graph TD
A(Source System 1) --> B[Extract]
A2(Source System 2) --> B
A3(Source System 3) --> B
A4(Source System 4) --> B
B --> C[Transform]
C --> D[Load]
D --> E[Destination System]
Introduction
You know Python is important for data engineers. But what does knowing Python mean for data engineering? Python is a programming language that supports a wide range of functions; how would you know if you know it well enough for data engineering? If you have
Wondered what aspects of Python you’d need to know to become a data engineer
Questioned your ability to learn Python, especially since Python keeps on adding new things
How to use Python practically for data engineering
Imagine if you could deliver data pipelines that are a joy to maintain.
This post is for you. In it, we will go over the concepts you need to know to use Python effectively for data engineering. Each concept has an associated workbook for practice.
Data is stored on disk and processed in memory
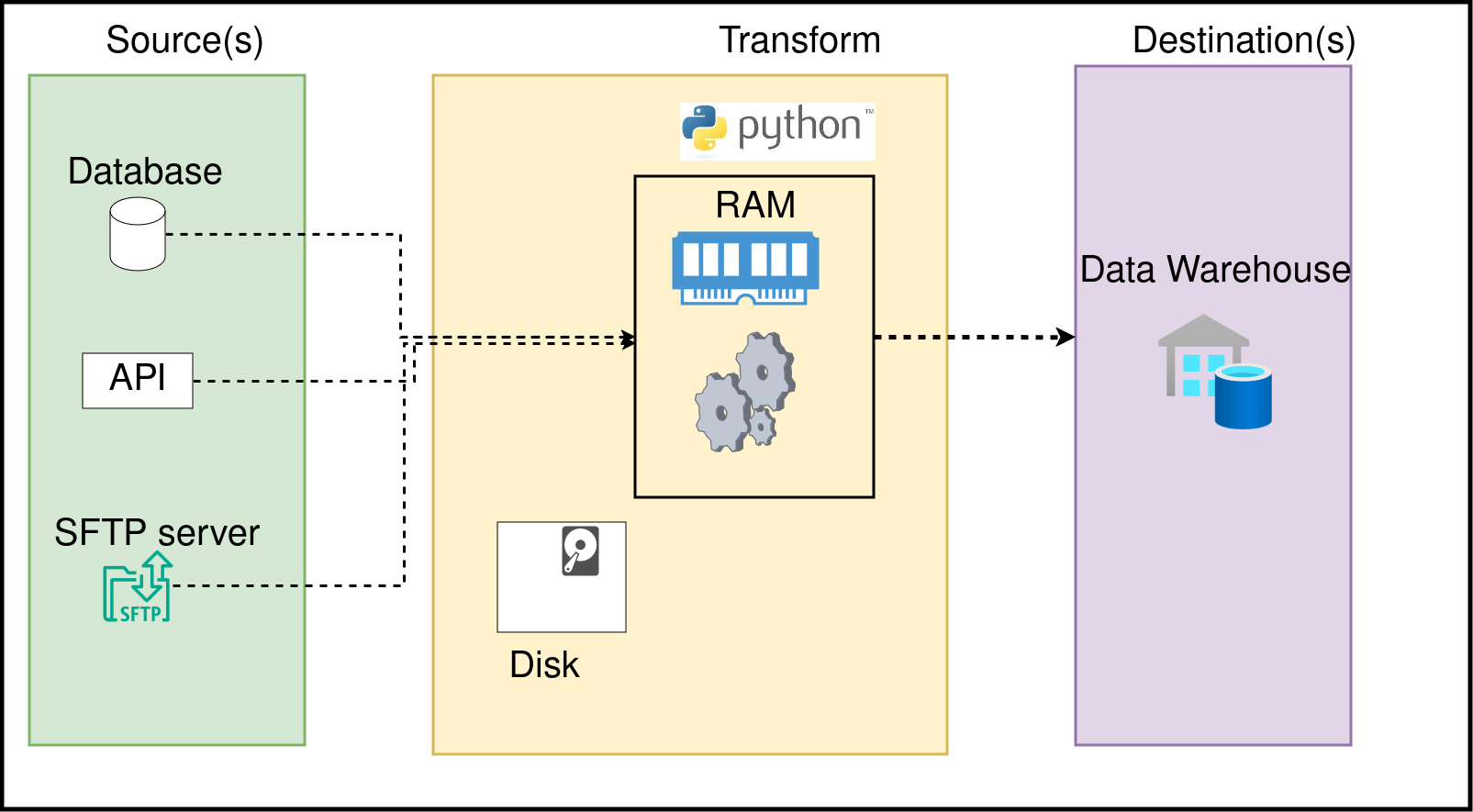
When we run a Python (or any language) script, it is run as a process. Each process will use a part of your computer’s memory (RAM). Understanding the difference between RAM and Disk will enable you to write efficient data pipelines; let’s go over them:
Memoryis the space used by a running process to store any information that it may need for its operation. The computer’s RAM is used for this purpose.Diskis used to store data. When we process data from disk (read data from csv, etc) it means that our process is reading data from disk into memory and then processing it. Computers generally use HDD or SSD to store your files.
RAM is expensive, while disk (HDD, SSD) is cheaper. One issue with data processing is that the memory available to use is often less than the size of the data to be processed. This is when we use distributed systems like Spark or systems like DuckDB, which enable us to process larger-than-memory data.
Practicing Python
For information on how to run the code checkout the code repository at: python_essentials_for_data_engineers
Each topic will have an associated workbook. The workbooks will state some questions you must research (chatGPT, Google) to find the answers to (much like real life!). While the workbooks have solutions, there are multiple ways to do the same thing, and as long as you get the correct answer, you should be good.
The questions will be available at section-questions.py(e.g. 1-basics-questions.py) and solutions will be at section-solutions.py (e.g. 1-basics-solutions.py).
Each section also includes extras; I recommend reviewing all the workbooks and returning to the extras part.
Python basics
Type in the code vs copy-pasting it.
Workbook: Basics
Let’s go over some basics of the Python language:
Variables: A storage location identified by its name, containing some value.Operations: We can do any operation (arithmetic for numbers, string transformation for text) on variablesData Structures: They are ways of representing data. Each has its own pros and cons and places where it is the right fit. 3.1.List: A collection of elements that can be accessed by knowing the element’s location (aka index). Lists retain the order of elements in them.3.2.
Dictionary: A collection of key-value pairs where each key is mapped to a value using a hash function. The dictionary provides fast data retrieval based on keys.3.3.
Set: A collection of unique elements that do not allow duplicates.3.4.
Tuple: A collection of immutable(non changeable) elements, tuples retain their order once created.Loops: Looping allows a specific chunk of code to be repeated several times.4.1.
Comprehension: Comprehension is a shorthand way of writing a loopFunctions: A block of code that can be reused as needed. This allows us to have logic defined in one place, making it easy to maintain and use. Using it in a location is referred to as calling the function.Class and Objects: Think of a class as a blueprint and objects as things created based on that blueprint.Library: Libraries are code that can be reused. Python comes with standard libraries for common operations, such as a datetime library to work with time (although there are better libraries)—Standard library.Exception handling: When an error occurs, we need our code to gracefully handle it without stopping.
Extras:
Python is used for extracting data from sources, transforming it, & loading it into a destination
Python is typically used as a glue to control data flow in data engineering. Let’s define some key terms.
Source system: In data pipelines, you typically get data from one or more source systems. Some common examples are application databases, APIs, csv files, etcDestination system: The objective of data pipelines is to make data accessible for end users. Typically, data pipelines involve getting the data into properly modeled tables in a warehouse.Extract: Refers to getting data from the source system.Transformrefers to transforming the source data into a form accessible to the stakeholders at the destination system.Load: Refers to loading data into the destination system.
In the following sections, we will review how Python helps us perform data pipeline tasks.
Note that we will use libraries in the following sections, which are pre-written code you can import into your code.
Python has a wide range of libraries that makes using Python for most tasks easy.
[Extract & Load] Read and write data to any system
Workbook: Extracting and Loading data with Python
Python has multiple libraries that enable reading and writing to various systems.
Let’s look at the types of systems for reading and writing and how Python is used there:
Database drivers: These are libraries that you can use to connect to a database. Database drivers require you to use credentials to create a connection to your database. Once you have the connection object, you can run queries, read data from your database in Python, etc. Some examples are psycopg2, sqlite3, duckdb, etc.Cloud SDKs: Most cloud providers (AWS, GCP, Azure) provide their own SDK(Software Development Kit). You can use the SDK to work with any of the cloud services. In data pipelines, you would typically use the SDK to extract/load data from/to a cloud storage system(S3, GCP Cloud store, etc). Some examples of SDK are AWS, which has boto3; GCP, which has gsutil; etc.APIs: Some systems expose data via APIs. Essentially, a server will accept an HTTPS request and return some data based on the parameters. Python has the popularrequestslibrary to work with APIs.Files: Python enables you to read/write data into files with standard libraries(e.g.,csv). Python has a plethora of libraries available for specialized files like XML, xlsx, parquet, etc.SFTP/FTP: These are servers typically used to provide data to clients outside your company. Python has tools like paramiko, ftplib, etc., to access the data on these servers.Queuing systems: These are systems that queue data (e.g., Kafka, AWS Kinesis, Redpanda, etc.). Python has libraries to read data from and write data to these systems, e.g., pykafka, etc.
Extras:
[Transform] Process data in Python or instruct the database to process it
Workbook: Transforming data with Python
Data processing can be as simple as changing an upper-case string to a lower-case or as complex as identifying outliers in a list of values.
The main types of data processing libraries are:
Python standard libraries: Python has a strong set of standard libraries for processing data. When using standard libraries, you’ll usually be working on Python native data structures (dict, list, tuples, objects, etc.). Some popular ones are csv, json, gzip etc.Dataframe libraries: Libraries like pandas, polars, and Spark enable you to work with tabular data. These libraries use a dataframe (Python’s version of a SQL table) and enable you to do everything (and more) you can do with SQL. Note that some of these libraries are meant for data that can be processed in memory.Processing data on SQL via Python: You can use database drivers and write SQL queries to process the data. The benefit of this approach is that you don’t need to bring data into Python memory and offload it to the database.
Note: When we use systems like Spark, Dask, Snowflake, BigQuery to process data, you should note that we interact with them via Python. The bulk of the work happens inside those external systems.
[Data Quality] Define what you expect of your data and check if your data confirms it
Workbook: Data Quality checks with Python
A key requirement for most data pipelines is the ability to check the quality of the data that it produces before making it available to end users.
Python has a lot of libraries that help with data quality testing. Some of the data quality tools are:
Great Expectationsis a Python library that enables you to define and run data quality checks. Great expectations also will allow you to use multiple data processing systems (DuckDB, Spark, Snowflake, etc.) to run the data quality tests.Cualleeis a lightweight Python library that lets you define and run data quality checks. Cuallee supports multiple data processing systems to run your data quality checks. Cuallee docs.
Extras: 1. What are data quality tests 2. Data quality testing with Great Expectations
[Code Testing] Ensure your code does what it’s supposed to do
Workbook: Testing code with Python
To run pytest (under ./tests folder) you will need to run the python -m pytest ./tests command.
Testing your code ensures that your code does exactly what it is supposed to do.
Tests (different from data quality checks) are run before your code is deployed to production.
When you write code, you and your colleagues must maintain it over time. Bugs are inevitable with code changes/updates; tests will help you catch these before your code goes live!
Python has a standard library, unittest for testing. An extremely popular testing library used with Python is pytest, it is very ergonomic and has a wide range of plugin support.
Extras: 1. How to test your pipelines 2. Testing pipelines as part of CI/CD
[Scheduler] Run your code at specified times
Schedulers are used to run data pipelines at specified times (once a day, once an hour, once a week, etc). The schedulers are systems that run constantly (more accurately, run every n seconds, sleep, and run again) to check if there are any data pipelines (or any tasks) to be run, and if yes, start them.
Some of the popular schedulers are:
[Orchestrate] Control code execution order
When we run complex data pipelines, we want to run parts of them in parallel or wait for certain parts of the code to complete before running the next. This dependency is described using a DAG (Directed Acyclic Graph).
There are a lot of tools where you can write code, and the library will create the DAG for you. Some of the popular ones are
- dbt core: A tool to enable you to run sql queries in the order that you like. dbt tutorial. Ref: dbt tutorial.
- Airflow & Dagster
Conclusion
To recap, we saw how to use Python in
- Read data from and write data to various systems.
- Transfor data in memory or using a tool like Apache Spark.
- Define and run data quality checks.
- Write tests to ensure that your code does what it’s supposed to do.
- Schedule and orchestrate data pipelines.
While the amount of Python libraries may seem overwhelming, the main idea is to know that most data engineering tasks can be done with Python.
The next time you find yourself overwhelmed by all the choices of tools or SAAS vendors, use this article as a guide to finding Python libraries that can fulfill your requirements.