1. Introduction
If you are a student, analyst, engineer, or anyone working with data pipelines, you would have heard of ETL and ELT architecture. If you have questions like
What is the difference between ETL & ELT?
Should I use ETL or ELT pattern for my data pipeline?
Then this post is for you. In this post, we go over the definitions and differences between ETL and ELT.
2. E-T-L definition
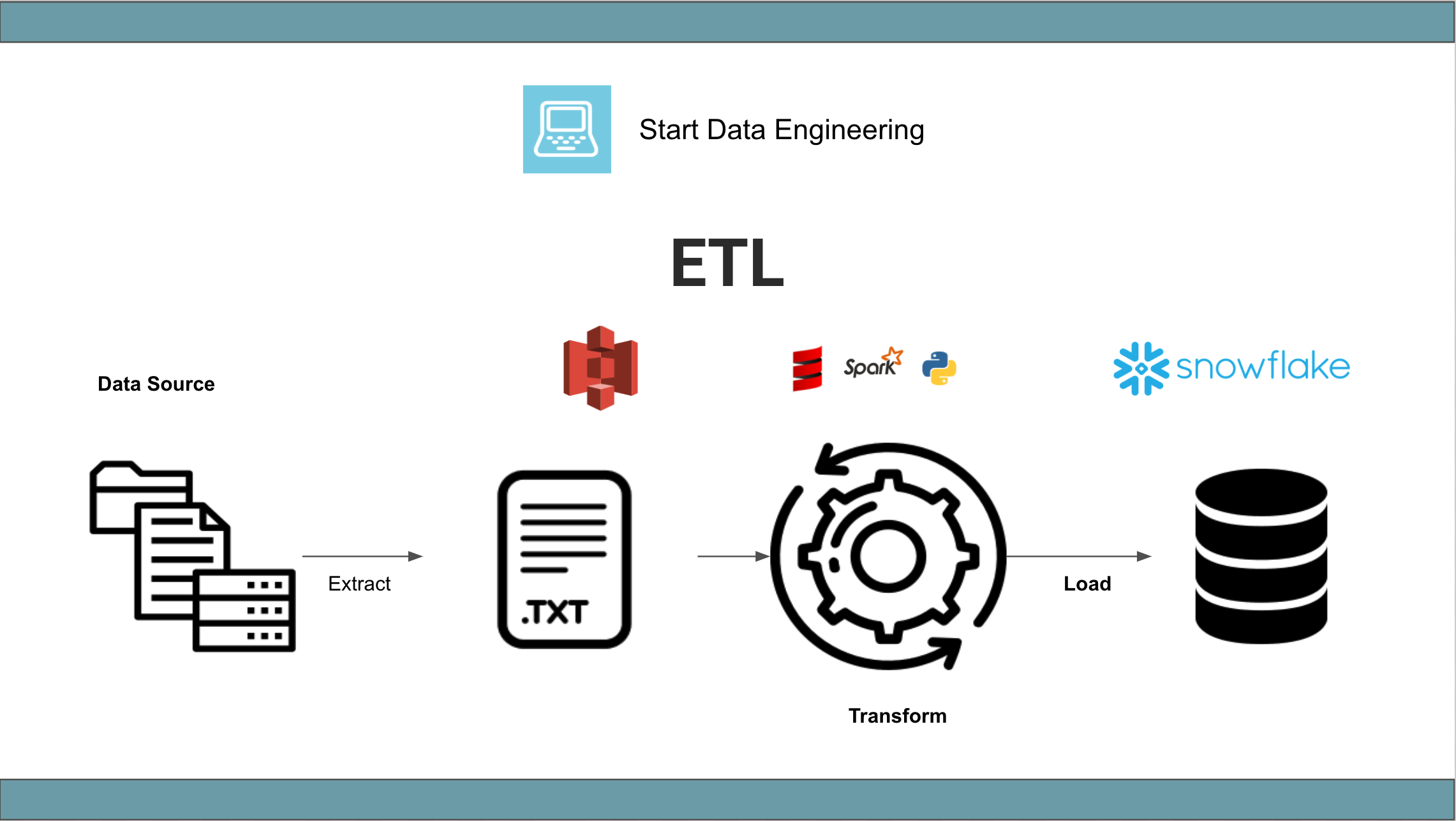
ETL refers to extract, transform and load.
Extract: The process of getting the data from the source system. E.g., a python process to get data from an API, access data from an OLTP database, etc.Transform: The process of transforming the extracted data. E.g., changing field types & names, applying business logic to the data set, enriching data, etc.Load: The process of loading the transformed data into the data asset used by the end-user.
3. Differences between ETL & ELT
Traditionally ETL has been used to refer to any data pipeline where data is pulled from the source, transformed, and loaded into the final table for use by the end-user. The transformation could be in python, Spark, Scala, SQL in the data warehouse, etc.
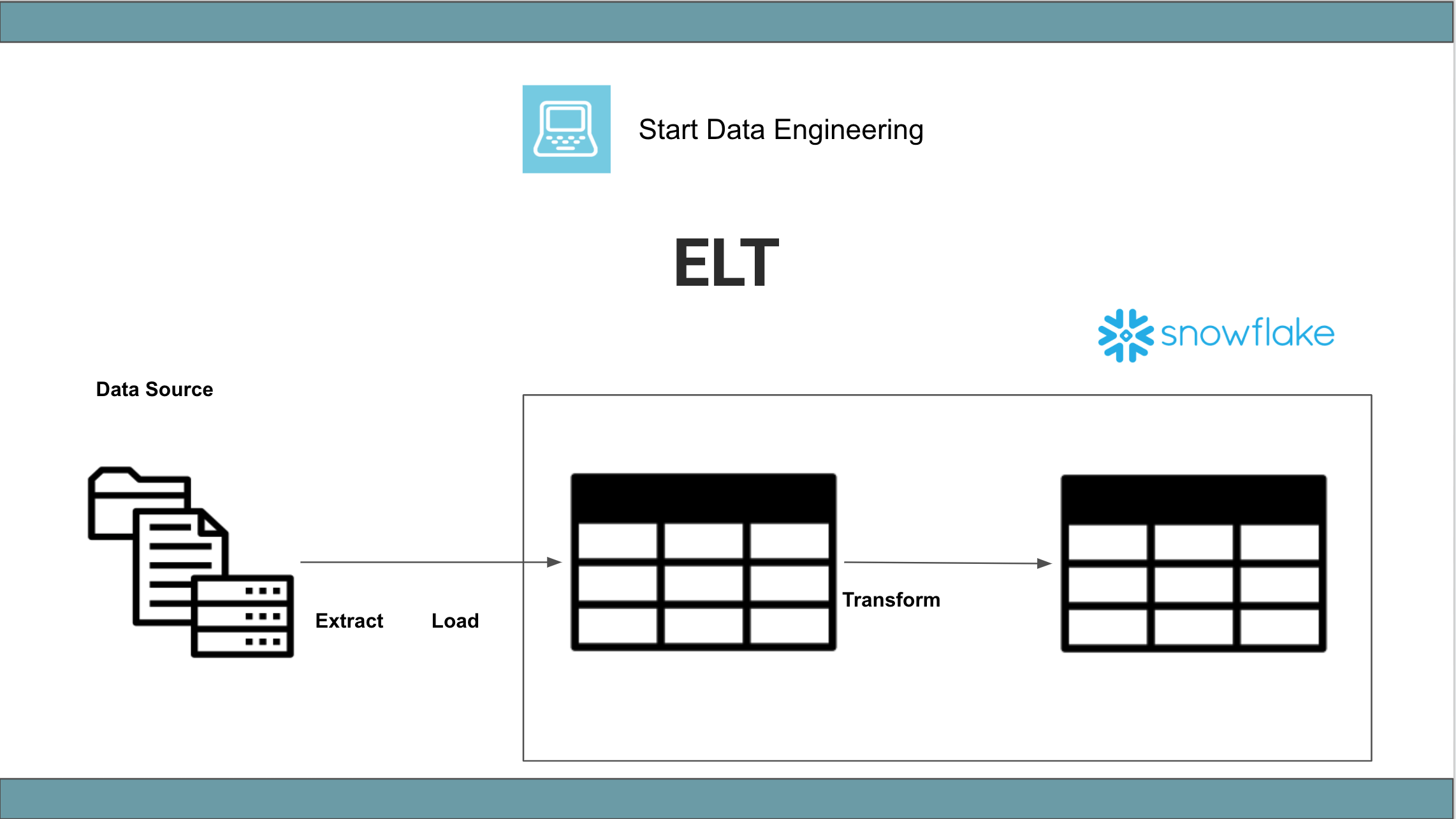
Recently, ELT has been used to refer to data pipelines where the data is transformed in the data warehouse. This can be confusing since, by definition, this is an ETL pipeline with transformation done using SQL in the data warehouse. What people mean when they say ETL and ELT:
- ETL: The raw data is stored in some file storage (s3, local, etc), transformed with a
python/spark/scalaor other non-sql languages, and loaded into the tables to be used by the end-user. - ELT: The raw data is loaded into the data warehouse and transformed using SQL into the final table to be used by the end-user.
| ETL | ELT |
|---|---|
 |
 |
Let’s compare ETL and ELT.
| Criteria | Notes | ELT | ETL |
|---|---|---|---|
| Running cost | Depending on your data warehouse, performing transformation using k8s tasks or serverless functions(lambdas) can be much cheaper compared to transforming data in your data warehouse. | ✔️ | |
| Engineering expertise | Both require a good grasp of distributed systems, coding, maintenance, debugging, and SQL. | ✔️ | ✔️ |
| Development time | Depending on existing tools this may vary. If you have tools like Fivetran or dbt, ELT is a breeze. | ✔️ | |
| Transformation capabilities | Programming languages/Frameworks like python, scala, and Spark enable complex transformations (enrich with data from external API, running an ML model, etc). SQL is not as powerful. | ✔️ | |
| Latency between data generation and availability of use by end-user | In general, the T of ELT is run as a batch job since SQL does not support streaming transformation. ETL can do batching, micro-batching, or streaming. | ✔️ | |
| SAAS tools | ELT allows for faster data feature delivery due to the availability of EL tools (Fivetran, Airbyte, etc). | ✔️ |
Note that the above comparison is for a simple data pipeline and can change depending on your specific data pipeline. Most companies use a mix of ETL & ELT approaches.
You may find data pipelines where the data is transformed using a framework like Apache Spark, loaded into a warehouse table, and transformed further using SQL in your data warehouse.
4. Conclusion
Hope this article clears up what people mean when they say ETL or ELT. The next time you are hit with this jargon, remember ELT is used to refer to a data pipeline where data is transformed using SQL in your data warehouse. ETL refers to any data pipeline that involves moving data from one system to another. When designing a data pipeline, use the criteria shown below to determine if you want to use an ELT approach.
- Development cost
- Running cost
- Engineering expertise
- Transformation requirements
- Latency requirements
If you have any questions or comments, please leave them in the comment section below.