What is data quality
As the name suggest, it refers to the quality of our data. Quality should be defined based on your project requirements. It can be as simple as ensuring a certain column has only the allowed values present or falls within a given range of values to more complex cases like, when a certain column must match a specific regex pattern, fall within a standard deviation range, etc.
Why is it important
The quality of your data will affect the ability of your company to make intelligent and correct business decisions.
For example a business user may want to look at customer attribution using a third party marketing dataset, if for whatever reason the third party data source maybe faulty and if this goes unnoticed, it will lead to the business user making decision based on wrong data. Depending on how the data is used this can cause significant monetary damage to your business.
Another example would be machine learning systems, this is even trickier because you do not have the intuition of a human in the loop with computer systems. If there was an issue with a feature (say feature scaling was not done) and the ML model uses this feature, all the prediction will be way off since your model is using unscaled data. And if you have no ML model monitoring setup this can cause significant damage(money or other metric based) over a long period to your business.
Tutorial
In this tutorial we will build a simple data test scenario using an extremely popular data testing framework called Great Expectations
pre-requisites
- docker, if you have windows home you might need to look here
- pgcli
- Great Expectations
simple usage
You can use great_expectations as you would any other python library. Open a python repl by typing in python in your terminal
import great_expectations as ge
import numpy as np
import pandas as pd
# ref: https://stackoverflow.com/questions/32752292/how-to-create-a-dataframe-of-random-integers-with-pandas
df_raw = pd.DataFrame(np.random.randint(0,100,size=(100, 4)), columns=list('ABCD'))
df = ge.from_pandas(df_raw)
df.expect_column_values_to_not_be_null('A'){
"exception_info": null,
"expectation_config": {
"expectation_type": "expect_column_values_to_not_be_null",
"kwargs": {
"column": "A",
"result_format": "BASIC"
},
"meta": {}
},
"meta": {},
"success": true,
"result": {
"element_count": 100,
"unexpected_count": 0,
"unexpected_percent": 0.0,
"partial_unexpected_list": []
}
}{
"exception_info": null,
"expectation_config": {
"expectation_type": "expect_column_values_to_be_unique",
"kwargs": {
"column": "A",
"result_format": "BASIC"
},
"meta": {}
},
"meta": {},
"success": false,
"result": {
"element_count": 100,
"missing_count": 0,
"missing_percent": 0.0,
"unexpected_count": 62,
"unexpected_percent": 62.0,
"unexpected_percent_nonmissing": 62.0,
"partial_unexpected_list": [
37,
62,
72,
53,
22,
61,
95,
21,
64,
59,
77,
53,
0,
22,
24,
46,
0,
16,
78,
60
]
}
}The result section of the response JSON has some metadata information about the column and what percentage failed the expectation. But note that here we are testing by loading the data within the application, in the next section we will see how we can create exceptions that are run on databases. Now that we have a basic understanding on what great_expectations does, let’s look at how to set it up, writes test cases for data from a postgres database that can be grouped together and run.
setup
Start a local postgres docker using the below command on your terminal
The docker run is used to run a docker container, we also specify the port -p, user, password and database for the postgres container. We also specify the container to use postgres:12.2. Now we can start writing queries on the postgres container, let’s log into it as shown below
Let’s create a simple app.order table which we will use as our data source, to be tested
CREATE SCHEMA app;
CREATE TABLE IF NOT EXISTS app.order(
order_id varchar(10),
customer_order_id varchar(15),
order_status varchar(20),
order_purchase_timestamp timestamp
);
INSERT INTO app.order(order_id, customer_order_id, order_status, order_purchase_timestamp)
VALUES ('order_1','customer_1','delivered','2020-07-01 10:56:33');
INSERT INTO app.order(order_id, customer_order_id, order_status, order_purchase_timestamp)
VALUES ('order_2','customer_1','delivered','2020-07-02 20:41:37');
INSERT INTO app.order(order_id, customer_order_id, order_status, order_purchase_timestamp)
VALUES ('order_3','customer_2','shipped','2020-07-03 11:33:07');Defining test cases (aka expectations)
In great expectations, the test cases for your data source are grouped into an expectations. In your terminal run the following commands to setup the great_expectations folder structure.
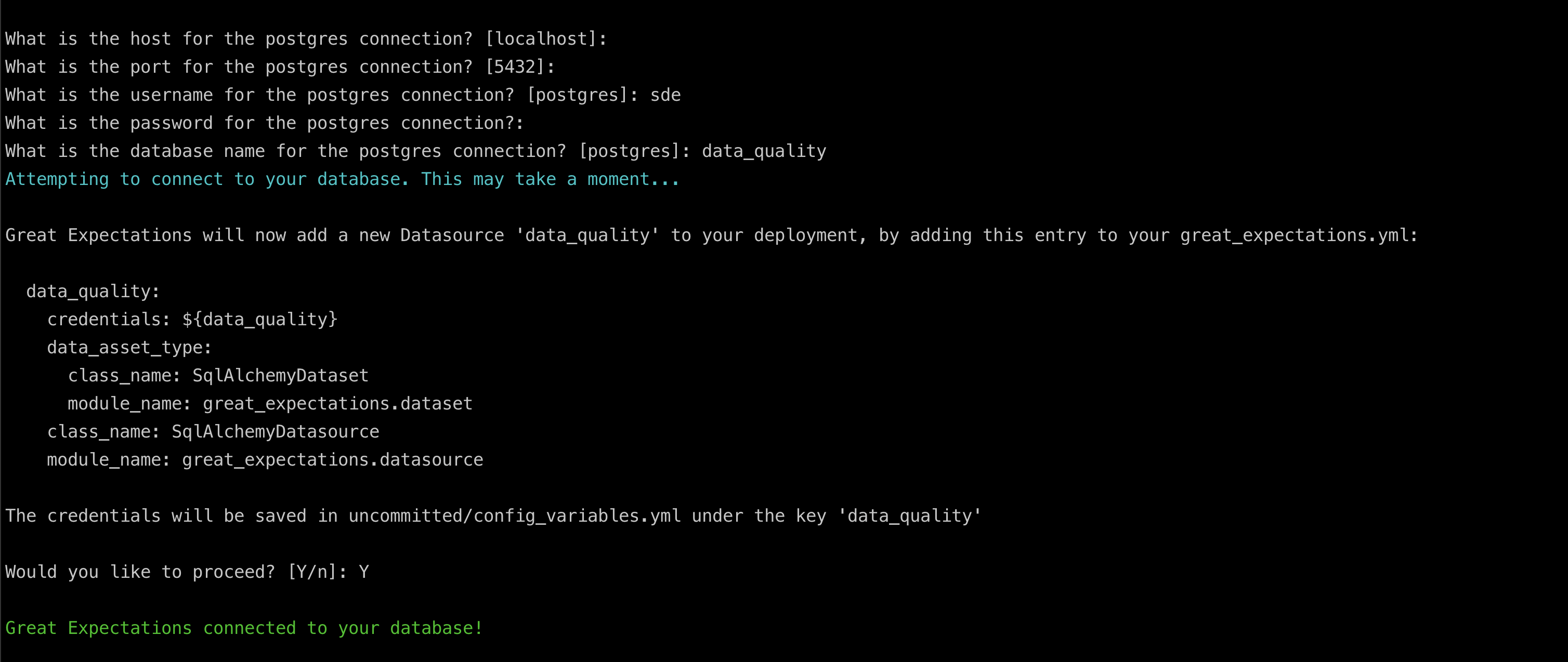
It should look like the image shown below
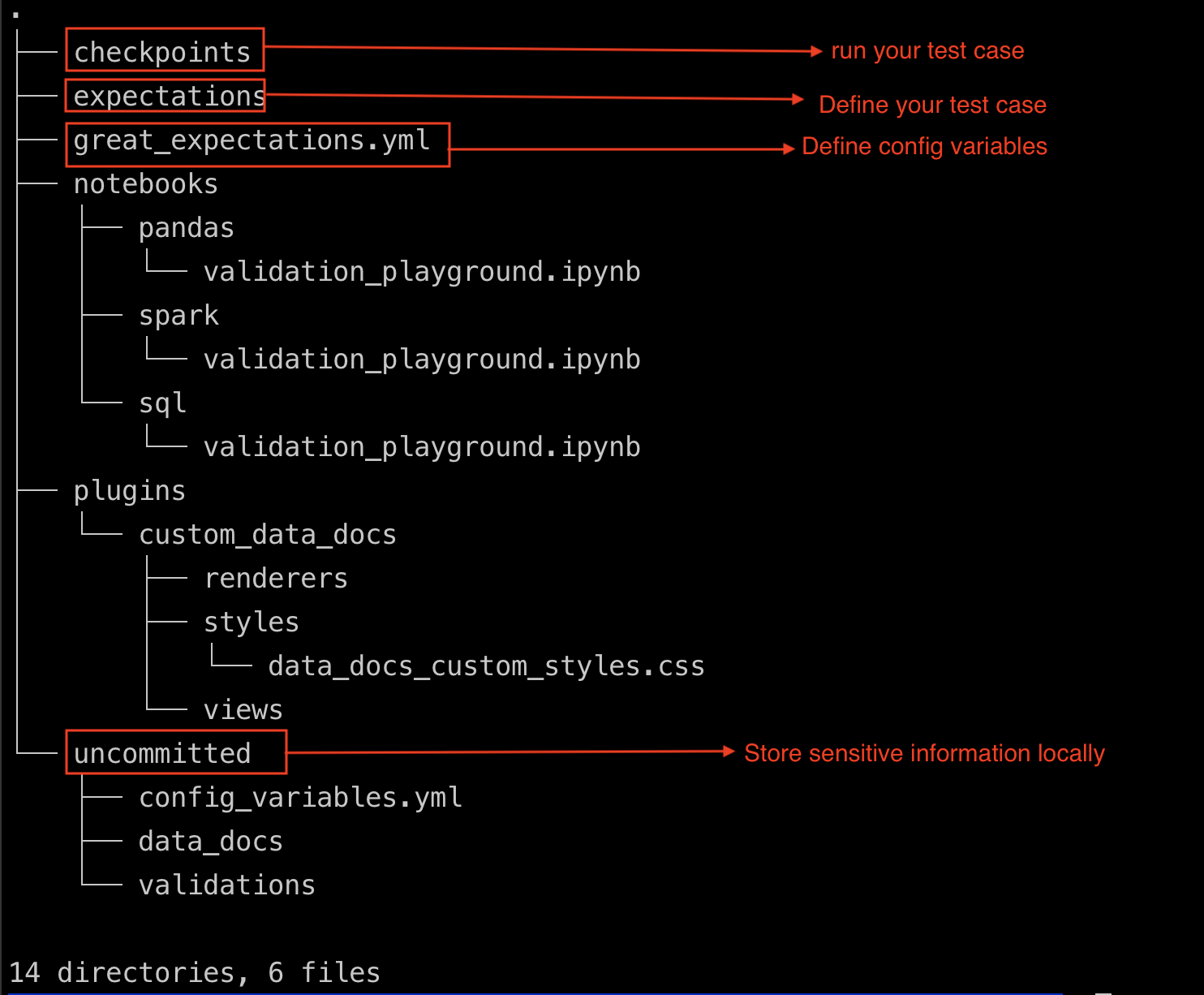
And your project folder structure should look like the image shown below
Let’s create a new set of expectations
You will see something like shown below
{
"data_asset_type": "Dataset",
"expectation_suite_name": "app.order.warning",
"expectations": [
{
"expectation_type": "expect_table_row_count_to_be_between",
"kwargs": {
"max_value": 3,
"min_value": 2
},
"meta": {
"BasicSuiteBuilderProfiler": {
"confidence": "very low"
}
}
},{
"expectation_type": "expect_column_value_lengths_to_be_between",
"kwargs": {
"column": "order_id",
"min_value": 1
},
"meta": {
"BasicSuiteBuilderProfiler": {
"confidence": "very low"
}
}
}
],
"columns": {
"customer_order_id": {
"description": ""
},
"order_id": {
"description": ""
},
"order_purchase_timestamp": {
"description": ""
},
"order_status": {
"description": ""
}
},
"great_expectations.__version__": "0.11.8",
"notes": {
"content": [
"#### This is an _example_ suite\n\n- This suite was made by quickly glancing at 1000 rows of your data.\n- This is **not a production suite**. It is meant to show examples of expecta
tions.\n- Because this suite was auto-generated using a very basic profiler that does not know your data like you do, many of the expectations may not be meaningful.\n"
],
"format": "markdown"
}
}
}As the content says, this is a simple expectation configuration created by great expectations based on scanning first 1000 rows of your dataset. Let’s view this in the data doc site, since these are static website you can just open them directly in your web browser, let’s open the file /great_expectations/uncommitted/data_docs/local_site/index.html
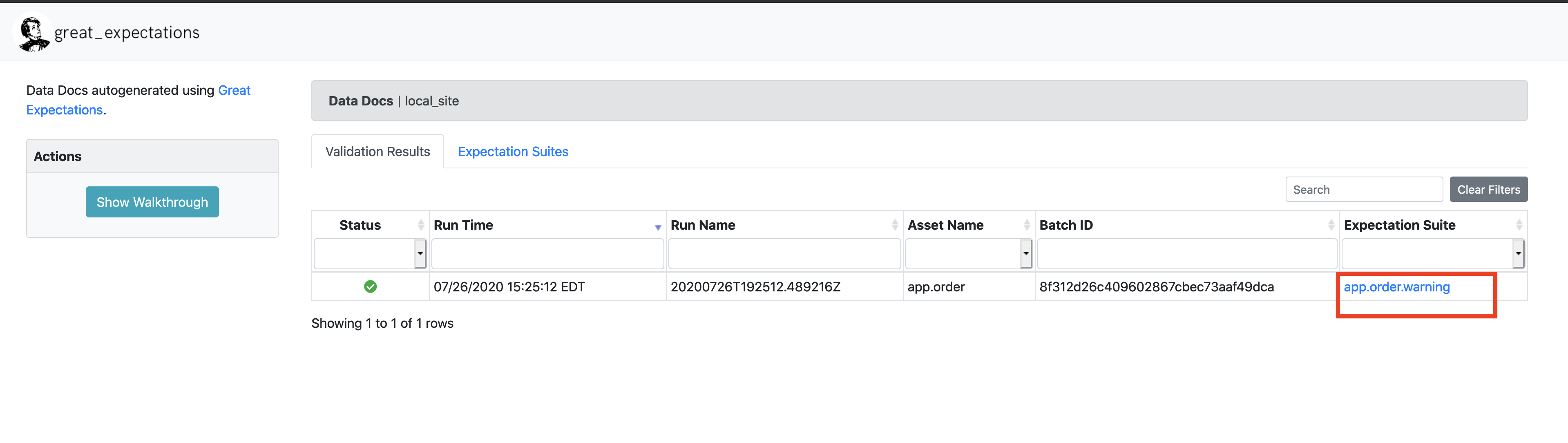
When you click on the app.order.warning expectation suite, you will see the sample expectation shown in human readable format in the UI
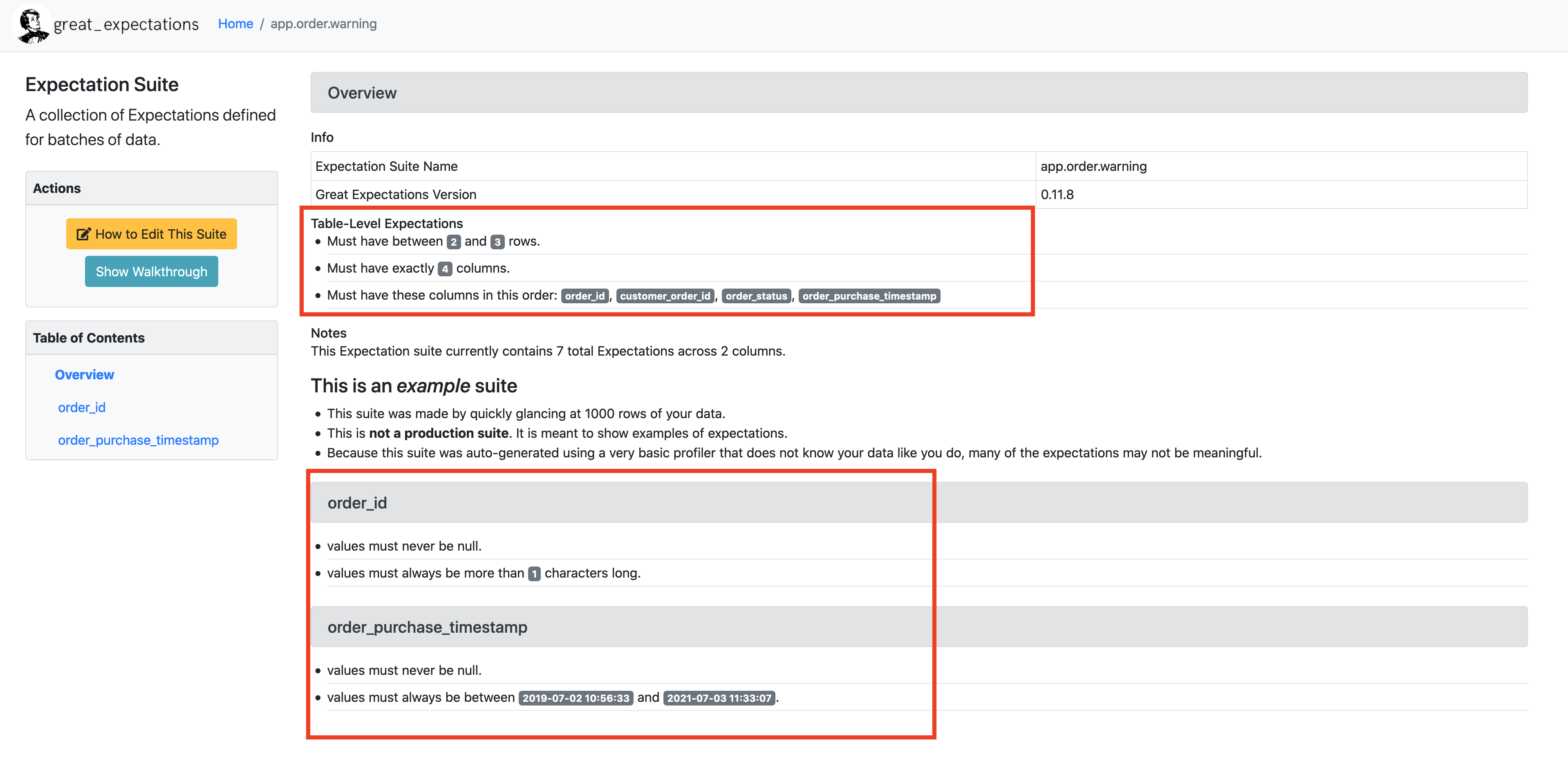
Now let’s create our own expectation file, and call it error
This will also start a jupyter notebook, feel free to ctrl + c to close that.
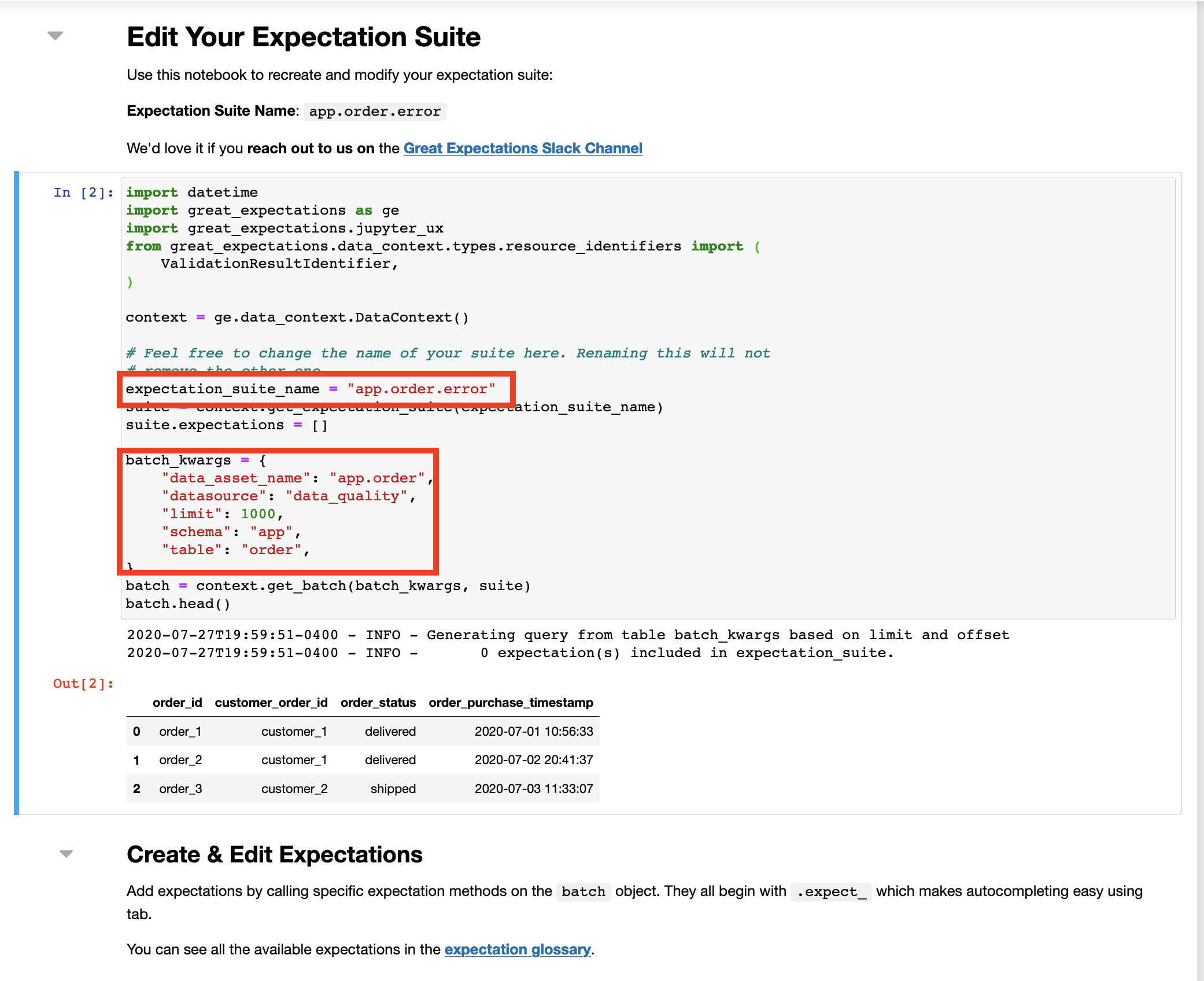
We can edit the expectations using the command below, which opens a jupyter notebook where you can edit and save your changes.
Here you will see your expectation name, batch_kwargs that define where the data is. To keep it simple let’s delete all auto generated test cases and only test if the customer_order_id column is in a set with the below values
using the expect_column_values_to_be_in_set function on your batch object.
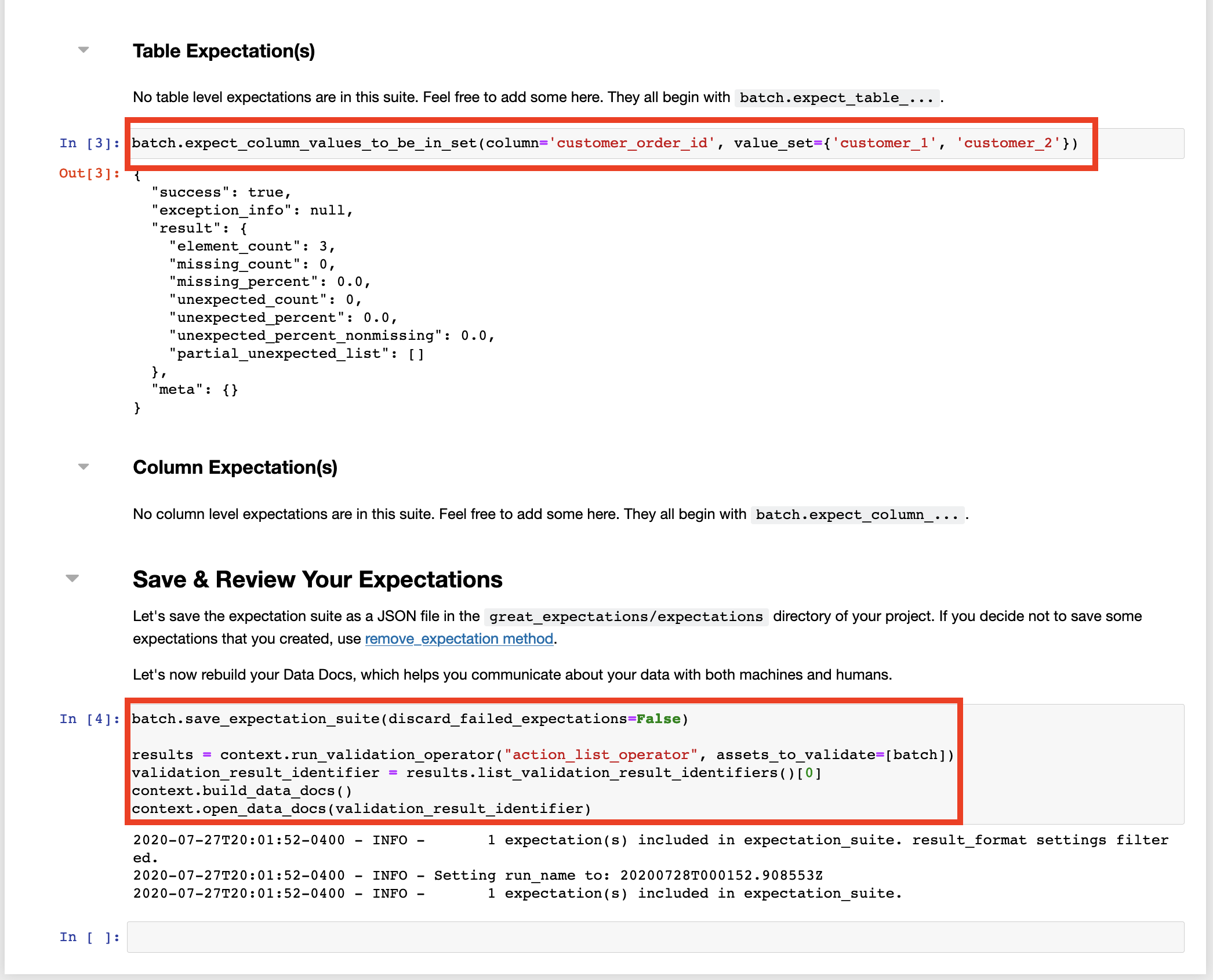
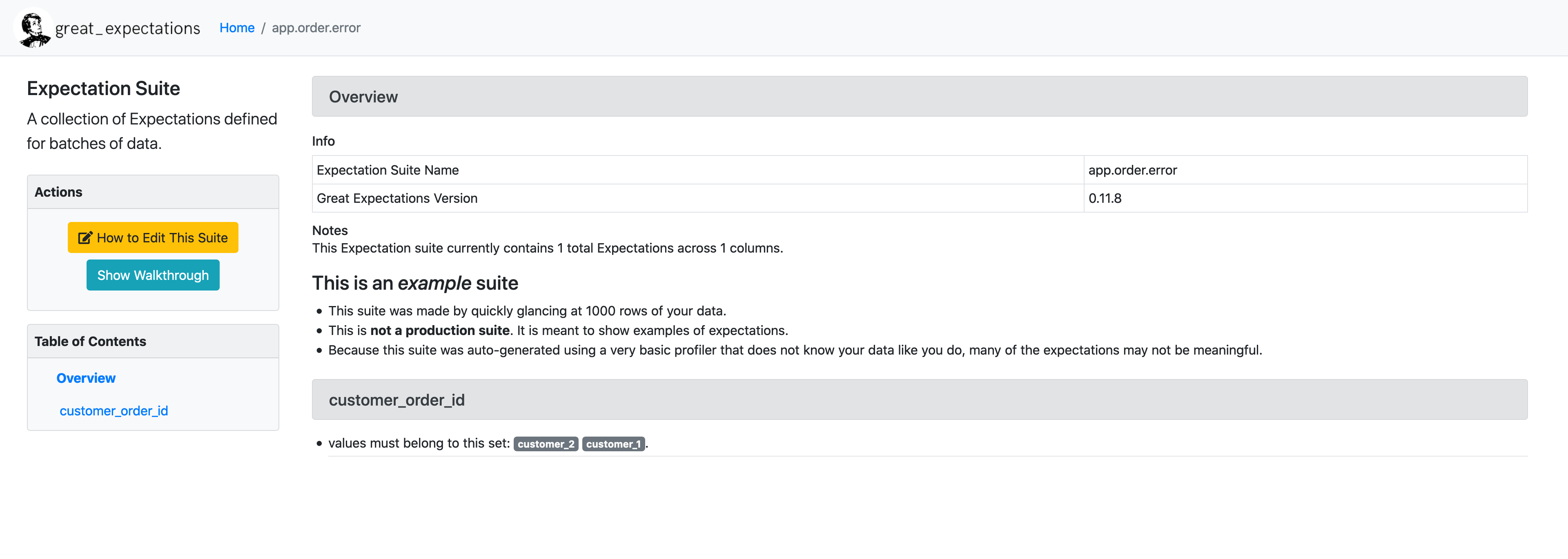
After you save the notebook, you will be taken to the newly generated data documentation UI page, where you will see the expectation you defined in human readable form.
Running your test cases (aka checkpoint)
Now its time to run our expectations, In great expectations running a set of expectations(test cases) is called a checkpoint. We have to create a checkpoint and define which expectations to run. Lets create a new checkpoint called first_checkpoint for our app.order.error expectation as shown below.

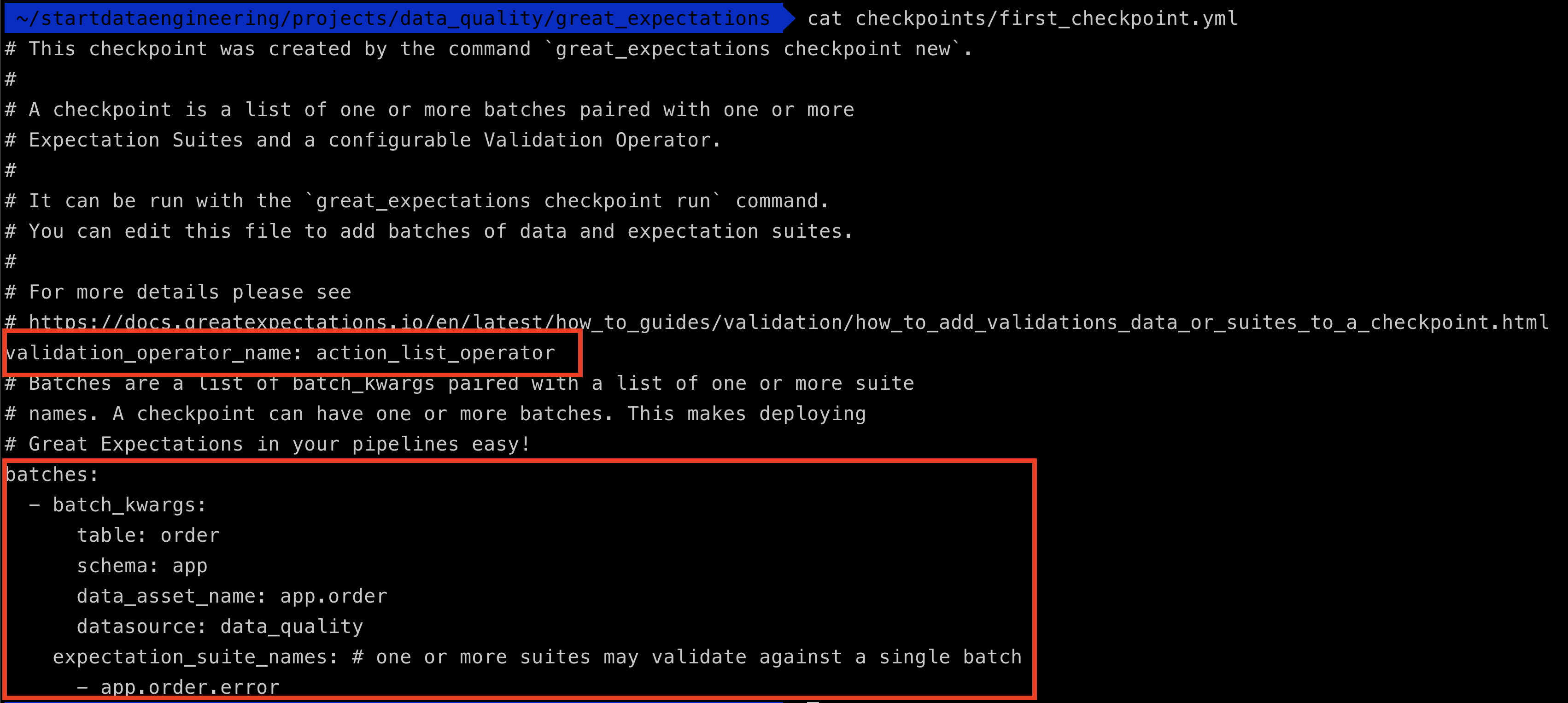
Let’s take a look at our checkpoint definition, by looking at the yml file contents
You can see the validation_operator_name which points to a definition in great_expectations.yml (which we will see next) and the batches where you defined the data source and what expectations to run against it (currently we only have it set up for app.order.error).
Let’s take a look at the validation_operators section in great_expectations.yml, this defines what needs to be done when a checkpoint is run with the action_list_operator as its validator.
You can see out action_list_operator defined and all the actions it contains.

Let’s run our checkpoint using

Now let’s see what happens when a checkpoint fails. Let’s login to postgres using pgcli and insert a customer id customer_10, that we know will fail because we have specified in our expectation that customer_id column should only have the values
Log in to postgres
Run checkpoint again, this time it should fail

As expected it failed. Right now the result of checkpoint is stored locally in the uncommited folder, which is not pushed to the source repo. But we can configure the results of the validation to be stored in a database such as postgres. To do this, we add the postgres as a valid validations_postgres_store in the great_expectations.yml file.
Let’s add a new validations_postgres_store under the stores: section and change validations_store_name to validations_postgres_store to let great_expectations know that we are using a new store (postgres db in our case) to store the results of our validation.
stores:
validations_store:
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
+ validations_postgres_store:
+ class_name: ValidationsStore
+ store_backend:
+ class_name: DatabaseStoreBackend
+ credentials: ${data_quality}
-validations_store_name: validations_store
+validations_store_name: validations_postgres_storeVerify that the store has been added as shown below
- name: expectations_store
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
- name: validations_store
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
- name: validations_postgres_store
class_name: ValidationsStore
store_backend:
class_name: DatabaseStoreBackend
credentials:
database: data_quality
drivername: postgresql
host: localhost
password: ******
port: 5432
username: sde
- name: evaluation_parameter_store
class_name: EvaluationParameterStorelet’s run the checkpoint again to see if our validation results are being stored in postgres.
In postgres, great_expectations will create a table called ge_validations_store in the public schema.
You will see the JSON below, which shows the results of the expectation that was run at checkpoint. You will see detailed report of the failure, cause by customer_id_10 under the partial_unexpected_counts value.
{
"statistics":
{
"evaluated_expectations": 1,
"successful_expectations": 0,
"unsuccessful_expectations": 1,
"success_percent": 0.0
},
"meta":
{
"great_expectations.__version__": "0.11.8",
"expectation_suite_name": "app.order.error",
"run_id":
{
"run_time": "2020-07-28T00:41:46.026887+00:00",
"run_name": "20200728T004146.026887Z"
},
"batch_kwargs":
{
"table": "order",
"schema": "app",
"data_asset_name": "app.order",
"datasource": "data_quality"
},
"batch_markers":
{
"ge_load_time": "20200728T004145.998210Z"
},
"batch_parameters": null,
"validation_time": "20200728T004146.027301Z"
},
"results":
[
{
"result":
{
"element_count": 4,
"missing_count": 0,
"missing_percent": 0.0,
"unexpected_count": 1,
"unexpected_percent": 25.0,
"unexpected_percent_nonmissing": 25.0,
"partial_unexpected_list": ["customer_10"],
"partial_unexpected_index_list": null,
"partial_unexpected_counts": [{"value": "customer_10", "count": 1}]
},
"exception_info":
{
"raised_exception": false,
"exception_message": null,
"exception_traceback": null
},
"meta": {},
"success": false,
"expectation_config":
{
"expectation_type": "expect_column_values_to_be_in_set",
"meta": {},
"kwargs":
{
"column": "customer_order_id",
"value_set": ["customer_2", "customer_1"],
"result_format": {"result_format": "SUMMARY"}}
}
}
],
"evaluation_parameters": {},
"success": false
}scheduling
Now that we have seen how to run tests on our data, we can run our checkpoints from bash or a python script(generated using great_expectations checkpoint script first_checkpoint). This lends itself to easy integration with scheduling tools like airflow, cron, prefect, etc.
Production deploy
When deploying in production, you can store any sensitive information(credentials, validation results, etc) which are part of the uncommitted folder in cloud storage systems or databases or data stores depending on your infratructure setup. Great Expectations has a lot of options for storage as shown here
When not to use a data quality framework
This tool is great and provides a lot of advanced data quality validation functions, but it adds another layer of complexity to your infrastructure that you will have to maintain and trouble shoot in case of errors. It would be wise to use it only when needed.
In general
- Do not use a data quality framework, if simple SQL based tests at post load time works for your use case.
- Do not use a data quality framework, if you only have a few (usually < 5) simple data pipelines.
Conclusion
Hope this article gives you an idea of how to use the great_expectations data quality framework, when to use it and when not to use it. Let me know if you have any questions or comments in the comment section below.