1. Introduction
Congratulations! You are given a quick overview of the business and data architecture and are assigned your very first data engineering task. However, you have no idea what is going on. If you
Feel lost at your data engineering job
Feel overwhelmed by the code base and components that you don’t know
Deliver poorly on your tasks
Then this post is for you. In this post, we go over one process that can help you understand and deliver on your data engineering task.
Some jargon we use throughout this post are
Upstream processes: Any process that precedes the task you are working onDownstream processes: Any process that is executed after the task you are working onEnd-user: For simplicity, we will refer to any application, automated processes, and people using your data as end-user(s).
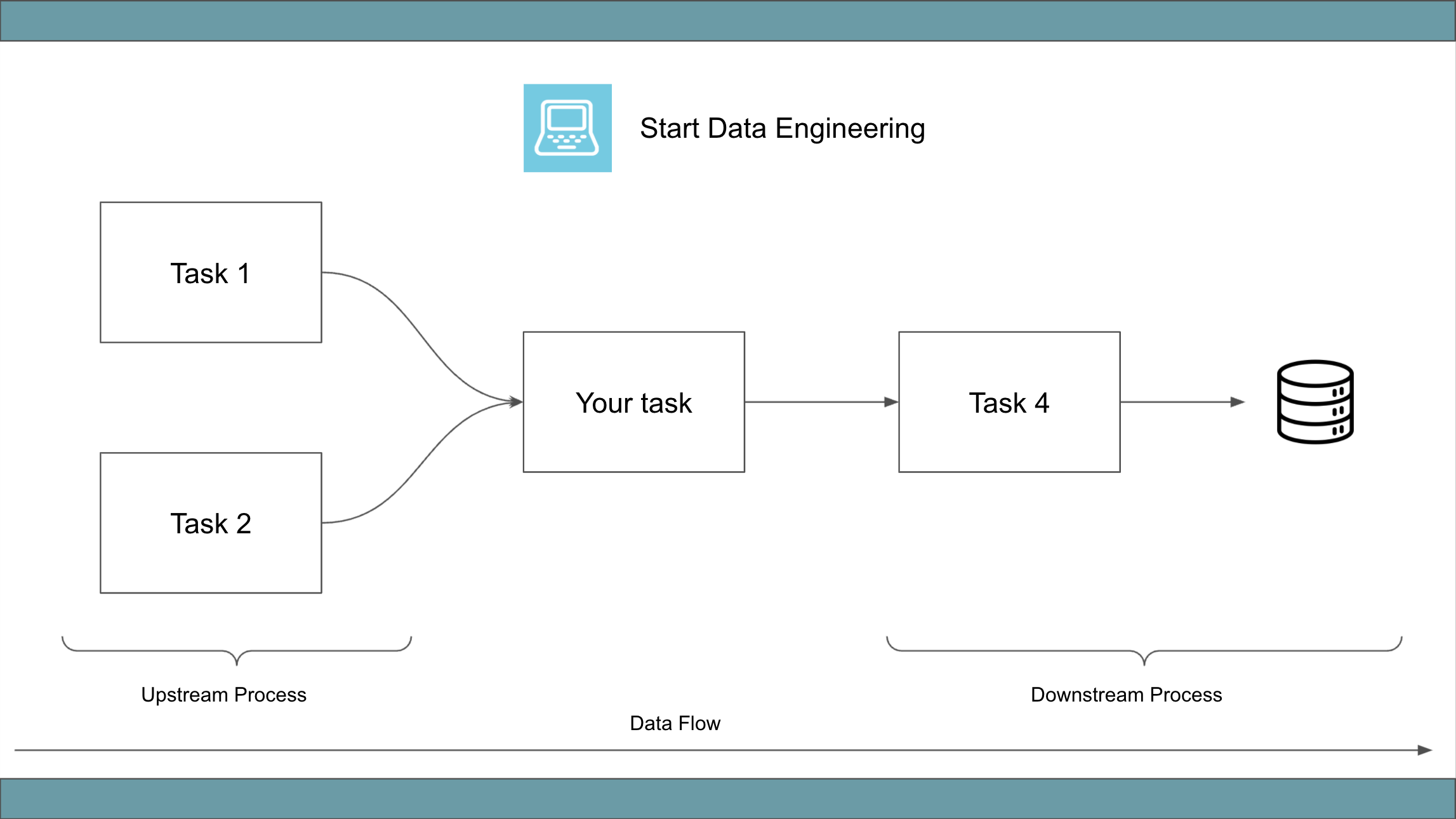
2. Understanding your data engineering task
A good understanding of your task is essential to delivering great work.
2.1. Data infrastructure overview
To get a quick grasp of your company’s data infrastructure, identify the components & interfaces present.
Typically, the components are:
- Application database (e.g. MySQL, Postgres)
- Data warehouse (e.g. Redshift, Snowflake, BigQuery)
- Data visualization tool (e.g. Apache Superset, Looker)
- Data pipeline orchestration engine (e.g. Apache Airflow, DBT, Prefect)
- Execution engine (e.g. Airflow workers, K8S tasks)
- Event streaming system (e.g. Apache Kafka, RabbitMQ)
- Cloud storage (AWS S3, GCP Cloud Storage)
- Distributed processing system (e.g. Apache Spark, Apache Flink, Apache Heron)
- 3rd party connectors (e.g. Fivetran, Airbyte, Singer)
Some of these components may be managed by a service, e.g. EMR for Spark and Flink, Stitch for Singer, Astronomer for Airflow, etc.
Interfaces may include:
Interfaces are how the components of your data infrastructure communicate. Components can also produce data (into a Kafka Topic or as data on S3) that are read by other components.
Track the data flow from the source to the destination of a data pipeline. Note down the components and interfaces. If time permits, do this for all your data pipelines. Otherwise, do this for the data pipeline that is most similar to the task that you are working on.
2.2. What exactly
When trying to understand what the task is, it helps to classify it into one of the following.
- Request to receive/create new data
- Adding new field/column(s) to output data
- Ingesting data from 3rd party sources into your data warehouse
- Request to ETL data between systems
- Building/Modifying data pipelines to send data to external clients
- Building/Modifying data pipelines to ETL data between application databases, search engines, data warehouse, data vendors, etc
- Changing a data pipeline schedule
- Increasing or decreasing the frequency of a data pipeline run
- Adding time-based code execution logic to a data pipeline
- Changing data types or formats
- Encoding, zipping, or partitioning data
- Changes in data format or schema
- Data observability
- Adding logs, monitoring, or alerting
- Creating alerts based on custom business criteria
- Data pipeline performance improvements
- Increasing the amount of data processed or speed of processing
- Reducing pipeline issues
- Planned architecture changes
- Moving to a new provider (eg. EMR to Databricks, etc)
- Adding metadata tables and their API endpoints
- Automating manually run processes, such as one-off scripts, data entry tasks, etc
Use this list as a starting point to figure out what exactly your task is.
2.3. Why exactly
Knowing exactly why you are working on a task can help you make good design decisions. In some cases, the solution may already exist but is unknown to the end-user.
When assigned a task, try to answer these questions yourself:
- Is this necessary?
- Why exactly is this necessary? What is the impact for the business, data team, data quality, data freshness, other developers, codebase, etc?
- Can this be achieved using data/code that currently exists?
Get to the bottom of your ask. E.g. If the task is to add a new column to a dataset make sure you understand why the column is needed and how it will be used? Is it possible to derive this column from existing data? If yes, should you, etc.
Validate any hypothesis that justifies the “why” of your tasks. For example, let’s say you are asked to zip a file(currently unzipped) before sending it to S3. This may sound like a good performance improvement. But, if the entire file is a few KBs in size it may be better to skip zipping and unzipping it downstream.
Understanding the why of your task provides you with the insights needed to come up with better alternatives. This is an area where your skills in data engineering and business can set you up as a crucial contributor to the company.
2.4. Current state
Understand in detail the current state of the data pipeline that you are going to be working on. If you are building a new data pipeline, compare it with a similar one. Read the code and keep track of the environment variables, class variables, synchronous/asynchronous tasks, data flow, permissions, components, interfaces, etc.
Revalidate the why, given your detailed understanding of the data pipeline. If you are stuck, reach out to your colleagues. Show them what you have tried, what you are stuck on, and ask for help.
2.5. Downstream impact
When modifying an existing data pipeline, ensure that it does not break any downstream tasks. It is also important to ensure that any proposed changes in the data type/schema are communicated to the end-user before the change is made. Failing to do so may cause irreversible data issues and/or monetary loss.
For example, changing a revenue column’s data type from USD to cents can cause the automated processes/analysts using that data to generate wildly incorrect expense reports.
3. Delivering your data engineering task
Now that you have a clear understanding of the task, it’s time (for you) to deliver.
3.1. How
If your task is very similar to something that already exists in your codebase, use that pattern. Unless your approach provides significant gains in complexity reduction, speed, cost savings, etc while being able to deliver on time, there is no need to re-invent the wheel.
If you are designing a new data pipeline, with no similar ones in your codebase, a good approach would be to
- Read up on how other people have solved similar problems. Usually from books or blog posts.
- Create a quick data pipeline design document. Notice the points of failures, possible data duplication issues, data processing efficiency, etc and modify your design as needed.
- Share the design document and get approval from your team before starting to code.
- If you are unable to come up with a design, meet with your technical manager/team lead/senior engineer. Show them what you have tried and the exact issue that you are stuck on. This will help them help you better.
Depending on the task at hand you may want to add tests, logs, and monitoring.
3.2. Breakdown into sub-tasks
Split up the design/implementation from the above section into a sequence of steps. Each step can be a sub-task. If your task is relatively independent there is no need to split them into sub-tasks.
As you work on a sub-task, you might need to make changes to other sub-tasks. With experience, the breaking down of a task into sub-tasks will get easier.
3.3. Delivering the finished task
Once you have completed the task, validate the output and only then, grant access to the end-user(s). Providing data access to end users without sufficiently testing the quality of your data can cause downstream data impacts that can be very difficult to reverse.
4. Conclusion
Hope this article gives you a good idea of how to understand and deliver any data engineering task. Starting as a data engineer can be overwhelming. A good overview of the data infrastructure and understanding the what and why of the task can guide you towards a great design.
The next time you are faced with a data engineering task that is overwhelming, follow the steps shown above. You will be able to deliver on your task, gain a better understanding of your data infrastructure, and become an invaluable member of your company.
If you have any additional steps that you follow/use or any questions or comments, please feel free to leave them in the comments section below.