1. Introduction
If you are active in the data space, you have probably encountered systems like Snowflake, Databricks, Kafka, etc., which have been the subject of many articles about how they have revolutionized data.
However, underlying all the hype, many companies figured out that things quickly get expensive. Monitoring and failovers are costly, especially with systems like Kafka, Apache Spark, and Snowflake, which have lots of nodes.
If you are wondering
If the future is moving away from distributed computing
Why do companies waste mind-boggling amounts of money on these useless resources?
Why do small companies imitate what big companies are doing without being big companies?
Why do you have to watch data infra budget with a microscope, on top of paying a premium for all these popular tools?
How to avoid paying 1000s of dollars for accidental data scans.
How can we avoid data vendors who almost always put the onus on the user to use their tools “the right way”?
If so, this post is for you. Imagine if your data processing costs were so low that you wouldn’t even have to monitor them!
In this post, we will discuss an approach that uses the latest advancements in in-memory processing coupled with cheap, powerful hardware to significantly reduce data processing costs!
2. Project demo
Code & setup at cost_effective_data_pipelines repo.
2.1. Run on CodeSpaces
You can run the code in the repo with Codespaces.
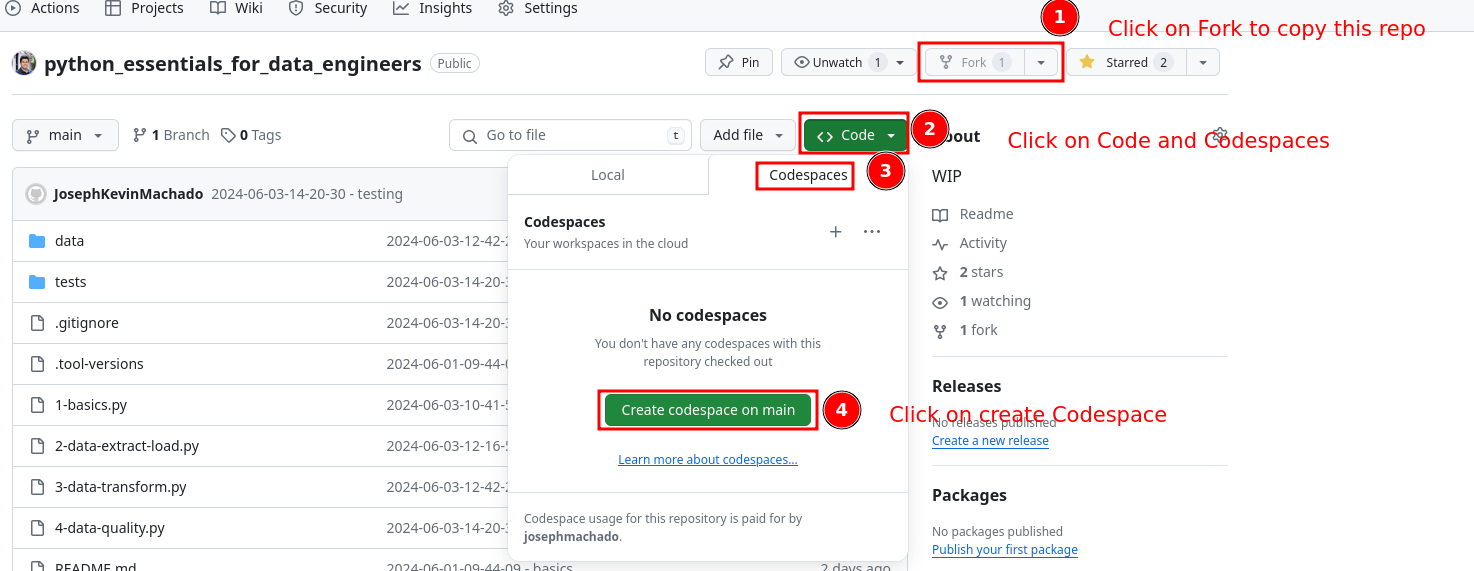
- Fork this repo.
- Click on code button and select the codespaces tab.
- Click on the
Create codespace on mainbutton.
When codespaces open, wait for it to complete installing the required libraries from ./requirements.txt.
You can open a Python REPL and run the scripts in the generate data section.
2.2. Run code on your machine
Alternatively you can run the code on your machine as well. You’ll need the following:
- Python 3.8 or above
- sqlite3
- Sufficient disk memory (depending on if you want to run with 1 or 10 or 100GB)
Clone the repo and create a virtual env and install the libraries needed:
2.3. Generate data
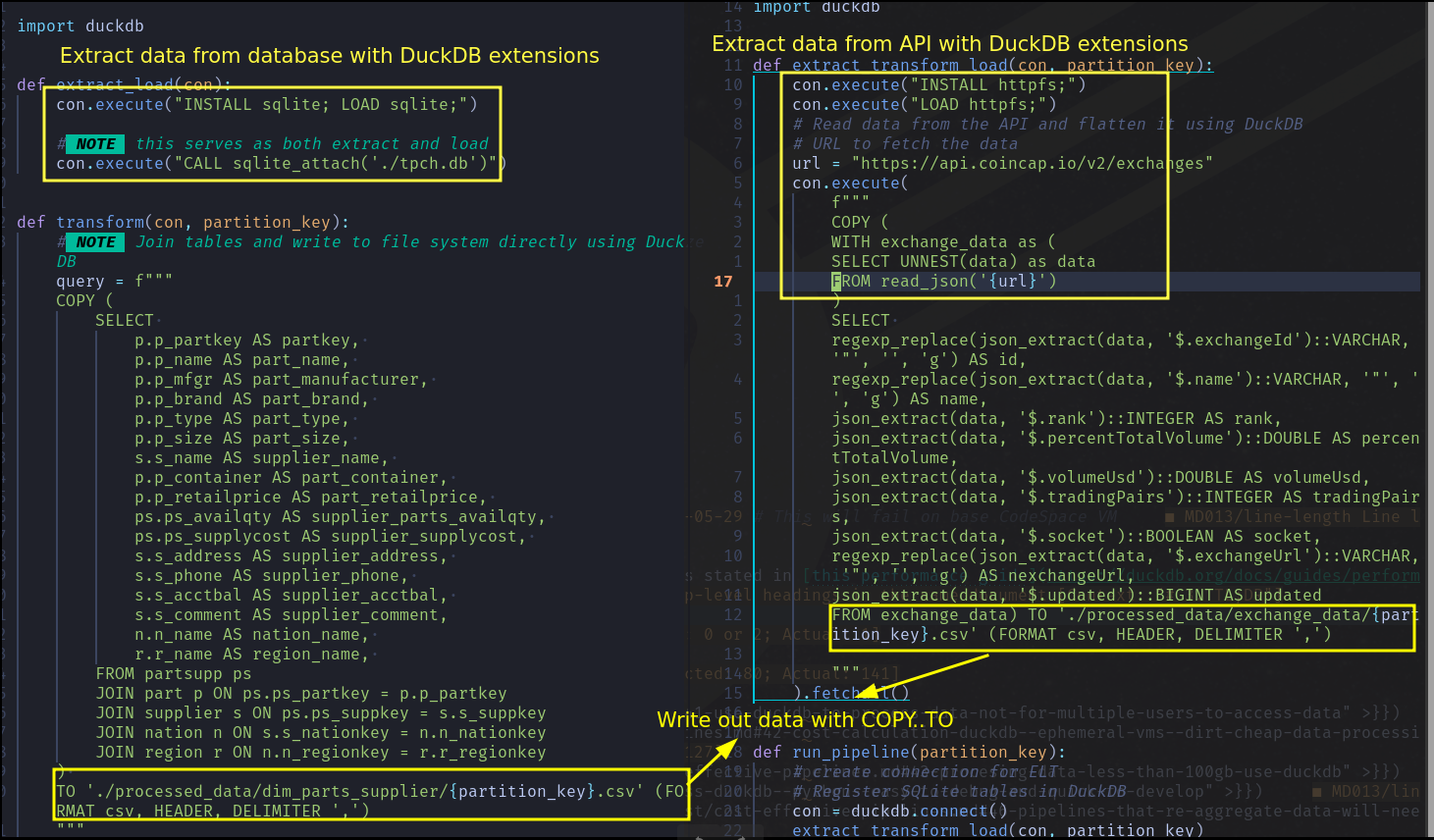
For the example in this repo we use the TPC-H data set and Coincap API. Let’s generate the TPCH data, by running the following commands in your terminal:
# NOTE: This is to clean up any data (if present)
rm tpch-dbgen/*.tbl
# Generate data set of 1 GB size
cd tpch-dbgen
make
./dbgen -s 1 # Change this number to generate a data of desired size
cd ..
# NOTE: Load the generated data into a tpch sqlite3 db
sqlite3 tpch.db < ./upstream_db/tpch_DDL_DML.sql > /dev/null 2>&12.4. Data processing
You can run the ETL scripts as shown below.
time python ./src/data_processor/exchange_data.py 2024-05-29
time python ./src/data_processor/dim_parts_supplier.py 2024-05-29
time python ./src/data_processor/one_big_table.py 2024-05-29
time python ./src/data_processor/wide_month_supplier_metrics.py 2024-05-29
# This last script will fail on base CodeSpace VM, see here for powerful Codespace VMS:`
# https://docs.github.com/en/codespaces/customizing-your-codespace/changing-the-machine-type-for-your-codespace?tool=webuiNOTE: The code in this repo can be optimized following principles stated in this performance guide.
3. TL;DR
Use DuckDB with ephemeral VMs to process data. While DuckDB + VMs are typically cheaper you will need to be mindful of how you use it. In this post, we will see
4. Considerations when building pipelines with DuckDB
In this section, we will examine the key concepts that one might need to consider when using tools that enable effective data processing in a single machine (e.g., DuckDB, Polars, etc.).
Terminology:
- VM (virtual machine): Refers to a machine typically rented from a cloud provider.
- Ephemeral: Only existing for the duration of a process.
- Node: A virtual machine usually part of a distributed data processing system.
4.1. ⭐ Use DuckDB to process data, not for multiple users to access data
The data access layer refers to the system that your stakeholders/downstream consumers use to access processed data. Typically, this would be a system that has data organized into schemas and tables, such as Snowflake, BigQuery, Spark, etc.
The data processing layer refers to the systems you would use to transform raw data into data usable by your stakeholders/downstream consumers. Typically, this involves systems that can process your raw data, such as Snowflake, BigQuery, Spark, Pandas, Native Python, etc.
While we can use DuckDB for the data access layer, it is typically not a good fit for this use case. Tools like DuckDB/Polars are great for the data processing layer, since these tools are not designed for when multiple stakeholders want to query the processed data.
While DuckDB can be tuned to allow multiple readers, it is not designed for this use case (ref). Using a database designed for multi-user access for the data access layer would be better.
4.2. ✅ Cost calculation: DuckDB + Ephemeral VMs = dirt cheap data processing
Most cloud providers have the option for you to rent a VM for the duration of your data processing. (e.g., AWS Lambda, AWS ECS tasks, GCP Cloud Functions, etc). These ephemeral VMs can be rented out for really low prices (hint: look for spot instances for more savings!). Couple cheap ephemeral VMs + DuckDB, and you have a snappy, affordable, powerful data processing system!
To demonstrate let’s consider this problem statement (from a Reddit post):
- Number of jobs: 800 jobs reading data from 80 source systems
- Number of files: 300+, lets round it to 400
- Average size per file: 1GB (post says not exceeding 1GB)
Objective: Reducing our overall costs to between $3,000 and $5,000 per month.
We can easily fit the files in memory if we assign a VM with 2GB memory and 4GB disk space. Thus, our lambda costs will be only 500 USD per month!
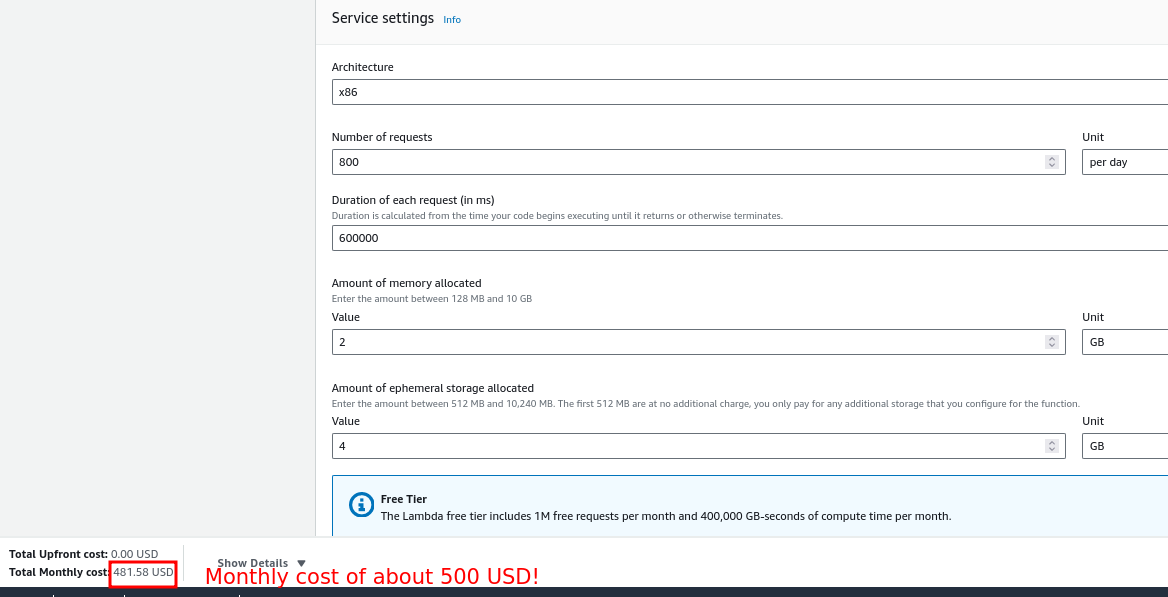
We assume that the data transfer and IPV4 costs are negligible and that the data can be processed in under 10 minutes, both of which are reasonable assumptions.
You can get similar pricing with the aws step function, ECS, and AWS Fargate. Basically, most ephemeral VM systems are inexpensive if the lambda max run time of 15 minutes is a deal breaker. By default, lambda allows for 1000 concurrent requests.
4.3. ✅ Processing data less than 100GB? Use DuckDB
Most companies do not process large amounts of data in a single pipeline run (ref). If the size of the data you are processing is less than 100GB, try using an appropriate VM, and you will be able to process it in DuckDB (ref).
Look at this performance chart from Coiled, which shows DuckDB’s performance on TPCH queries.
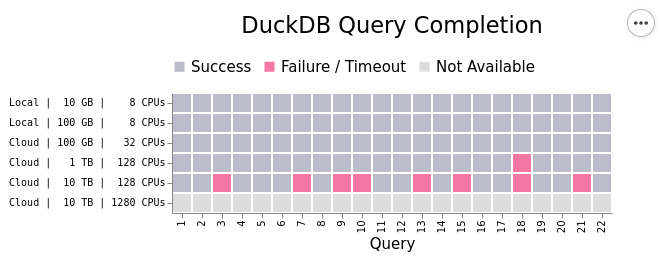
If data to be processed in one ETL run is > 100GB, and you are not able to tune your job or get access to a sufficiently large VM, you may want to
- Split the 100GB data into individual files (if they are not already) and process them individually & independently with individual VMs.
- If your data pipeline processes the entire data each run, consider moving to an incremental data processing style (Incremental data processing).
- Use a distributed data processing system like Apache Spark, Trino, Snowflake, etc.
4.4. ⚠️ Distributed systems are scalable, resilient to failures, & designed for high availability; DuckDB is not
Large-scale distributed systems, such as Apache Spark, Trino, and Snowflake, are designed to handle any amount of data thrown at them and are always available to run jobs. While some of them require teams to manage clusters, others require you to pay a lot of money for the data vendor to manage them for you.
Let’s look at the three key characteristics that make distributed data processing systems powerful:
Scalability, refers to the ability to scale the number of nodes up or down depending on the need. In Snowflake, you can spin up extra clusters, Spark allows dynamic scaling, etc. Single-node processing systems like DuckDB/Polars are not meant for wildly varying large data.Resilience & Availability: Distributed systems operate on hundreds or thousands of nodes. Due to the scale of the number of nodes used, some nodes inevitably fail, and distributed systems are designed to be resilient against such failures. Distributed systems are also designed to be available 24x7, meaning they will respond appropriately to the person/system that submits a data processing job.
In distributed systems, if a node fails, there is a fallback mechanism to ensure that other nodes take its place. However, if you are using DuckDB + ephemeral VMs, then failures will require a full re-run.
While you can alleviate re-running transformations by setting checkpoints in your code(e.g., steps to write data to an external store upon completion of a specific task and reusing them in case of failures), this will increase data processing time and, subsequently, costs.
A better approach would be to ensure that the data processing step is sufficiently optimized & build idempotent pipelines that re-running the entire pipeline will not take more than a few minutes.
4.5. ✅ KISS: DuckDB + Python = easy to debug and quick to develop
A huge issue with most companies building data pipelines is the inability to run and test their code locally. Companies waste thousands of hours when they require developers to start a cluster, run the job, check the output, and stop the cluster for a simple column type change.
When debugging an error with DuckDB, you will be able to recreate the exact failure on your laptop. A simpler program (such as an in-memory etl process) is much easier to debug than a pipeline that uses complex distributed systems.
An added benefit is that the CI/CD pipeline will be more straightforward.
4.6. ⚠️ Pipelines that re-aggregate data will need to be optimized
If you are building incremental pipelines and have to aggregate data over the past n days/years/months or the entire dataset, you may want to try one of the following options:
- Aggregate past n periods of data instead of reaggregating the entire data set. For example, if your pipeline processes sales data that comes in every day, instead of reprocessing the past n years’ worth of data, consider reprocessing the past 3/6 months of data (depending on later arriving data for your business use case).
- Use specialized data structures such as datelists to optimize large aggregation operations.
Another coding pattern to look out for is looping, which is generally not a great fit for SQL.
4.7. ⚠️ Moving data in and out of VMs costs some money
Data needs to be present in the VM disk to be processed. Data transfer costs (both in and out of the VM) are usually negligible. However, if you are not careful, they can significantly increase the pipeline time.
While there are many tools to move data, note that Python systems are typically single-threaded and, as such, can take up the bulk of your processing time. In our code, we use DuckDB’s extensions, which are written in C++, making it extremely fast and effective to use all the cores of the VM.
Also, ensure that the files that you write out are of sane sizes. For example, most distributed warehouses work well with files of size 240MB. Note that just like reads, data will need to be written out to your destination. In most cases, this is a cloud storage system, and cloud providers have effective algorithms for moving data in parallel.
Most cloud providers have bandwidths specified for transfer rates and are usually very fast within the same user regions.
4.8. ⚠️ Data permissions are set at the service level
Most data processing systems have comprehensive data access controls, which are crucial for data governance. Since DuckDB is run as a single-node data processor, we will need to handle data access at a service (E.g., AWS Lambda can access a specific S3 bucket, etc.) level.
The inability to handle data permissions at a row level (like what Snowflake can offer) can be a deal breaker in some cases.
4.9. ✅ Logging and observability
While most distributed systems provide a straightforward UI for monitoring resource usage and status, DuckDB does not. In such cases, you can use your company’s choice of logging and monitoring systems.
For example, If you are using AWS ECS to run your temporary tasks, you can send the logs to the log service of your choice (Datadog, Papertrail, Cloudwatch) and check VM metrics at AWS management console.
5. Conclusion
To recap, we saw:
- Where to use DuckDB
- How to process data cheaply
- Data size considerations when using DuckDB
- KISS pipelines
- Data aggregation patterns for single VM processing
- Data transfer costs
By following data pipeline best practices and understanding the data size and transformation types, you can build data pipelines that make data processing super cheap!
The next time you build a data pipeline, consider the cost of complexity and data infra! If you’d like to learn more or would like some help setting up your pipelines, please feel free to contact me at joseph.machado@startdataengineering.com or leave a comment below.