1. Introduction
Data is a mess at most companies. Data teams face multiple issues, such as handling human-edited Excels, duplicated metric definitions, incorrect source data, no data governance, lack of infrastructure, etc. If you
Wonder if data at every company is still a mess?
Hope to find a better place to work with better data development practices.
Believe analytic warehouses that are a complete, unmitigated nightmare?
Job hop hoping to find a mythical, “mature organization” where you’d learn how to do things right?
Believe that data warehouse is shit everywhere?
Then this post is for you! Imagine if your data warehouse runs like a well-oiled machine with correct data and is super easy to use! Your work will be satisfying, and your career growth will be quick; this is what the post aims to help you achieve.
In this post, we will go over six critical steps to building (& maintaining) a data warehouse that gives stakeholders everything they may need while avoiding messy data.
2. Six Steps for a Clean Data Warehouse
In this section, we will go over six steps to help you build a great data warehouse. While following these steps in order is ideal, in real projects, you may have to switch it up based on your unique situation.
While some of the below sections are non-technical, nailing them will get the data team more resources (time or money), which will help you avoid shortcuts that usually lead to messy data.
2.1. Understand the business
Before designing any system, the first thing to know is how your company makes money. Understanding the economics behind your company’s work, such as its customers, partners, and the products it sells, is critical to everything you do as a data engineer.
Understanding the business will not only inform you of the data model but also the metrics that are important to your stakeholders, the business units (or tables) to prioritize, etc. While you can read the company website to understand the business, it’s best to speak with a business person to learn about these in detail. Here are a few questions that you can ask to get you started:
- what is the business, how does it make money, where does it spend money?
- what are the business entities(e.g. seller, buyer, etc) & how do they interact with each other?
- what are the business processes that happen (e.g., clicks, checkouts, delivery, etc)?
- What data is used to calculate the bottom line of the company? Look for company-level KPIs, metrics, etc.
- What is the highest business priority for the next quarter, next year, and the next five years?
While the above questions may look simple, more often than not, the questions may take multiple meetings (depending on company size) to answer. Almost always, there is no up-to-date documentation, and you will need to speak to the product managers/engineers to understand the current and future planned state.
Note: For DEs in large companies, understand the vertical you serve first, as it may be almost impossible to understand the entire business.
The outcome of this step is for you to have a conceptual data model (CDM) that represents how business entities interact with each other.
For example, consider this simple CDM for an e-commerce website.
2.2. Make data easy to use with the appropriate data model
Once you have a good understanding of the business, the next step is to create a data model for analytical use cases. Proper data modeling is a critical component of a well-functioning data warehouse. Good data modeling enables easy-to-write analytical queries, the ability to analyze data at a specific time, making adding new tables/columns simpler, and is easy to understand for a non-data person.
A bad data model is a pain to use & maintain and will lead to messy data. While there are multiple ways to model a warehouse, we will review the popular Kimball dimensional modeling. With modern data systems, there are three main concepts:
Facts and Dimension Tables:- Dimensions refer to a table with data for a business entity (e.g., customer, product, partner, etc). The dimension tables are typically named dim_noun.
- Facts refer to how the business entities interact with each other in real life (e.g., customer - purchases - product). The fact tables are typically named fct_verbs. The key idea is to store real-life interaction at the lowest possible granularity; when a customer checks out five products, we create one row per customer-product interaction (referred to as the grain of the table). Having data at the lowest possible grain allows us to dissect data in any way as needed.
Joins: The fact tables usually join with multiple dimension tables. When there are many-to-many relationships between dimensions, use a bridge table. Joins between fact tables are tricky; be careful of query cost.Data Marts with OBTs (One Big Table):A data mart usually represents data presented to a specific business vertical. A data mart can have one or more OBTs, which are formed by joining fact and dimension tables and aggregating to the required granularity; it also involves calculating metrics. While stakeholders can join fact and dimension tables and get the data, it is desirable to provide them with a single table with all the columns that they need. Providing a single table ensures that any metric calculations needed stay in one place (vs. in a myriad of BI tools) and are consistent across multiple stakeholder teams.
An added benefit of good data modeling is simpler data lineage.
Let’s look at a simple warehouse model shown below. In this flow, we validate data before using them (& before making them available for consumers), model the data right, have a source of truth data & metrics for downstream consumption, and trace data usage. In the following sections, we will see why these concepts are critical.
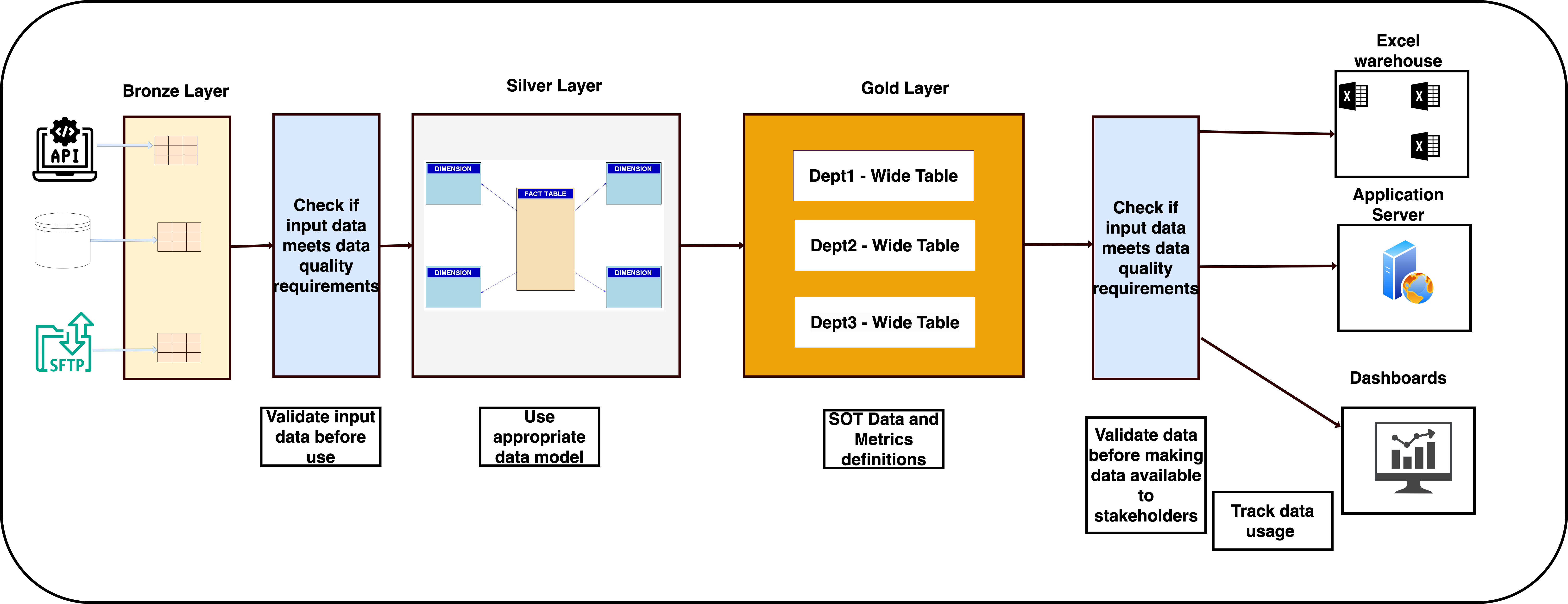
In the above warehouse, we use bronze/silver/gold layers to transform data progressively, see here for information about progressively transforming data.
2.3. Good input data is necessary for a good data warehouse
No matter how good your data model and pipelines are, if your input data is wrong, the data in your warehouse will be unusable (Garbage In, Garbage Out).
It’s critical to ensure that your input datasets are meeting your expectations before you use them in your data pipelines. Use the five verticals below to define expectations for your input data.
Data Freshness: Is the data as recent as expected?Data Types: Does the input data type change? Have columns been added/modified without notifying the data team?Data Constraints: Does the input data respect constraints such as uniqueness, non-null, relationship, and enum set?Data Size Variance: Does the input data size remain consistent across loads (or overtime periods)?Data Metric Variance: Do the critical metrics in the input data remain consistent across loads (or overtime periods)?
Once defined, ensure that the input data meets the expectations before processing them. If you identify any issues, work with upstream teams to address them (these formalized checks are called data contracts).
Never use bad data to build your data models, no matter the pushback from upstream teams, since you will be responsible for bad data!
2.4. Define Source of Truth (SOT) and trace its usage
“The numbers look different” is a huge problem that most data teams face. The difference in data used, its freshness, or how the end user calculated a metric are the common sources of metric mismatch. Use the steps below to alleviate this issue.
SOT Metric Definition: Define the metric in the data mart(managed by the data team) layer. Having metrics defined in one place and used by stakeholders ensures everyone uses the same metric.SOT Data: The stakeholders should only (ideally) use the data from the data mart layer. SOT Data ensures that all the stakeholders see consistent data. If they use data from any facts and dims table, ensure they know the join logic and possible filters.SOT Data Lineage: Ensure you track which teams use the data from the data mart. This traceability will enable the stakeholders to resolve any metric mismatch that may have occurred between their dashboards. E.g., dbt data lineage
2.5. Keep stakeholders in the loop for a more significant impact
Keeping your stakeholders aware of the why, what, and how of building a data warehouse will ensure they are excited (or at least familiar) about potential upgrades that will make their lives easier. You can create an immaculate data warehouse, but without the data team conveying its need & importance to a broader audience in the company, it will never be a top priority for the leadership team. The more the buy-in from stakeholders, the more resources (time, DEs) that you will get.
Here are four steps to maximize your chances of building an impactful data warehouse:
Need or Pain: Before you build/improve your warehouse, ensure a strong need/pain. For example, data is spread across multiple databases and can’t be analyzed together easily; analytical queries could be faster and impact production performance, data strategy for the company, etc. If there is no need for a warehouse, most leadership will see your work as a cost center.Awareness: Non-data team members need to know what you are building and what problem it solves. Ensure to send out emails, demos, etc, to make people aware of the project. If people ask for additional features/new datasets, that is a good sign, as it shows people’s interest in what you are building. Another thing to be mindful of is alignment across teams, especially with the upstream teams. Ensure that the necessary (usually upstream & end-user) teams are aligned on the vision for the warehouse.Expectation setting: It’s critical to set expectations of what you will deliver and when. While it is hard to create an accurate timeline, making estimates with an additional 20-40% time buffer (depending on lack of clarity) works best. Deliver iteratively, deliver by business unit, or sets of facts/dim tables, etc. Do not wait to deliver until the entire warehouse is done. Provide periodic updates and keep stakeholders in the loop via email, JIRA, etc.Evangelize: Make sure to demo/do presentations of the benefits of the data warehouse, show before/after query speeds, and make pretty charts that show speed going up, people cost going down, etc, to show impact.
2.6. Watch out for org-level red flags 🚩
While you can control what you work on, if you notice these (in addition to the usual signs) red flags and they don’t change, it’s best to move to a new job.
No leadership buy-in: If the leadership does not care about data, things will not change.Constant reorgs: You will be overworked, projects may be axed, morale will be low, etcNo Data team: If you are the first hire unless you are hired to build a data team and you know that leadership highly values data, do not join(or leave).Misaligned teams with competing objectives: If data and other teams have competing goals, resolve them before working on any initiative. Misaligned goals will cause issues, distrust, and a toxic work environment. If this is a recurring pattern, it may be time to find a new job.
3. Conclusion
Data utopia does not exist; there is no mythical mature organization where the data warehouse is perfect, and there will always be some issues with the data. But, we, as data engineers, have the ability & responsibility to clean up the mess, build a great data warehouse, and make data accessible for the company.
To recap, we saw how to
2. Make data easy to use, with the right data model
3. Good input data is necessary for a good data warehouse
4. Define Source of Truth (SOT), and trace its usage
5. Keep stakeholders in the loop for bigger impact
6. Watch out for org level red-flags 🚩
The next time you are building/improving a data warehouse, use the concepts above as a starting point to create a data warehouse that works smoothly, & is a joy to work on.
If you have any questions or comments, please leave them in the comment section below.