Introduction
Building a data project for your portfolio is hard. Getting hiring managers to read through your Github code is even harder. If you are building data projects and are
disappointed that no one looks at your Github projects
frustrated that recruiters don’t take you seriously as you don’t have a lot of work experience
Then this post is for you. In this post, we go one way to design a data project to impress a hiring manager and showcase your expertise. The main theme of this endeavor is show not tell, since you only get a few minutes(if not seconds) of the hiring manager’s time.
Objective
When starting a project, it’s a good idea to work backward from your end goal. In our case, the main goal is to impress the hiring manager. This can be done by
- Linking your dashboard URL in your resume and Linkedin.
- Hosting a live dashboard that is fed by near real-time data.
- Encouraging the hiring manager to look at your Github repository.
- Concise and succinct
README.md. - Architecture diagram.
- Project organization.
- Coding best practices: Test, lint, types, and formatting.
You want to showcase your expertise to the hiring manager, without expecting them to read through your codebase. In the following sections, we will build out a simple dashboard that is populated by near real-time bitcoin exchange data. You can use this as a reference to build your dashboards.
Setup
Pre-requisites
- git
- Github account
- Terraform
- AWS account
- AWS CLI installed and configured
- Docker with at least 4GB of RAM and Docker Compose v1.27.0 or later
Read this post, for information on setting up CI/CD, DB migrations, IAC(terraform), “make” commands and automated testing.
Run these commands to setup your project locally and on the cloud.
# Clone the code as shown below.
git clone https://github.com/josephmachado/bitcoinMonitor.git
cd bitcoinMonitor
# Local run & test
make up # start the docker containers on your computer & runs migrations under ./migrations
make ci # Runs auto formatting, lint checks, & all the test files under ./tests
# Create AWS services with Terraform
make tf-init # Only needed on your first terraform run (or if you add new providers)
make infra-up # type in yes after verifying the changes TF will make
# Wait until the EC2 instance is initialized, you can check this via your AWS UI
# See "Status Check" on the EC2 console, it should be "2/2 checks passed" before proceeding
make cloud-metabase # this command will forward Metabase port from EC2 to your machine and opens it in the browserYou can connect metabase to the warehouse with the configs in the env file. Refer to this doc for creating a Metabase dashboard.
Create database migrations as shown below.
For the continuous delivery to work, set up the infrastructure with terraform, & defined the following repository secrets. You can set up the repository secrets by going to Settings > Secrets > Actions > New repository secret.
SERVER_SSH_KEY: We can get this by runningterraform -chdir=./terraform output -raw private_keyin the project directory and paste the entire content in a new Action secret called SERVER_SSH_KEY.REMOTE_HOST: Get this by runningterraform -chdir=./terraform output -raw ec2_public_dnsin the project directory.REMOTE_USER: The value for this is ubuntu.
Project
For our project, we will pull bitcoin exchange data from CoinCap API. We will pull this data every 5 minutes and load it into our warehouse.
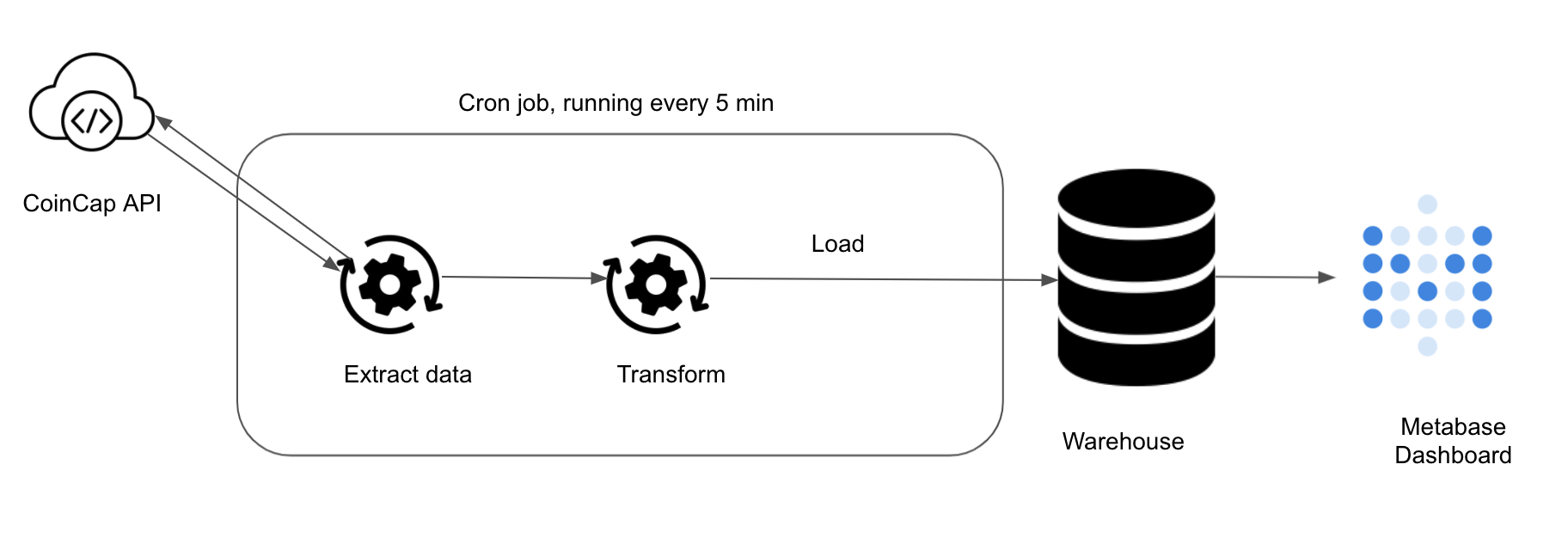
1. ETL Code
The code to pull data from CoinCap API and load it into our warehouse is at exchange_data_etl.py. In this script we
- Pull data from CoinCap API using the
get_exchange_datafunction. - Use
get_utc_from_unix_timefunction to get UTC based date time from unix time(in ms). - Load data into our warehouse using the
_get_exchange_insert_queryinsert query.
Ref: API data pull best practices
There are a few things going on at “**with WarehouseConnection(**get_warehouse_creds()).managed_cursor() as curr:**“.
- We use the get_warehouse_creds utility function to get the warehouse connection credentials.
- The warehouse connection credentials are stored as environment variables within our docker compose definition. The docker-compose uses the hardcoded values from the env file.
- The credentials are passed as **kwargs to the WarehouseConnection class.
- The WarehouseConnection class uses
contextmanagerto enable opening and closing the DB connections easier. This lets us access the DB connection without having to write boilerplate code.
class WarehouseConnection:
def __init__(
self, db: str, user: str, password: str, host: str, port: int
):
self.conn_url = f'postgresql://{user}:{password}@{host}:{port}/{db}'
@contextmanager
def managed_cursor(self, cursor_factory=None):
self.conn = psycopg2.connect(self.conn_url)
self.conn.autocommit = True
self.curr = self.conn.cursor(cursor_factory=cursor_factory)
try:
yield self.curr
finally:
self.curr.close()
self.conn.close()2. Test
Tests are crucial if you want to be confident about refactoring code, adding new features, and code correctness. In this example, we will add 2 major types of tests.
- Unit test: To test if individual functions are working as expected. We test
get_utc_from_unix_timewith the test_get_utc_from_unix_time function. - Integration test: To test if multiple systems work together as expected.
For the integration test we
- Mock the Coinbase API call using the
mockerfunctionality of thepytest-mocklibrary. We use fixture data attest/fixtures/sample_raw_exchange_data.csvas a result of an API call. This is to enable deterministic testing. - Assert that the data we store in the warehouse is the same as we expected.
- Finally the
teardown_methodtruncates the local warehouse table. This is automatically called by pytest after thetest_covid_stats_etl_runtest function is run.
class TestBitcoinMonitor:
def teardown_method(self, test_covid_stats_etl_run):
with WarehouseConnection(
**get_warehouse_creds()
).managed_cursor() as curr:
curr.execute("TRUNCATE TABLE bitcoin.exchange;")
def get_exchange_data(self):
with WarehouseConnection(**get_warehouse_creds()).managed_cursor(
cursor_factory=psycopg2.extras.DictCursor
) as curr:
curr.execute(
'''SELECT id,
name,
rank,
percenttotalvolume,
volumeusd,
tradingpairs,
socket,
exchangeurl,
updated_unix_millis,
updated_utc
FROM bitcoin.exchange;'''
)
table_data = [dict(r) for r in curr.fetchall()]
return table_data
def test_covid_stats_etl_run(self, mocker):
mocker.patch(
'bitcoinmonitor.exchange_data_etl.get_exchange_data',
return_value=[
r
for r in csv.DictReader(
open('test/fixtures/sample_raw_exchange_data.csv')
)
],
)
run()
expected_result = [
{"see github repo for full data"}
]
result = self.get_exchange_data()
assert expected_result == resultSee How to add tests to your data pipeline article to add more tests to this pipeline. You can run tests using
3. Scheduler
Now that we have the ETL script and tests setup. We need to schedule the ETL script to run every 5 minutes. Since this is a simple script we will go with cron instead of setting up a framework like Airflow or Dagster. The cron job is defined at scheduler/pull_bitcoin_exchange_info
This file is placed inside the pipelinerunner docker container’s crontab location. You may notice that we have hardcoded the environment variables. Not having the environment variables hardcoded in this file is part of future work.
4. Presentation
Now that we have the code and scheduler set up, we can add checks and formatting automation to ensure that we follow best practices. This is what a hiring manager will be exposed to, when they look at your code. Ensuring that the presentation is clear, concise, and consistent is crucial.
4.1. Formatting, Linting, and Type checks
Formatting enables us to stay consistent with the code format. We use black and isort to automate formatting. The -S black module flag ensures that we use single quotes for strings (following PEP8).
Linting analyzes the code for potential errors and ensures that the code formatting is consistent. We use flake8 to lint check our code.
Type checking enables us to catch type errors (when defined). We use mypy for this.
All of these are run within the docker container. We use a Makefile to store shortcuts to run these commands.
4.2. Architecture Diagram
Instead of having a long text, it is usually easier to understand the data flow with an architecture diagram. It does not have to be beautiful, but must be clear and understandable. Our architecture diagram is shown below.
4.3. README.md
The readme should be clear and concise. It’s a good idea to have sections for
- Description of the problem
- Architecture diagram
- Setup instructions
You can automatically format and test your code with
After which, you can push it to your Github repository.
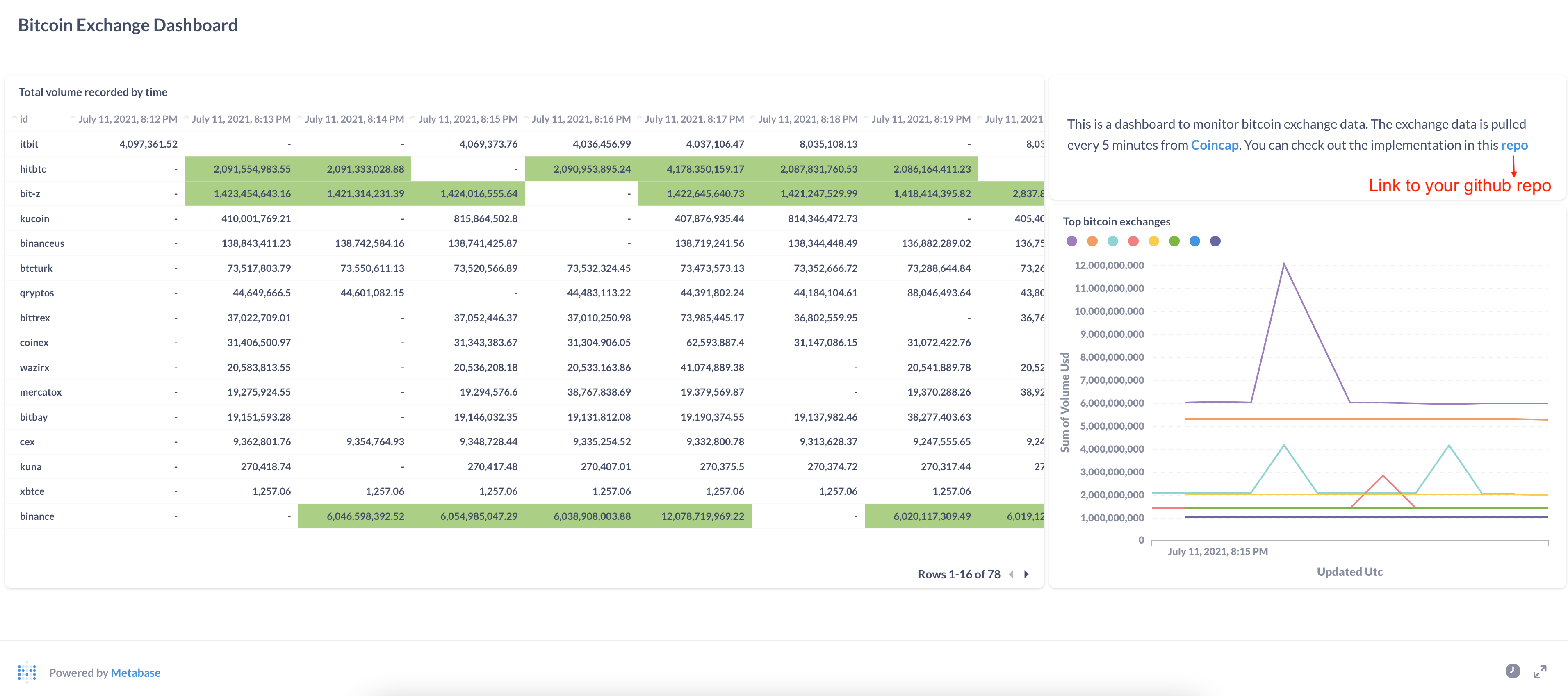
5. Adding Dashboard to your Profile
Refer to Metabase documentation on how to create a dashboard. Once you create a dashboard, get its public link following the steps here. Create a hyperlink to this dashboard from your resume or LinkedIn page. You can also embed the dashboard as an iframe on any website.
A sample dashboard using bitcoin exchange data is shown below.
Depending on the EC2 instance type you choose you may occur some cost. Use AWS cost calculator to figure out the cost.
Future Work
Although this provides a good starting point, there is a lot of work to be done. Some future work may include
- Data quality testing
- Better scheduler and workflow manager to handle backfills, reruns, and parallelism
- Better failure handling
- Streaming data from APIs vs mini-batches
- Add system env variable to crontab
- Data cleanup job to remove old data, since our Postgres is running on a small EC2 instance
- API rate limiting
Tear down infra
After you are done, make sure to destroy your cloud infrastructure.
Conclusion
Building data projects are hard. Getting hiring managers to read through your Github code is even harder. By focusing on the right things, you can achieve your objective. In this case, the objective is to show your data skills to a hiring manager. We do this by making it extremely easy for the hiring manager to see the end product, code, and architecture.
Hope this article gave you a good idea of how to design a data project to impress a hiring manager. If you have any questions or comments please leave them in the comment section below.