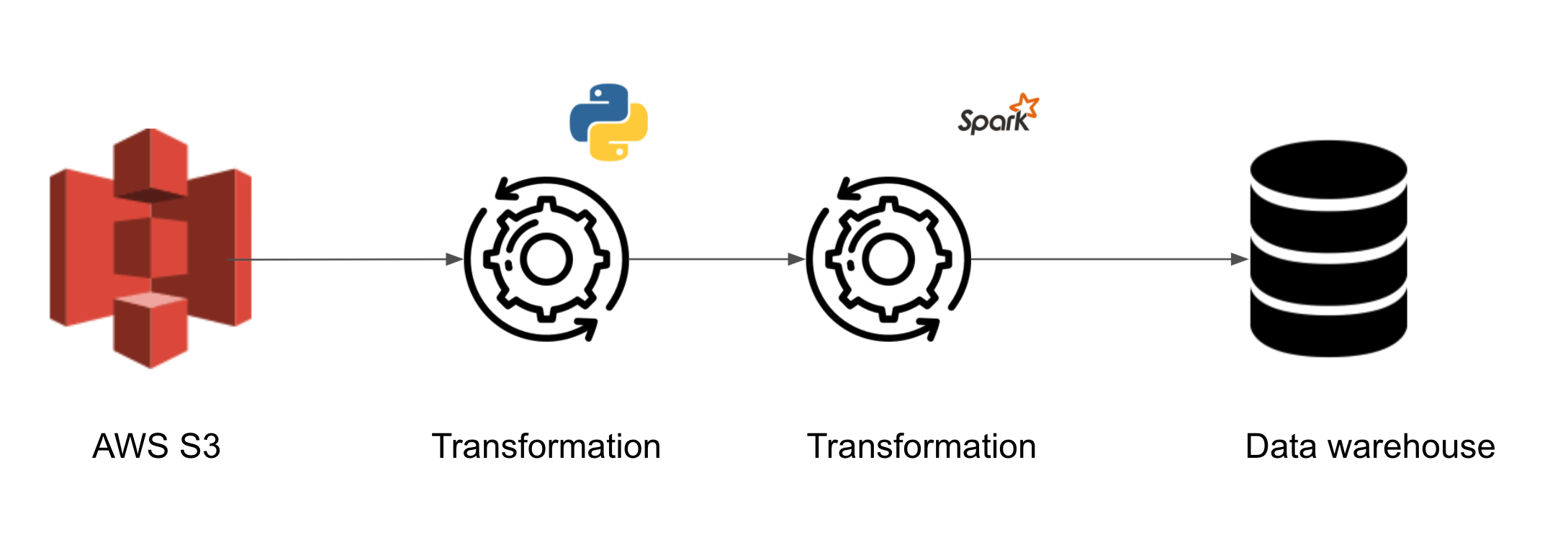
Let’s assume you inherit a data pipeline that
- Reads data from S3
- Performs 2 transformations
- Loads the transformed data into a data warehouse to be used by end-users
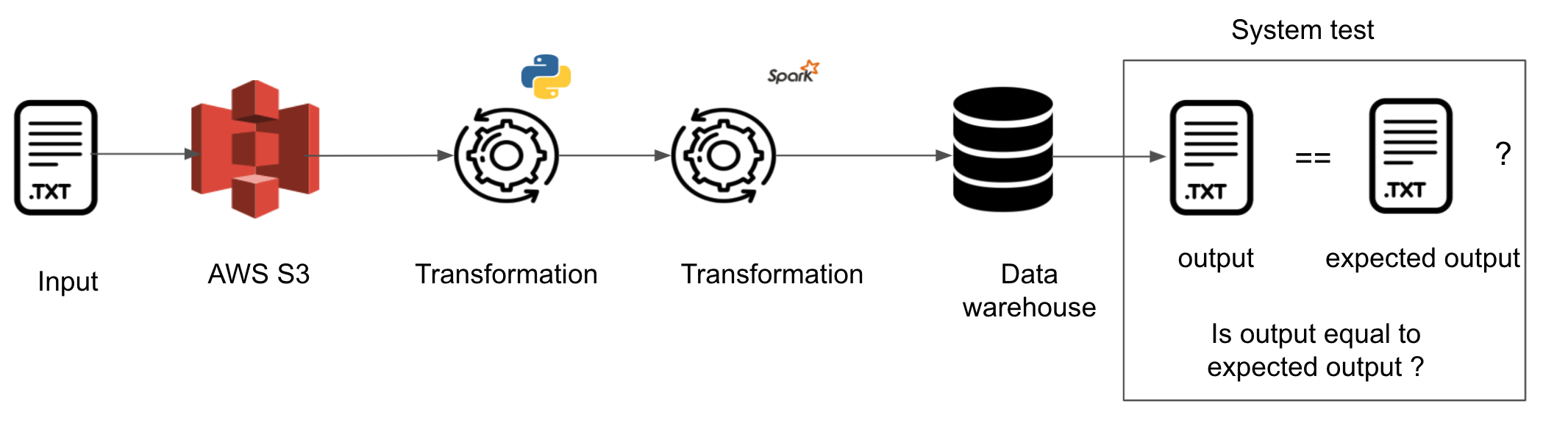
1. End-to-end system testing
As you are starting to add new features, you mustn’t break the existing functionality. For this purpose, you should have end-to-end testing. This can be done by using a sample of input data, running it through the development version of your data pipeline, and comparing the output with the expected output.
A sample snippet for adding systems test, using pytest.
import pytest
from your.data_pipeline_path import run_your_datapipeline
class TestYourDataPipeline:
@pytest.fixtures(scope="class", autouse=True)
def input_data_fixture(self):
# get input fixture data ready
yield
self.tear_down()
def test_data_pipeline_success(self):
run_your_datapipeline()
result = {"some data or file"}
expected_result = "predefined expected data or file"
assert result == expected_result
def tear_down(self):
# remove input fixture dataThis test will be run in your development environment before the code is merged into the main branch. This will ensure that your data pipeline does not break when you add new features.
Checkout this article to learn how to set up end to end tests.
2. Data quality testing
This type of testing is unique to data pipelines. Instead of testing code, we are going to examine the transformed data and ensure that it has the characteristics that we expect. We can do this as shown below
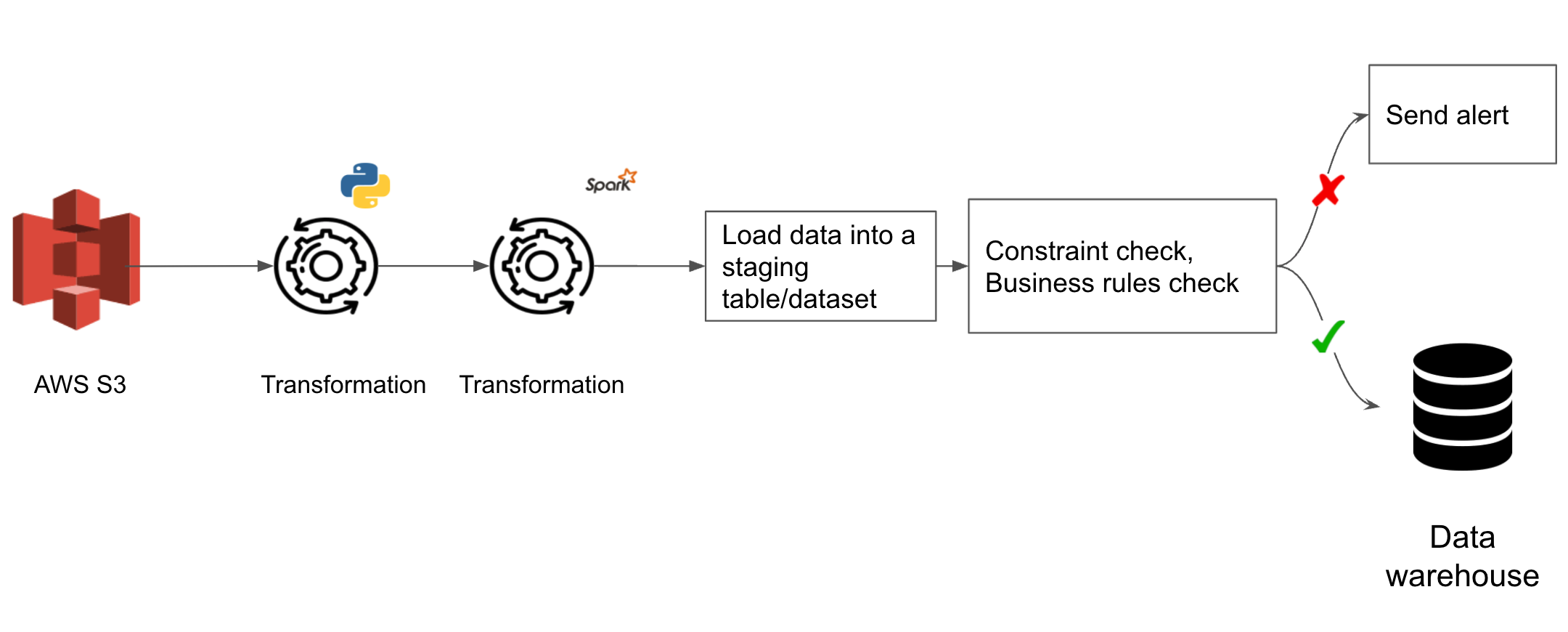
We add 2 tasks to the data pipeline:
- Task to load the transformed data into a temporary staging table/dataset.
- Task to ensure that the data in the temporary staging table falls within the expectation we have of the processed data. This step usually includes checking for uniqueness constraints, allowed values set, business rules, outlier checks, etc
Note how this test is run every time as a part of the data pipeline, unlike the end-to-end test which is not run as a part of the data pipeline.
Dbt and great expectations provide powerful functionality that makes these checks easy to do. If a data quality check fails, an alert is raised to the data engineering team and the data is not loaded into the final table. This allows data engineers to catch unexpected data quality issues before impacting end users/systems.
If you have the time, you can also add data quality testing after each transformation step. This will help you catch errors much earlier in the data pipeline.
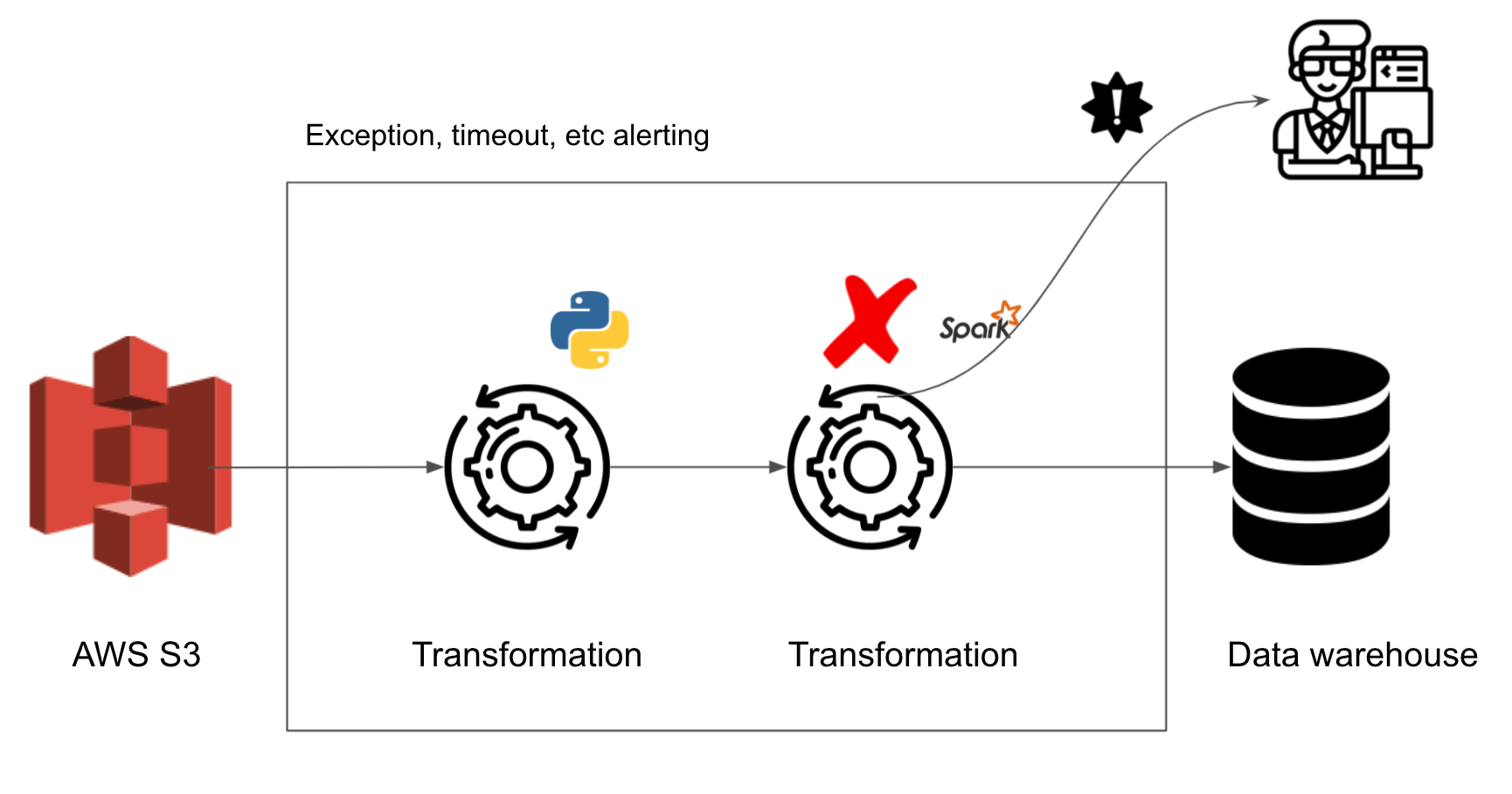
3. Monitoring and alerting
With data quality testing, we can be reasonably confident of the quality of our data. But there can be unexpected skews in data size, skews in the number of rows dropped, etc. In order to catch unexpected changes in data size, we need to monitor our data pipeline. This can be done by sending logs to a service like datadog/newrelic or sending metrics to a database. We can set alerts based on log metrics in datadog/newrelic. If we are sending logs to a database, we will need a service like looker/Metabase to alert us in case of data size skews.
The logs can be as simple as a count of rows before and after the transformation step.
Setting up an outlier alert for these counts can be done via datadog or newrelic. If logs are stored in a database, set up a alert on looker or Metabase with a query like this.

With end-to-end testing, we can add new features without the fear of breaking the data pipeline. But there can still be errors such as out-of-memory errors, file not found errors, etc. In order to be notified of pipeline breakage promptly, we need to set up alerting for our data pipeline. This can be done by setting up slack/email alerts from a service like datadog or newrelic.
4. Unit and contract testing
Having end-to-end system testing, data quality testing, and monitoring and alerting in place will give you the confidence to move fast and deliver good quality data. The next step is to add standard unit tests for your functions and contract tests where your data pipeline interacts with external systems, such as an API call to a microservice or an external vendor. These tests give you more confidence when modifying code logic and help prevent bugs in general.
Conclusion
Hope this article gives you a good idea of how to start testing a data pipeline. Having these tests enable you to add features confidently. It also ensures that the output data is of good quality. To recap, start adding tests and monitoring in the following order
- End-to-end system test
- Data quality tests
- Monitoring and Alerting
- Unit and contract tests
We also saw that there are 2 overarching types of tests to ensure data quality and correctness:
- Testing for data quality, post-processing
- Standard tests
The key idea is to start testing the key outputs of your data pipeline. Start outward(end-to-end test) and move inwards(unit tests). As always please let me know if you have any questions or comments in the comment section below.