Introduction
Change data capture is a software design pattern used to track every change(update, insert, delete) to the data in a database. In most databases these types of changes are added to an append only log (Binlog in MySQL, Write Ahead Log in PostgreSQL). These logs can be used to track the data changes without having to query via the SQL interface.
Singer is an open source standard that formalizes the data schema for reading data from multiple types of input sources(aka tap) such as databases, csv files, SAAS apps and the data format for writing to different destinations(target) such as databases, text files, etc.
Singer has multiple taps and targets available and it’s relatively simple to write your own.
Why Change Data Capture
You may be wondering why someone would need to capture data changes in a specific database. The main reason is to move data between different types of databases. Some use cases are
- tracking data changes to feed into an elastic search index for text based querying.
- moving data changes from OLTP to OLAP without querying the OLTP tables directly (LOG_BASED load).
- creating audit logs, etc
Setup

Prerequisites
In a directory of your choosing, create a folder singercdc. This will be the project folder for this post.
Virtual environment or docker is recommended, but for this simple example, direct installation should be sufficient.
Source setup
We will be using a MySQL database as our source database. Let’s spin up a MySQL docker container
Now you are in your MySQL console. Let’s create a simple animals table and populate it with one row.
CREATE DATABASE source_db;
USE source_db;
DROP TABLE IF EXISTS animals;
CREATE TABLE IF NOT EXISTS animals (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(10),
likes_getting_petted BOOLEAN
);
INSERT INTO animals (name, likes_getting_petted)
values ('porcupine', false);
\q -- to quit mysql client
exit -- to exit the docker containerIn your project folder, create a src_config.json file to specify the MySQL connection parameters. The contents of this file should be as follows
Destination setup
We will use a PostgreSQL database as our destination data warehouse. Let’s start a PostgreSQL docker container and log into it as shown below.
Let’s create a destination schema.
In your project folder create a dest_config.json file to specify the connection parameters for PostgreSQL. It must contain the following content.
Your project folder should contain src_config.json and dest_config.json files.
Source, MySQL
There are 3 main ways in which we can extract data from the MySQL source, they are
- FULL_TABLE: Reads the entire table data from SQL. Eg):
SELECT C1, C2 FROM table1;. - INCREMENTAL: Reads table data from SQL using an ordered key. Eg):
SELECT C1, C2 FROM table1 WHERE C1 >= last_read_C1;. Loads incrementally using the last read key. - LOG_BASED: Reads data directly from the
binlog. Loads incrementally using the last read log number. Logs are numbered sequentially in order.
We will use LOG_BASED approach in this example. The other 2 approaches will affect the database performance as they require querying via the SQL interface.
When you make changes to a table or its data in MySQL they are logged in a Binary Log. These logs are located at /var/lib/mysql inside the MySQL docker container. The database creates new binary log files(named binlog.number) as an individual file hits the log file size threshold. We can see the list of binary log files in binlog.index. We can use the mysqlbinlog util to read the binary logs as shown below.
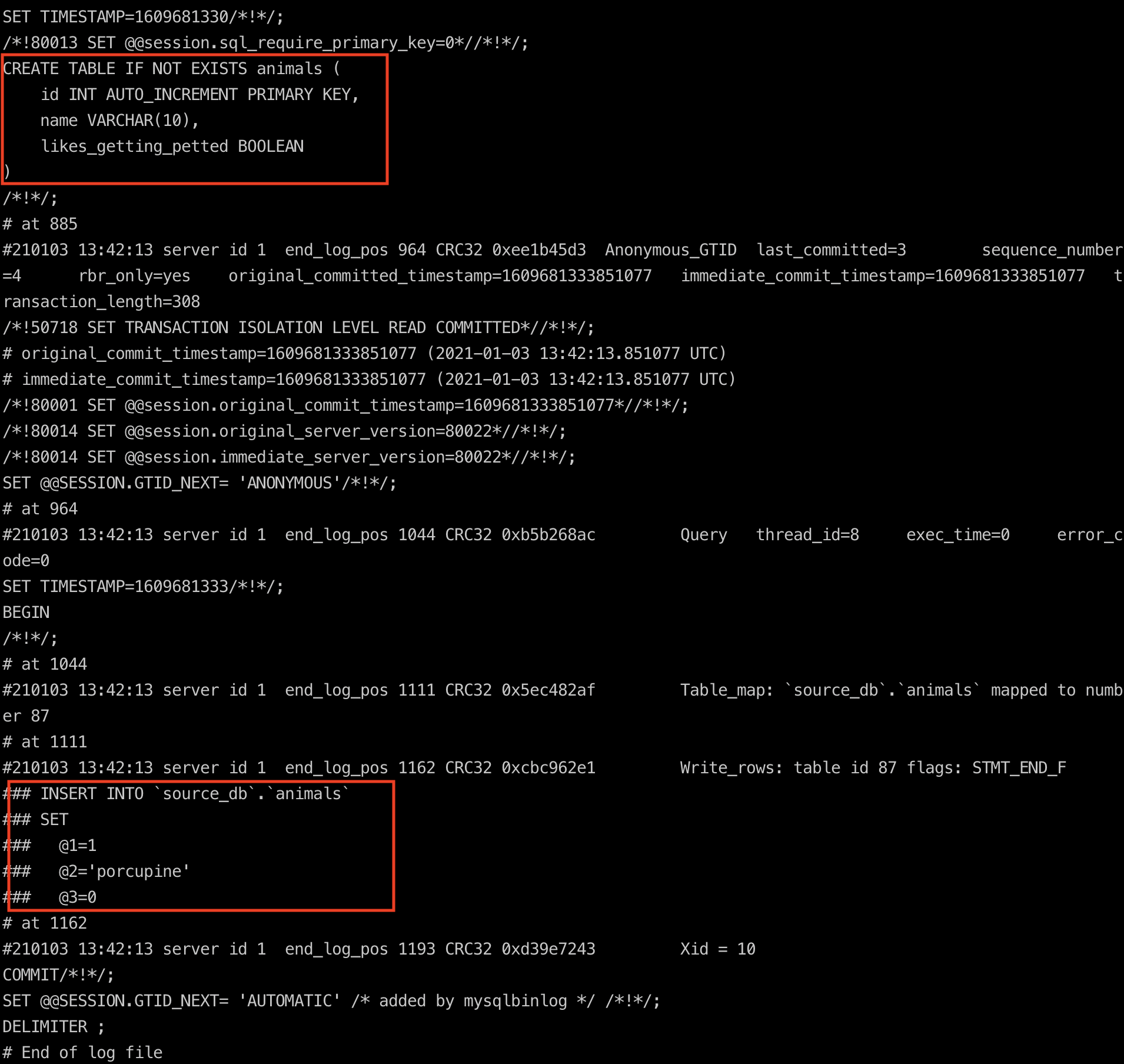
The Singer MySQL tap uses this library to read data from the binary log file and create events that can be fed to a target. In order to use the tap, we need to specify which tables to track using a properties.json file. We can generate this file using the command shown below.
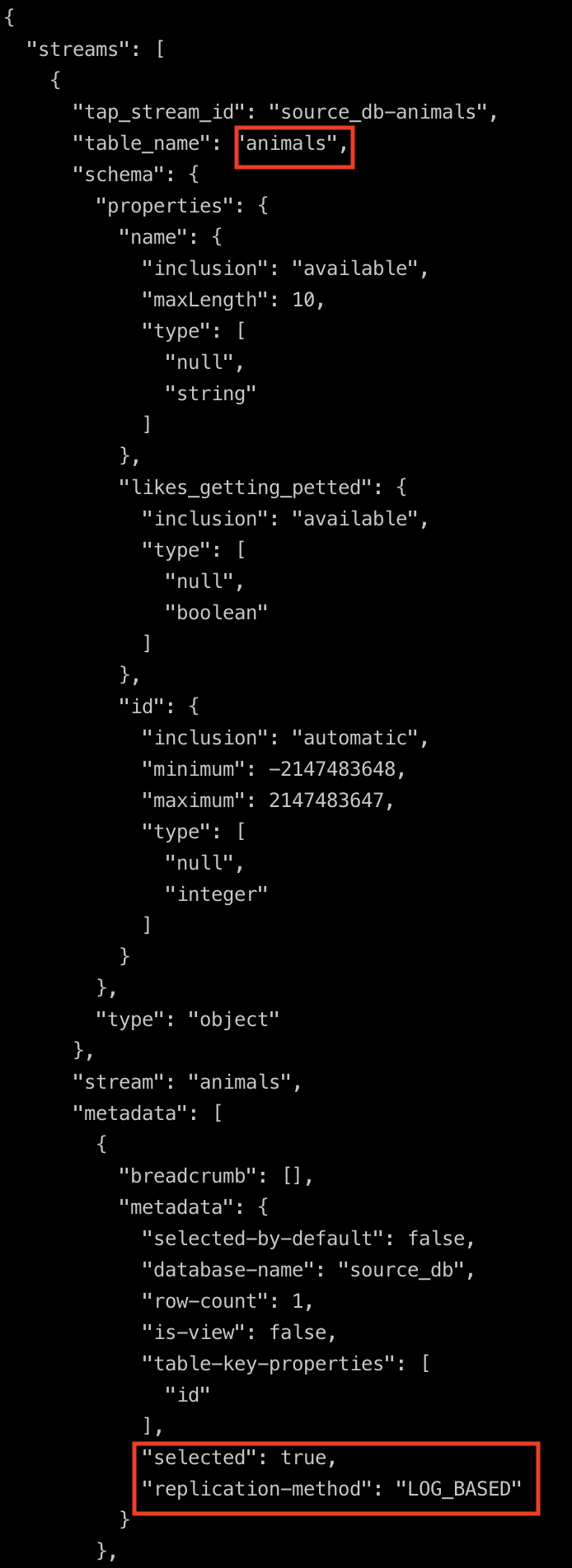
Edit the properties.json and add these two key value pairs to "selected": true, and "replication-method": "LOG_BASED" to the dictionary in streams which has the table_name value as animals. By default the tables are not selected for replication. The changes are shown below.
Now that we have the properties setup, we can run the tap to extract the animals table records. The jq is optional, we use it here to format our json output.
You will see this record in the text:
Let’s insert a few records in to our animals table. In the source database, do the following
Now lets run the tap again with
This time you will notice 3 records: porcupine, bear and cow. But we have already seen porcupine. If you want to do an incremental load you need to let the tap know which log event in the binlog to start from.
We can do this by creating a state file, which will keep track of the latest log read from the binlog. In subsequent loads we will use this state file and only read logs that come after that specific log. This way we only read the incremental data changes. We can create a state file as shown below.
If you did not install jq, you can copy the dictionary of the "value" key from the last line of the output.
The state.json file will contain the last read log position as shown below.
Let’s insert a few more records in to our animals table to test incremental loads. In the source database, do the following
Now if we tap the source while specifying the state the tap will only read the new records.
Now you will only see the incremental records of dog, elephant and frog show up. You can use state file to keep track of the latest record that was read. You can either version it and have a script to pick the right version or naively use unix to overwrite state file as shown below.
CDC, MySQL => PostgreSQL
Now that we have the tap(MySQL) set up to work incrementally we can look at how the tap events are converted into DML statements for the target. This is as simple as running a unix pipe.
Let’s log into our PostgreSQL instance and check the table.
The table animals has been created in the destination database and the 6 rows have been inserted.
If you run the tap ... | target ... pipe again you will notice that the records get overwritten in the target. Let’s use the state functionality to only do incremental loads. First let’s insert some new records into MySQL as shown below
Let’s setup incremental load to target as shown below.
If you look at the _sdc_sequence column in the target table, you will see that the last 3 records have a different number compared to the previously loaded records.
You can insert new records in the source and rerun the incremental load to target to test.
Once you are done experimenting you can stop the running docker containers as shown below.
Pros and Cons
Let’s look at some pros and cons of this approach.
Pros
- Open source.
- Enables in order processing of change data events, as opposed to something like debezium on kafka which introduces event ordering issues.
- Streaming pattern from tap to target, keeping memory usage low.
- Creating taps and targets are simple.
- Can be scheduled with cron, Airflow, etc.
Cons
- Managing state involves a lot of extra work.
- Not all data types are supported, Ref.
- DDL statements are not supported.
- The tap and target run as a simple scripts and are not distributed. We can pipe the output to a Kafka topic, but this involves extra code.
- The data types between source and destination may vary.
In addition to this there are Tap and Target specific concerns.
Conclusion
To recap, we saw
- What CDC is.
- What
Binlogin MySQL is. - How Singer reads data change events from the
binlog. - How to manage a Singer CDC pipeline with state to do incremental loads.
Hope this article gives you a good idea of how you can use Singer to automate CDC. Although Singer is a bit rough around the edges it provides a good framework to build on top of. There are some open source projects like Pipelinewise and Meltano which uses Singer specs for EL. You can easily write an Airflow operator using Singer specs which keeps its state in a cloud storage this would be a good option as well.
Next time you are required to build a EL pipeline try out Singer and see if it can fit your use case, before writing your own logic. Let me know if you have any questions or comments in the comment section below.