Introduction
Change data capture is a pattern where every change to a row in a table is captured and sent to downstream systems. If you have wondered
How to ingest data from multiple databases into your data warehouse?
How to make data available for analytical querying as close to real-time as possible?
What is CDC, and when to use it?
How to implement change data capture with debezium and understand its caveats
Then this post is for you. This post will review what CDC is and why we need it. We will also go over a project that shows how every change to data in a transactional database can be captured and made available for analytics as an SCD2.
By the end of this post, you will clearly understand what CDC is and the different types of CDC, and you have built a CDC project with debezium.
What & Why CDC
CDC (Change Data Capture) refers to capturing all the changes to a dataset/table and making it available for downstream systems to do as required.
Example use cases:
- Capture every change that occurred to your data, either for auditing, SCD2, etc., where you need to see every historical change.
- Event-driven architecture, where a service operates in response to a change in data. E.g., a change in credit card number in a DB triggers an action in a separate microservice (say to check that the CC is valid, etc.).
- Syncing data across different databases in near real-time. E.g., Postgres -> Elasticsearch to enable text search, Postgres -> Warehouse to enable analytics based on the most recent data.
CDC, the EL of your data pipeline
When people talk about CDC in the context of data pipelines, they typically talk about two parts.
Capturing changes from the source system (E)
A CDC system must be able to access every change to the data. The changes include creates, updates, deletes, and schema changes. There are three main ways a CDC system can extract data from a database; they are below.
- Log: Our CDC system will read directly from a database’s transaction log in this method. A transaction log stores every change that happens in the database (e.g., every create, update, delete) and is used in case of a crash in the database to restore to a stable state. E.g., Postgres has WAL, MySQL has binlog, etc. The transaction logs have a sequence number that indicates the order in which the transactions occur (e.g., LSN in PostgreSQL); this is crucial since we need this to recreate the order in which transactions happened upstream (e.g., a row’s create must come, before its update).
- Incremental: In this method, our CDC system will use a column in the table to pull new rows. For this to work, the column must be ordered, e.g., incrementing key column or a updated_timestamp column. It’s not possible to detect a delete operation with this method.
- Snapshot: Our CDC system will pull the entire data in this method. Consider this as
select c1, c2, .. from tableas the query to pull all the data.
With both incremental and snapshot methods, you will lose updates to the data between pulls, but these are much easier to implement and maintain than the log method.
Making changes available to consumers (L)
Now that we have captured all the changes to the data, we will need to make it available to consumers. While we can use several frameworks, they usually fall into one of two patterns:
- Extracting the change data and making it available via a shared location (e.g., S3, Kafka, etc.) for multiple downstream consumers.
- Extracting and loading the change data directly into a destination system.
Typically the second option is much easier to implement and deploy, is used when the data throughput is smaller, and is generally a great starting point.
Project
Objective: Capture every change to the commerce.products and commerce.users table in a Postgres database and make it available for analytics.
The complete project is available here.
Run on codespaces
You can quickly run this project on GitHub codespaces, following the steps here
Prerequisites & Setup
To code along, you’ll need the following.
- git version >= 2.37.1
- Docker version >= 20.10.17 and Docker compose v2 version >= v2.10.2. Make sure that docker is running using
docker ps - pgcli
Windows users: please setup WSL and a local Ubuntu Virtual machine following the instructions here. Install the above prerequisites on your ubuntu terminal; if you have trouble installing docker, follow the steps here (only Step 1 is necessary). Please install the make command with `sudo apt install make -y’ (if it’s not already present).
All the commands below will be run via the terminal (use the Ubuntu terminal for WSL users). We will use docker to set up our containers. Clone and move into the lab repository, as shown below.
git clone https://github.com/josephmachado/change_data_capture.git
cd change_data_capture
# Make sure docker is running using docker ps
make up # starts the docker containers
sleep 60 # wait 1 minute for all the containers to set up
make connectors # Sets up the connectors
sleep 60 # wait 1 minute for some data to be pushed into minio
make minio-ui # opens localhost:9001In the minio UI, use minio and minio123 as username and password, respectively. In the minio UI, you can see the paths commerce/debezium.commerce.products and commerce/debezium.commerce.users paths, which have JSON files. The JSON files contain change data (create, update, and delete) for their respective tables.
Extract change data from Postgres and load it into S3
Our data pipeline does the following:
- Uses debezium to capture all the changes to the
commerce.productsandcommerce.userstable in a Postgres database. - Pushes the change data into a Kafka queue (one topic per table) for downstream consumers.
- An S3 sink (downstream consumer) pulls data from the corresponding Kafka topic and loads it into an S3 bucket (with table-specific paths).
We use duckDB to read the data in S3 and generate an SCD2 dataset.
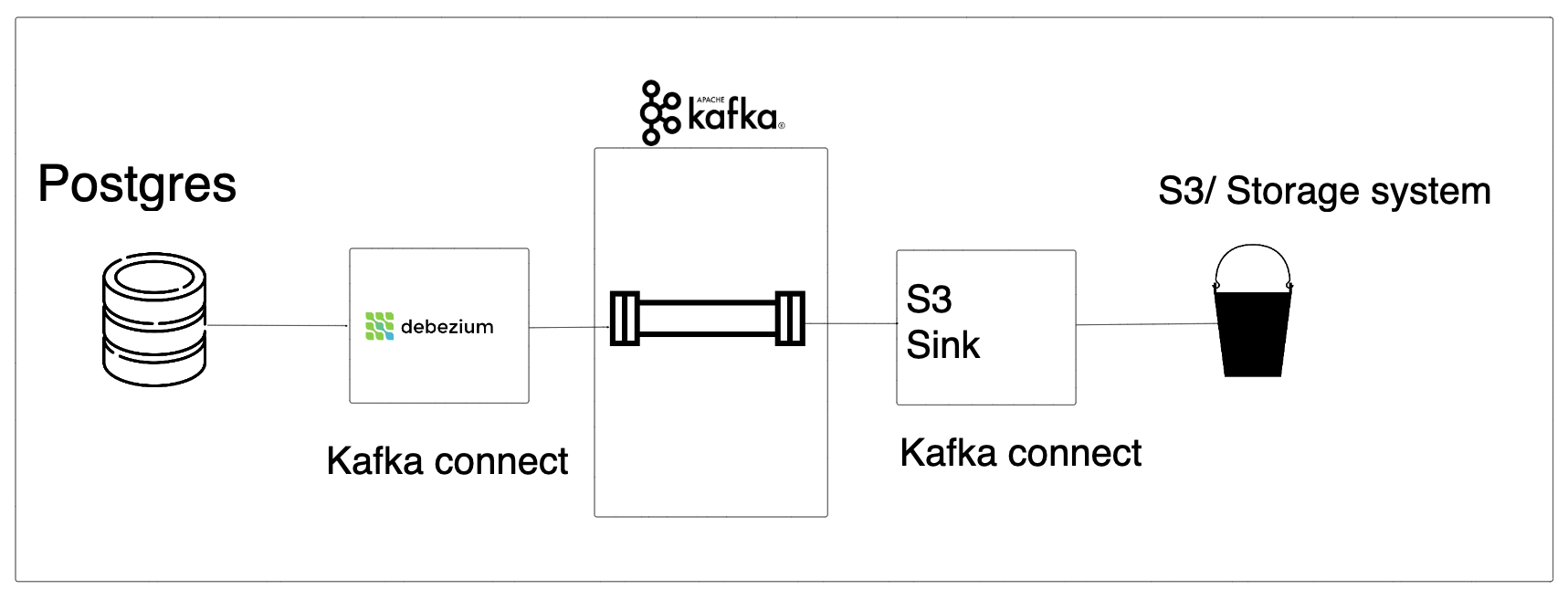
Let’s look at the main components of our data pipeline.
- Upstream System: Postgres database, with user and product tables. We also have a python script that creates fake create, updates and deletes.
- Kafka Connect Cluster: Kafka Connect enables data transfer between Kafka and various systems. Kafka Connect is a cluster separate from our Kafka cluster. We use two open-source connectors in our data pipeline
- Kafka Cluster: To make our change data available for downstream consumers.
- Data Storage: A cloud storage system to store the data generated by debezium. We use minio (S3 OS alternative).
- Data warehouse: A warehouse to ingest the data and make it available for querying. We use duckDB to ingest data from S3 and create an SCD2 table.
When we start our debezium connector, it will snapshot the entire table because the whole history will not be in the transaction log. Debezium will get a snapshot of the table first and then starts to stream from the transaction log.
Here’s an example of what a change capture data point created by debezium looks like:
{
"schema": {
// Describes the data types of all fields in the payload section
},
"payload": {
"before": null,
"after": {
"id": 0,
"name": "Destiny Davenport",
"description": "Investment size TV accept. Now rather visit behavior argue garden. Speech organization activity.\nHead step personal during among despite someone. Happy result blood.\nDeep time hour return her skill.",
"price": 79
},
"source": {
"version": "2.2.0.Alpha3",
"connector": "PostgreSQL",
"name": "debezium",
"ts_ms": 1678355887554,
"snapshot": "first",
"db": "postgres",
"sequence": "[null,\"23309544\"]",
"schema": "commerce",
"table": "products",
"txId": 785,
"lsn": 23309544,
"xmin": null
},
"op": "r",
"ts_ms": 1678355887892,
"transaction": null
}
}Let’s go over what they are
schema: Describes the data types of all the fields in the payload section.payload: Contains the change data and associated metadata.before: The data before the change. This section is null if it’s a create operation.after: The data after the change. This section is null if it’s a delete operation.source: Information about the source system (Postgres in our case)ts_ms: The Unix time when this transaction was committed to the DB.lsn: Log sequence number, used to keep track of the order of transactions; this is crucial to ensure correctness (e.g., no deletes on a row before creation)
op:: This represents if the transaction is a create (c), update (u), delete (d), or part of a snapshot pull (r).ts_ms: The Unix time when this transaction was read by debezium.
Analyze change data in S3 with duckDB
Now that we have the data available on S3 we can load it into our database.. Most DBs have Kafka connectors that let them ingest data directly from Kafka topics (e.g., snowflake Kafka connector).
Let’s see how we can use the debezium format and create an SCD2 type table. Install duckdb, open a Python REPL and run the following code to see the SCD2 table:
In the Python REPL:
import duckdb as d
d.sql("""
WITH products_create_update_delete AS (
SELECT
COALESCE(CAST(json->'value'->'after'->'id' AS INT), CAST(json->'value'->'before'->'id' AS INT)) AS id,
json->'value'->'before' AS before_row_value,
json->'value'->'after' AS after_row_value,
CASE
WHEN CAST(json->'value'->'$.op' AS CHAR(1)) = '"c"' THEN 'CREATE'
WHEN CAST(json->'value'->'$.op' AS CHAR(1)) = '"d"' THEN 'DELETE'
WHEN CAST(json->'value'->'$.op' AS CHAR(1)) = '"u"' THEN 'UPDATE'
WHEN CAST(json->'value'->'$.op' AS CHAR(1)) = '"r"' THEN 'SNAPSHOT'
ELSE 'INVALID'
END AS operation_type,
CAST(json->'value'->'source'->'lsn' AS BIGINT) AS log_seq_num,
epoch_ms(CAST(json->'value'->'source'->'ts_ms' AS BIGINT)) AS source_timestamp
FROM
read_ndjson_objects('minio/data/commerce/debezium.commerce.products/*/*/*.json')
WHERE
log_seq_num IS NOT NULL
)
SELECT
id,
CAST(after_row_value->'name' AS VARCHAR(255)) AS name,
CAST(after_row_value->'description' AS TEXT) AS description,
CAST(after_row_value->'price' AS NUMERIC(10, 2)) AS price,
source_timestamp AS row_valid_start_timestamp,
CASE
WHEN LEAD(source_timestamp, 1) OVER lead_txn_timestamp IS NULL THEN CAST('9999-01-01' AS TIMESTAMP)
ELSE LEAD(source_timestamp, 1) OVER lead_txn_timestamp
END AS row_valid_expiration_timestamp
FROM products_create_update_delete
WHERE id in (SELECT id FROM products_create_update_delete GROUP BY id HAVING COUNT(*) > 1)
WINDOW lead_txn_timestamp AS (PARTITION BY id ORDER BY log_seq_num )
ORDER BY id, row_valid_start_timestamp
LIMIT
200;
""").execute()Note: If you are unfamiliar with Windows, & CTE, check out these articles 1. Mastering window functions 2. What are CTEs and when to use them
SCD2 for the user table is an exercise for the reader; please put up a PR here.
Caveats
While we have a CDC pipeline working, there are a few caveats we need to be mindful of; they are:
- Handling backfills/bulk changes: If you are backfilling/changing multiple rows, the Kafka connect cluster and Kafka cluster will need to scale to handle these changes.
- Handle schema changes: If you are changing the schema, your consumer should handle this. If you use Kafka, a schema registry with a consumer system can help tremendously. The other option is to ensure the transformation operation can handle abrupt schema changes.
- Incremental key changes: An incremental key change (with the incremental CDC type) will require careful handling or a re-snapshot of the entire table.
- Update Postgres settings: When setting up the debezium connector with log-based CDC, we need to update Postgres configurations of the primary database. Updating Postgres settings may require restarting your Postgres database, possibly causing application downtime!
Other options
There are a lot of options when it comes to CDC systems; some of them are:
Each of these has its caveats; read their docs to understand what they are.
Conclusion
To recap, we saw
- What CDC is and its use cases
- The different types of CDC and their caveats
- A simple CDC Project with debezium
- Things to consider when implementing a CDC system
The next time you use a vendor CDC offering or build a custom CDC system, understand what CDC is, how it’s done, and its caveats. Knowing the core fundamentals of CDC will help you design your systems to be resilient and reliable.
If you have any questions or comments, please leave them in the comment section below.