1. Introduction
If you follow the data space, you would have noticed two camps: one using SQL and the other Python for data processing. It can be overwhelming and confusing when trying to make the right choice of tool vs something to get the job done quickly.
If you
Are struggling to understand when to use Python and when to use SQL for data transformations
Are not convinced by people saying, “Just use Python” or “Just use SQL.”
Want to understand the nuances and tradeoffs of using Python or SQL for data transformations
If so, this post is for you. Understanding how the underlying execution engine and code interact and the tradeoffs you can choose from will equip you with the mental model to make a calculated, objective decision about which tool to use for your individual use case.
By the end of this post, you will understand how the underlying execution engine impacts your pipeline performance. You will have a list of criteria to consider when using Python or SQL for a data processing task. With this checklist, you can use each tool to its benefit.
Note: Code available at Python Vs SQL for data transformations.
2. Code is an interface to the execution engine
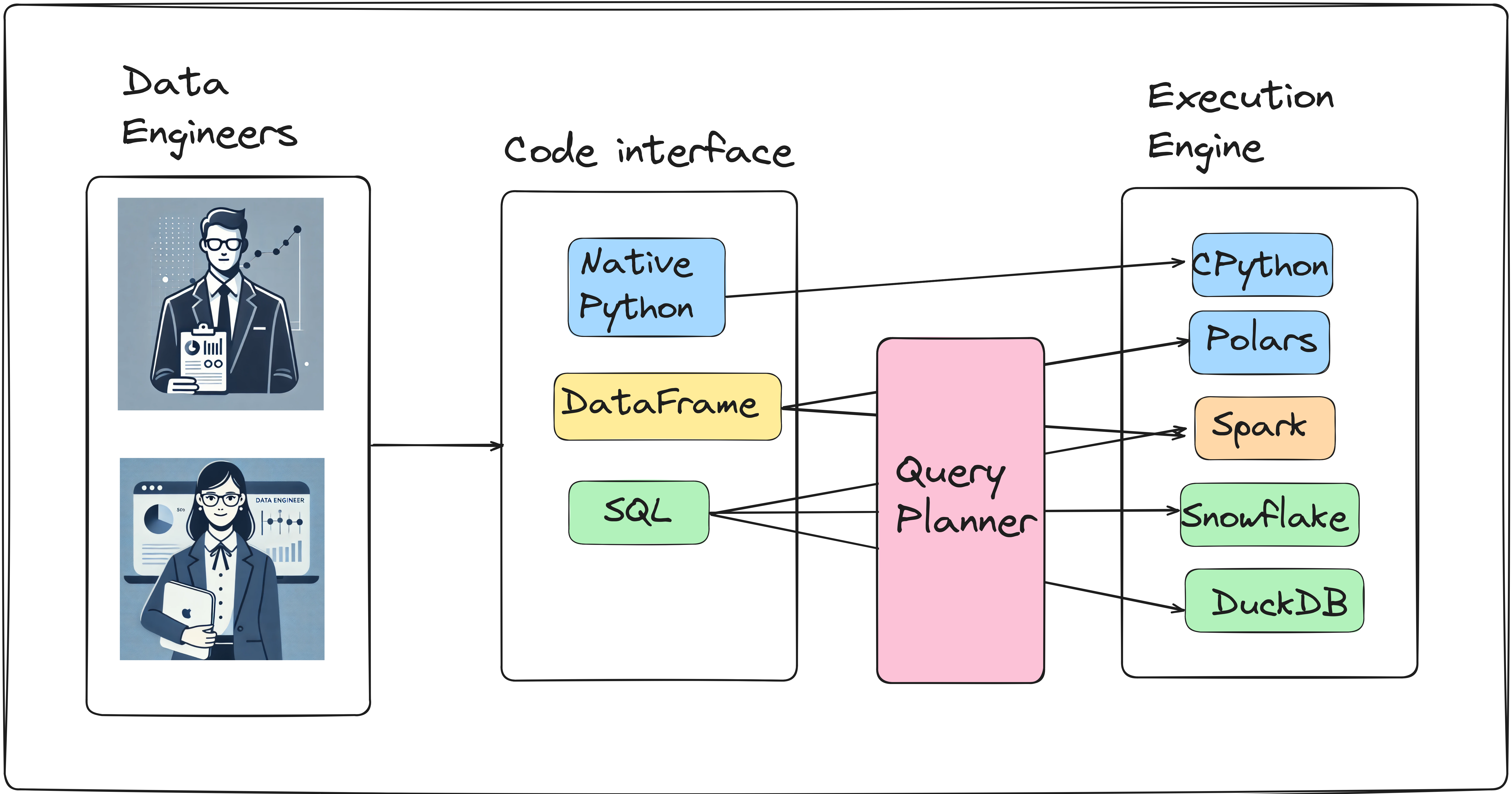
As you can see from the above image, your data transformation code will be executed in one of the execution engines.
Your code is an engineer-friendly interface to the execution engine. While you can write directly to the execution engine (in Rust, cpp, JVM), the dataframe/SQL/Python interface provides high-level abstractions that cover most data processing tasks (think JOIN in SQL).
Not all interfaces work with every execution engine (for example: Native Python will run in CPython, etc).
Note: ibis is a project that aims to act as an interface to multiple execution engines(they call it backends).
3. How to choose the execution engine and the coding interface
This section will see the criteria used to choose the execution engine and the coding interface.
While familiarity and existing infrastructure are crucial to consider, we assume a greenfield project that will enable us to go over the criteria objectively.
We will also assume the Python and SQL codes are of good quality since it’s possible to write bad code in both. Without this assumption, it would be impossible to compare code interfaces.
3.1. Chose execution engine based on your workload
Before you choose the interface, you have to choose the execution engine. The execution engine is the most critical piece of your data transformation since it is responsible for actually transforming the data.
3.1.1. Types of execution engine
There are three major types of execution engines:
Language server: a process that takes your code and runs the necessary logic. E.g., CPython, JVM, BEAM, etc.MPP (Massive Parallel Processing): are systems that use multiple nodes to run data processing. E.g., Spark, Clickhouse, Ray, Snowflake, BigQuery, etcSingle node data processing systems: While MPP can be run on a single node, the overhead involved in starting and stopping an MPP is unnecessarily high for smaller data loads. Single-node systems are designed to process data on a single machine, e.g., DuckDB, Polars, etc. (ref: Pipelines with DuckDB).
3.1.2. Criteria to chose your execution engine
Choosing an execution engine is critical since it will affect the kind of data processing you can do, the size of the data you can process, and the coding interface you can use.
Let’s look at the critical criteria to consider when choosing an execution engine:
Performance: MPPs and Single node processing systems will almost always perform better than your custom implementation in Python. This is typically due to the fact that those systems are built with multiple optimizations to make data processing efficient.Transformation type: MPPs are performant with SQL type transformation (single row operations, joins, aggregates, & Windows); however, they are terrible when you need complex looping, recursion, etc. ML algorithms involve looping & recursion dataframe/SQL-based systems have difficulty doing this efficiently. It is better to use an appropriate Python library for ML algorithms. MPPs offer functionalities to do ML, such as Spark MLLib, Snowflake UDF, etc.; however, ensure your algorithm is supported.Cost: MPPs are expensive to run, especially if you have a vendor managing them for you (e.g., Databricks, Snowflake, etc.) and they charge you based on the data processed, which can quickly add up. Single-node proc systems and native Python are available at no cost(except the price of the machine on which it will run).Data Size: MPPs are designed to process TB/PB of data. Single node proc systems do well up to about 100GB(roughly) of data. Native Python will have difficulty scaling to 100s of GBs of data unless you use independent serverless processing. Check out this article that shows how to scale data systems.Data location: If your data is located within an MPP (think table in Snowflake), it will be easier to process it in Snowflake rather than bringing it out to a different system.Execution engine location: If you have to process data on a single node in a fleet of IoT devices, you will want to use native Python or a single node proc system. MPPs require a lot of resources to run.Imperative or declarative code: In MPP and single-node data processing systems, you tell the execution engine what to do (SQL or dataframe), and it decides how to do it(declarative). In native Python, you tell the execution engine exactly how to perform a transformation(imperative). Spark offers RDDs, which give you imperative control.Intergration with other tools: Python is almost always better than MPP or single-node proc systems for moving data and spinning up infra. While MPP and single-node proc systems provide some capabilities for data extraction, they are not as versatile as Python (e.g., handling a bad API call, obscure XML file with a lousy format, etc.).
3.2. Chose coding interface for people who will maintain the pipeline
3.2.1. Types of coding interfaces
The usual interfaces in data engineering are Native Python (or another language like Go, Rust, etc.), Dataframe, and SQL.
While we use dataframe and SQL within Python, note that when we say Native Python, we refer to the implementation using Python data structures (list, dict, tuples, dataclasses, libraries, etc.).
Before going over the criteria, take a look at the code below (available here). The screenshot shows Native Python, Python with Dataframe, and SQL from left to right.
Think about code reusability and how easy/complex the code would be to test.
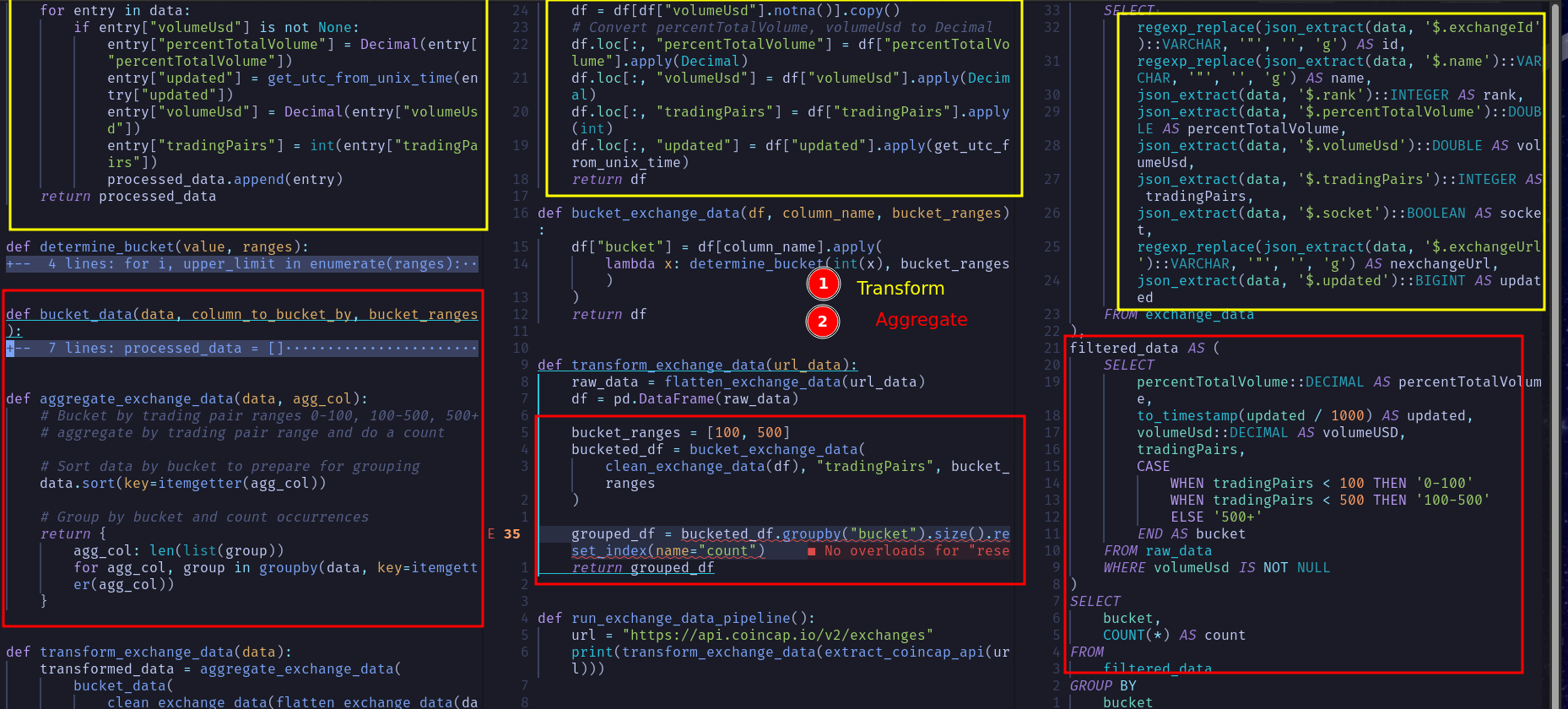
3.2.2. Criteria to chose your Coding Interface
Typically, data projects involve Python and SQL, Python for setting up data infrastructure and bringing data into the warehouse (or cloud storage), and SQL for transforming the data.
Let’s look at the critical criteria to consider when choosing a coding interface:
Code quality: Python is a general-purpose programming language and, as such, enables you to write well-designed software, and with its wide range of libraries, most problems are solvable. SQL is designed primarily for data access and manipulation and is not a general-purpose language.While SQL provides some reusability with temp tables/CTEs/Stored procedures, they are often hard to manage and monitor. You can use a tool like dbt to organize your sql code. Still, a templating library (dbt) will never be as powerful as a programming interface. For example, suppose you want to get the dataset schema to send this information to another system(think an external client). In that case, you will have to write some code in Python. ✅ Python
Testing: Here, we are talking specifically about code testing. Testing Python code is much easier than testing a sql transformation. e.g see our test cases for python transformation here. Checkout this article on how to use pytest. ✅ PythonWorking with nontabular data: While some SQL-based systems enable us to work with nontabular data(json, array, etc), the data must be formatted properly. With Python, one can work with an arbitrary set of data, e.g., web scraping, images, excel files with custom formats and formulas, API that do not follow standard RESTful principles, etc. Check out this article that goes over a few Python libraries to read data. ✅ PythonCreating visualization/reports: SQL systems integrate well with BI tools, and Dataframe systems integrate well with Python reporting (seaborn, plotly, dash, streamlit, etc). ✅ Python, SQLTyping & compile time checks: There are no compile-time checks for SQL; what this means is that if you have a SQL query that runs an addition operation on a string and int column, you will only catch this issue with tests or worse in production. While Python is not a static language, it has tools like mypy and typing to ensure that the inputs and outputs are of the expected format.See how we define input and output types in our native python code and how we validate them with mypy ✅ Python
Tools/libraries: Python has libraries for most problems you can run into: ML, reading data from PDF, pulling data from API, etc. Checkout this article that goes over some popular Python libraries. SQL systems are limited in their capabilities. ✅ PythonLearning curve & Staffing: SQL is easier to learn compared to python. More people know SQL than Python. Having code in SQL enables stakeholders to understand what is happening under the hood. While Python is more versatile, it is also harder to master and easier to mess up compared to SQL.Note that knowing SQL differs from using it correctly (understanding internals, optimizing queries, etc). Check out my efficient data processing in SQL e-book to quickly ramp up with fundamental concepts of distributed data processing in SQL. ✅ SQL
4. Conclusion
To recap, we saw
- How our code is an interface to the execution engine
- Criteria to choose the execution engine for your use case
- Criteria to choose the coding interface for your use case
When deciding what execution engine and coding interface to use, use the weighted average of the criteria shown above. Weigh the criteria from 1 to 5 for your needs, and you should be able to identify a clear winner for your use case.
If you have any questions or comments please let me know in the comment section below.