Data Engineering Best Practices - #1. Data flow & Code
- 1. Introduction
- 2. Sample project
- 3. Best practices
- 3.1. Use standard patterns that progressively transform your data
- 3.2. Ensure data is valid before exposing it to its consumers (aka data quality checks)
- 3.3. Avoid data duplicates with idempotent pipelines
- 3.4. Write DRY code & keep I/O separate from data transformation
- 3.5. Know the when, how, & what (aka metadata) of pipeline runs for easier debugging
- 3.6. Use tests to check code behavior and not break existing logic
- 4. Conclusion
- 5. Next steps
- 6. Further reading
1. Introduction
Building data pipelines without sufficient guidance can be overwhelming. It can be hard to know if you are following best practices. If you
Do not work with multiple data engineers providing feedback on your pipelines
Are working as a sole data engineer, wondering about how your technical skills are developing
Build data pipelines but are not sure if they follow industry standards
Are not sure if you measure up to data engineers at bigger tech companies
Then this post is for you. This post will review best practices for designing data pipelines, understanding industry standards, thinking about data quality, and writing maintainable and easy-to-work code.
By the end of this post, you will understand the critical components of designing a data pipeline and the need for these components, and you will be able to ramp up on any new code base quickly.
2. Sample project
Assume we are extracting customer and order information from upstream sources and creating a daily report of the number of orders.

If you’d like to code along, you’ll need
Prerequisite:
- git version >= 2.37.1
- Docker version >= 20.10.17
and Docker compose v2 version >= v2.10.2
. Make sure that docker is running using
docker ps - pgcli
Run the following commands via the terminal. If you are using Windows, use WSL to set up Ubuntu and run the following commands via that terminal.
git clone https://github.com/josephmachado/data_engineering_best_practices.git
cd data_engineering_best_practices
make up # Spin up containers
make ddl # Create tables & views
make ci # Run checks & tests
make etl # Run etl
make spark-sh # Spark shell to check created tables
spark.sql("select partition from adventureworks.sales_mart group by 1").show() // should be the number of times you ran `make etl`
spark.sql("select count(*) from businessintelligence.sales_mart").show() // 59
spark.sql("select count(*) from adventureworks.dim_customer").show() // 1000 * num of etl runs
spark.sql("select count(*) from adventureworks.fct_orders").show() // 10000 * num of etl runs
You can see the results of DQ checks, using make meta
select * from ge_validations_store limit 1;
exit
3. Best practices
3.1. Use standard patterns that progressively transform your data
Following an established way of processing data accounts for handling common potential issues, and you have plenty of resources to reference. Most industry-standard patterns follow a 3-hop (or layered) architecture. They are
- Raw layer stores data from upstream sources as is. This layer sometimes involves changing data types and standardizing column names.
- Transformed layer: Data from the raw layer is transformed based on a chosen modeling principle to form a set of tables. Common modeling principles are Dimensional modeling (Kimball), Data Vault model, entity-relationship data model, etc.
- Consumption layer: Data from the transformed layer are combined to form datasets that directly map to the end-user use case. The consumption layer typically involves joining and aggregating transformed layer tables to enable end-users to analyze historical performance. Business-specific metrics are often defined at this layer. We should ensure that a metric is only defined in one place.
- Interface layer [Optional]: Data in the consumption layer often confirms the data warehouse naming/data types, etc. However, the data presented to the end user should be easy to use and understand. An interface layer is often a view that acts as an interface between the warehouse table and the consumers of this table.
Most frameworks/tools propose their version of the 3-hop architecture:
Shown below is our project’s 3-hop architecture:
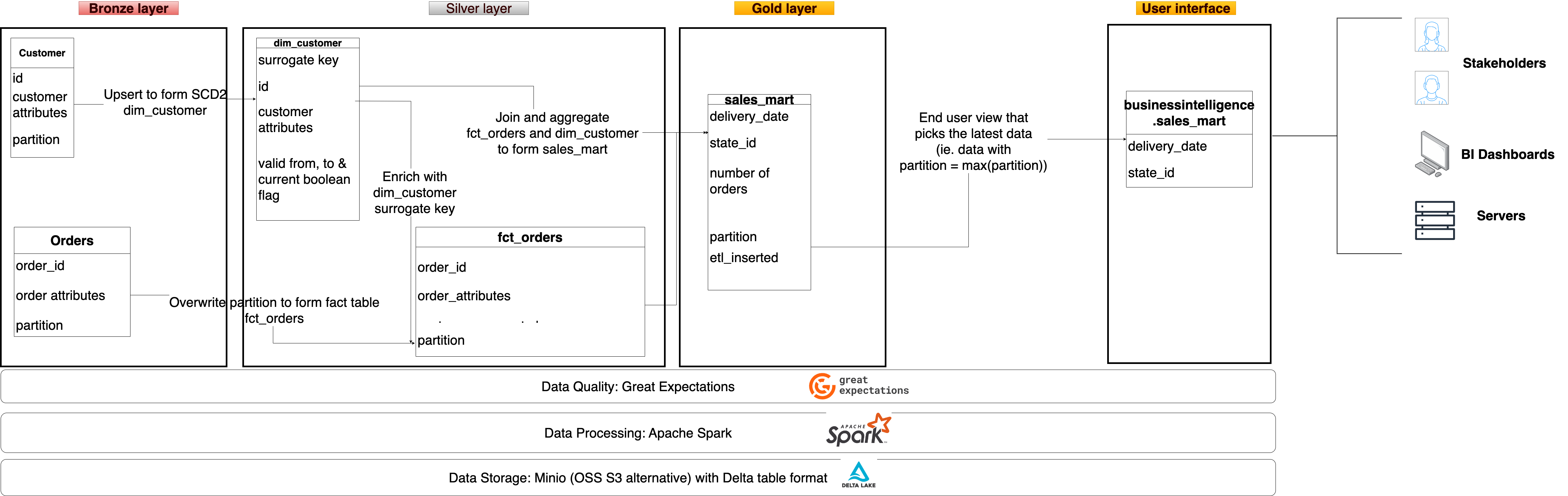
The bronze, silver, gold, and interface layers correspond to the abovementioned raw, transformed, consumption, and interface layers. We have used dimensional modeling (with SCD2 for dim_customers) for our silver layer.
For a pipeline/transformation function/table, inputs are called upstream, and output users are called downstream consumers.
At larger companies, multiple teams work on different layers. A data ingestion team may bring the data into the bronze layer, and other teams may build their own silver and gold tables as necessary.
3.2. Ensure data is valid before exposing it to its consumers (aka data quality checks)
When building a dataset, it’s critical to identify what you expect of that data. The expectations of the dataset can be as simple as a column being true to more complex business requirements.
If downstream consumers use bad data, it can be disastrous. E.g., Sending the wrong data to a client or using the incorrect data to spend money. The process to rectify usage of bad data often involves the time-consuming and expensive re-running of all the affected processes!
To prevent consumers from accidentally using bad data, we should check the data before making it available for consumption.
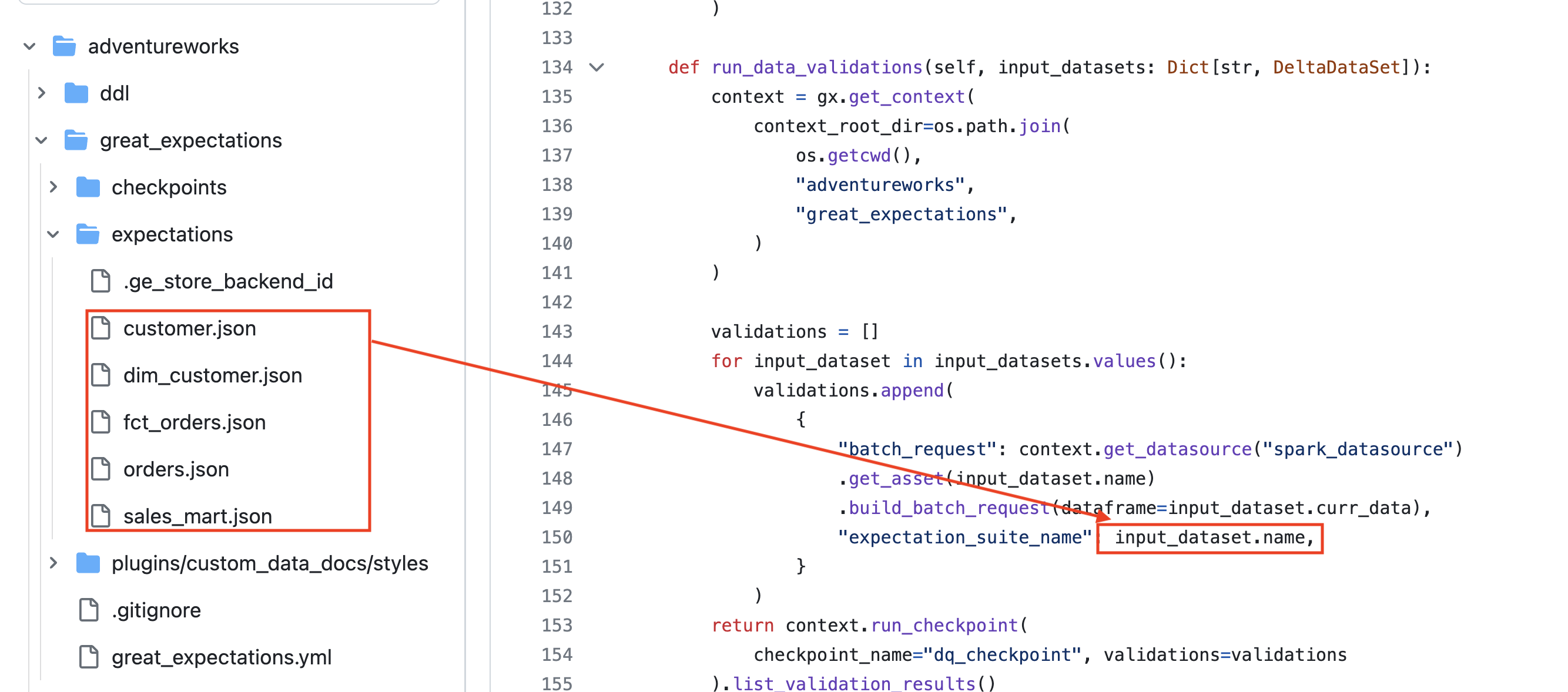
Let’s see how to do data quality checks when we create a dataset:
We use the Great Expectations library to define and run our data checks (aka expectations). The run_data_validation checks if a dataset meets its expectations. We expose data to its downstream consumers only when it passes its expectations.
Keeping the definition of what we expect from our data separate from the code leads to cleaner code. Our code uses the expectations stored as a JSON file.
While DQ checks help significantly, it’s easy to overdo DQ checks; some issues with too many tests are:
- Increased pipeline run time
- Increased cost, as running tests require a full table scan (not always)
- Redundant tests. E.g., having a Not null check on two tables, unioning them, and doing a not null check again.
- More code
You have to decide on a tradeoff between the quality of your output data and the cost to manage and run tests. A typical approach companies use to save testing time is to check the quality of source data and final consumption data, ignoring the intermediate tables.
3.3. Avoid data duplicates with idempotent pipelines
Backfilling refers to re-running data pipelines and is a common operation. When re-running data pipelines, we must ensure the output does not contain duplicate rows. The property of a system to always produce the same output, given the same inputs, is called idempotence .
Shown below are two techniques to avoid data duplicates when re-running data pipelines:
-
Run id based overwrites: Used for append only output data. Ensure that your output data has the run id as a partition column (e.g. partition column in our gold table ). The run id represents the time range that the data created belongs to. When you reprocess data overwrite based on the given run id .
For this approach, you must keep track of run-ids (e.g. Airflow has a backfill command ).
-
Natural key-based UPSERTS: Used when the pipeline performs inserts and updates on output data with a Natural key . Dimensional data that requires updates on existing rows (e.g. SCD2 ) uses this approach. Duplicates from re-running pipelines result in updates of existing rows (instead of creating new rows in the output). We use this approach to populate our dim_customer table.
3.4. Write DRY code & keep I/O separate from data transformation
While there are multiple patterns to organize your code , all of them follow the DRY (dont-repeat-yourself) principle. We can think of the DRY principle along two-axis
-
Code: Standard code must remain in a single place. The standard code can be a utility function or a base class method that gets inherited (e.g., publish_data in our project)
-
Patterns: Most company pipelines follow similar/same patterns, which depend on the tools available and the engineer designing them. Establishing a blueprint for how the pattern should be enables consistent standards among the data team.
In our project, we establish the data processing pattern in the StandardETL class which gets inherited by other pipelines(e.g. SalesMartETL ).
Function to read/write data(I/O) must be separate from the transformation logic. The separation of I/O from transformation enables easier testing of transformation logic, simpler debugging, and follows functional design principles .
Our project follows a clear separtion of I/O (publish_data ) from transformation logic (get_silver_datasets , etc)
3.5. Know the when, how, & what (aka metadata) of pipeline runs for easier debugging
Understanding how data flows through your pipeline is crucial for explainability, maintainability, and debugging. For each processing step, we should track it’s
- Inputs & Outputs
- Start and end times
- Number of retries(if any), along with which ones passed and which ones failed
Most orchestrators store this information. It is also critical to store information about the data created by a pipeline. Ideally, the following information about the data should be in version control:
Unique keys (if any): The columns representing a unique field.Physical storage location: The physical storage location of the dataset, e.g. (s3://your-bucket/data-name)Table (or dataset) name: The output table/dataset name.Storage type: The data storage format (Delta, Iceberg, etc.)Partition key(s) (if any): Column(s) by which the data is partitioned.Data Schema: Column names with data types.
In our project we use the DeltaDataSet dataclass to represent the metadata about the data. Our create/alter tables commands are in the DDL folder .
3.6. Use tests to check code behavior and not break existing logic
Tests are critical to ensure that our code behaves how we want it to and that changing existing code does not break existing logic.
There are three main types of tests for data pipelines.
Unit: Tests to ensure a single function works as expected. eg. test_get_bronze_datasetsIntegration: Tests to check that two or more systems are working together as expected. eg. test_get_validate_publish_silver_datasets tests the intergration between transformation and I/O systems.End-to-End: Tests to check that the system is working end-to-end as expected. These are hard to set up for complex systems and are often overkill.
We use pytest to run out test cases. When we run the pytest command, the following happens:
- Conftest.py creates a spark session and yields it to pytest
- The spark session from Step 1 is used to run the test cases
- Finally, pytest returns control to conftest.py, stopping the spark session.
Since spark session takes a while to create, sharing them among the test cases will save time. While tests are beneficial, be careful not to overdo them, as it will increase development velocity.
Checkout this section on how to use pytest .
4. Conclusion
This article provides a good idea of the concepts to concentrate on while building a data pipeline. To recap, in this post, we went over the following data pipeline best practices:
2.Ensure data is valid before user consumption
5.Track data pipeline runs and know your data
6.Check code behavior with testing
Most companies (both big & small) may have only some of these best practices in place; this may be due to prioritizing different outcomes, or there may be no need for some.
Analyze your pipelines/requirements, identify high-priority issues, and use best practices to address them before spending a lot of time implementing best practices to have best practices.
If you have any questions or comments, please leave them in the comment section below or open an issue here .
5. Next steps
If you want to understand how to set up cloud infrastructure(with orchestrator) for this project, please comment on this issue .
6. Further reading
- Data pipeline design patterns
- Data pipeline code patterns
- Data quality
- Great expectations
- Python yield
If you found this article helpful, share it with a friend or colleague using one of the socials below!