1. Introduction
Data pipelines can have multiple software components. This makes testing all of them together difficult. If you are wondering
What is the best way to end-to-end test data pipelines?
Are end-to-end tests worth the effort?
Then, this post is for you. In this post, we go over some techniques that you can use to set up end-to-end tests for your data pipelines. End-to-end tests can help avoid regression and make your data pipelines a joy to work with, by providing quick feedback.
If you are unfamiliar with what end-to-end tests are, checkout this article.
2. Setting up services locally
Most data pipelines usually use a mix of open-source, vendor software, and platform services. Running all of them locally may not always be possible. The table below provides alternatives for your pipeline components.
| Component type | Examples | How to simulate component locally |
|---|---|---|
| Open source software (OSS) | Airflow, Spark, Kafka, etc | Run locally, preferably as a docker container |
| Managed services | ——————————– | ——————————– |
| Managed open-source | Astronomer, AWS EMR, AWS RDS Postgres, Python runtime on AWS EC2, etc | Run the OSS service locally, preferably as a docker container |
| PAAS (Platform as a service) | AWS Lambda, AWS IAM, GCP Cloud compute, APIs to manage resources, etc | Use a library like Moto, or build custom mocks with pytest, etc, When applicable you can use services like AWS SAM, GCP Pub/Sub emulator |
| SAAS (closed source ) | Snowflake, AWS Redshift, etc | Use OSS alternative, if possible (E.g. Postgres instead of AWS Redshift). Note OSS cannot be used to test SAAS-specific features. Frameworks like dbt allow for local testing on warehouse |
3. Writing an end-to-end data pipeline test
Let’s assume we have an event-driven data pipeline. We have an SFTP server that accepts data from vendors. We copy data from SFTP to S3 using a python process running on an EC2 instance. When a new file is created in our S3 bucket, it triggers a lambda process. The lambda reads data from the S3 file and inserts it into a warehouse table.
This is what our data pipeline architecture looks like.

For our local setup, we will use
- Open source sftp server
- Moto server to mock S3 and Lambda
- Postgres as a substitute for AWS Redshift

The project structure is shown below.
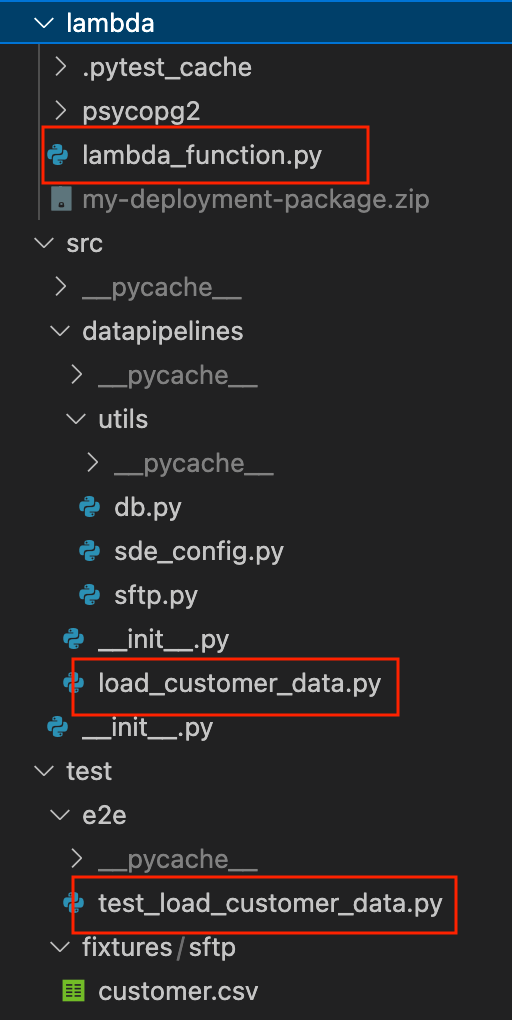
In the project
load_customer_data.pyis the main ETL function, it copies data from the SFTP server to an S3 file.utilsfolder has helper functions to connect to different components.lambda_function.pyreads data from the S3 file and inserts it into a warehouse table. This will be the code deployed in our lambda function.test_load_customer_data.pyruns the ETL and tests that the data in./test/customer/fixtures/sftp/customer.csvthat we put in the local sftp server, make it into the warehouse table.
To run the project you will need
Clone, create a virtual env, set up python path, spin up containers and run tests as shown below.
git clone https://github.com/josephmachado/e2e_datapipeline_test.git
python -m venv ./env
source env/bin/activate # use virtual environment
pip install -r requirements.txt
make up # spins up the SFTP, Motoserver, Warehouse docker containers
export PYTHONPATH=${PYTHONPATH}:./src # set path to enable imports
pytest # runs all tests under the ./test folderA key thing to note in the code is the function get_aws_connection, which provides the AWS connection credentials. When developing locally, this will point to the locally running Moto server. The credentials are stored in the .env.local file and loaded in through sde_config.py.
To tear down the container and deactivate your virtual environment, use the commands shown below.
4. Conclusion
Setting up end-to-end data pipeline tests can take a long time depending on your stack. Despite its difficulties, the end-to-end test can provide a lot of value when you modify your data pipelines and want to ensure that you do not introduce any bugs. A few points to keep in mind when setting up end-to-end tests are
Be aware of what exactly you are testing. It might not be the best use of time to mock automatic triggering/queuing systems locally, since one can be pretty confident that this will be handled by the cloud provider.
If you are using vendor services (E.g. Snowflake, Redshift, etc), it might be acceptable to use an OSS such as Postgres to mock the data warehouse. However, this can be difficult if you end up using service-specific functions. E.g. Snowflake’s QUALIFY
Generally, end-to-end tests take a longer time to run compared to unit and integration tests. Use google’s test pyramid to get an idea of the number of units, integration, and end to end tests to write.
If you are short on time, concentrate on writing unit tests for the complex, error-prone, and critical pipeline components, before setting up an end-to-end test.
Hope this article gives you a good understanding of how to set up end-to-end tests for your data pipeline and what its pros and cons are. The code is available here. If you have any questions or comments please leave them in the comment section below.