1. Introduction
Whether you are new to data engineering or have been in the data field for a few years, one of the most challenging parts of learning new frameworks is setting them up! Data infra is notoriously hard to set up. You want to improve your skills on a specific tool or framework, but the biggest issue is usually setting them up. If you feel
Feel that data infrastructure is tough to set up locally
Feel that it is not easy to see how your code changes impact the pipeline quickly
That you are having a hard time installing the data tool/framework that you want to practice
If so, this post is for you. Imagine being able to inspect a tool/framework easily. You will gain invaluable expertise by quickly trying new things and seeing results.
In this post, we will discuss data pipelines that follow batch, streaming, and event-driven paradigms. By reading through this post, you can quickly spin up the data tool/framework you need.
2. Run Data Pipelines
All the pipelines below are runnable on GitHub codespaces and locally with Docker.
2.1. Run on codespaces
You can run the data pipelines linked below using GitHub codespaces. Follow the instructions below.
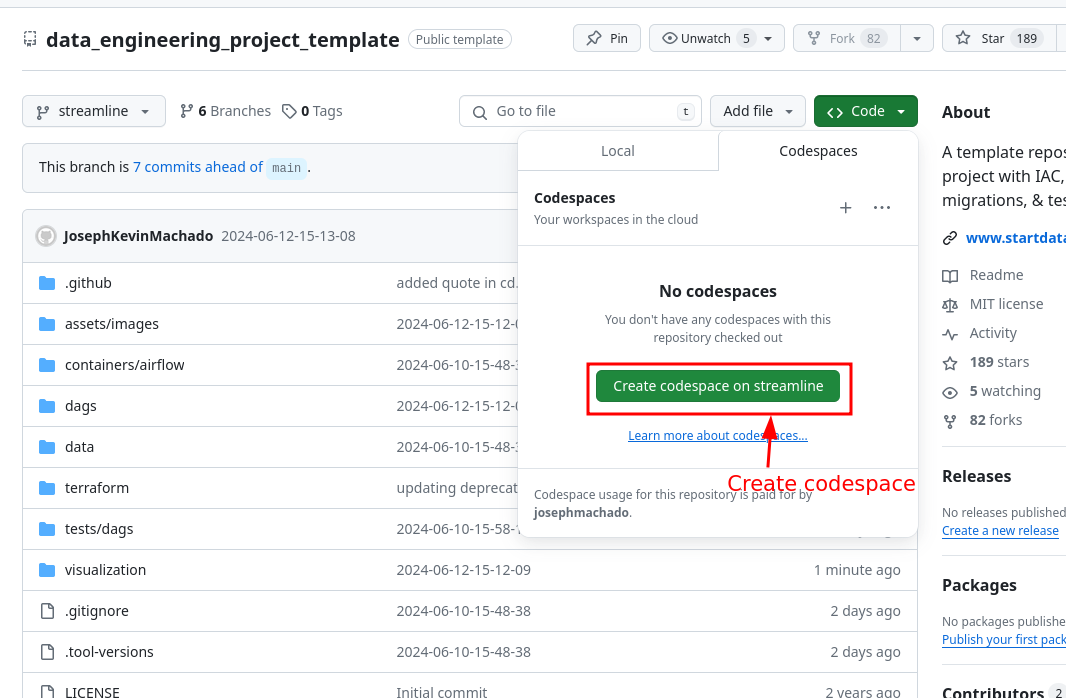
- Fork or clone the linked repo. Create codespaces by going to the repo and then clicking the
Create codespaces on mainbutton. - Wait for codespaces to start, and if the project has a
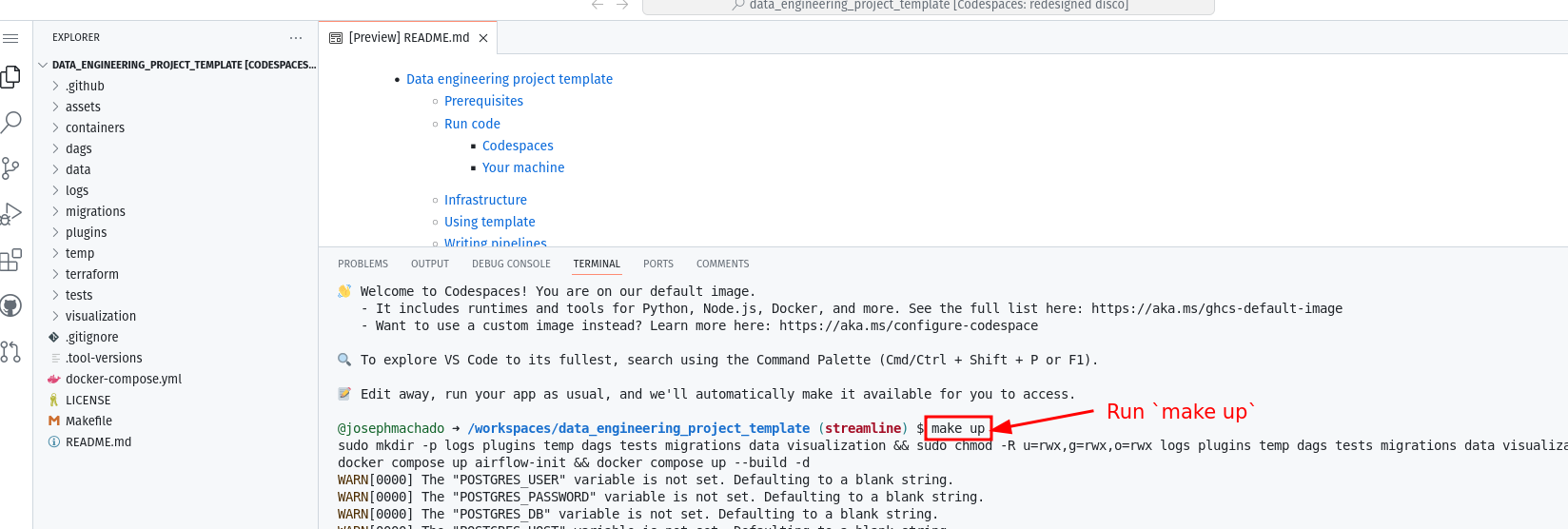
requirements.txt,wait for codespaces to finish installing the libraries. - In the codespace terminal, type
make up(some projects have specific commands). - Wait for
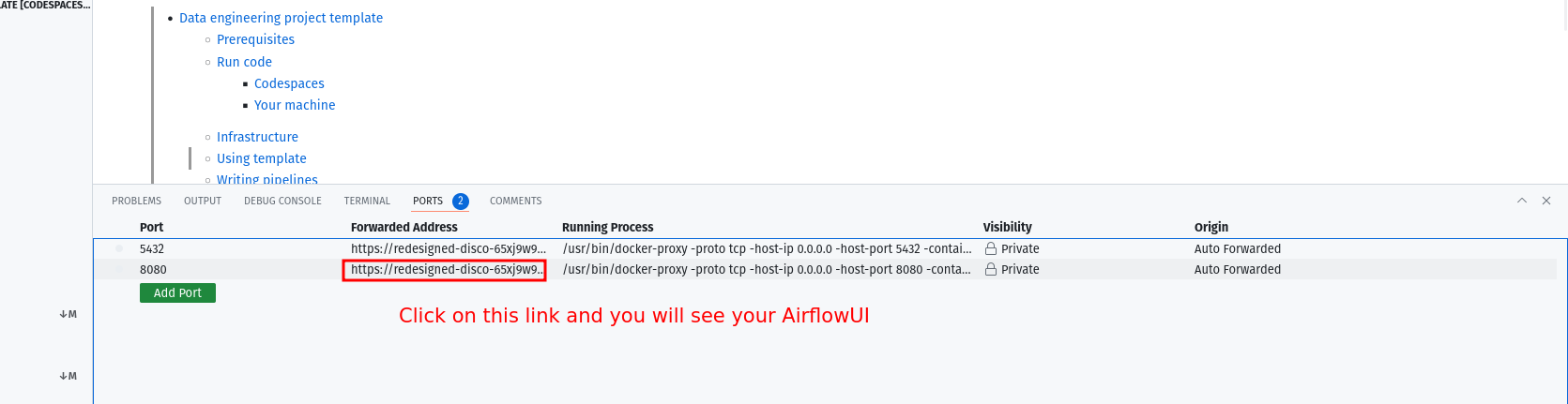
make upto complete. - After 30 seconds, go to the
portstab and click on the link exposing port8080to access Airflow UI (username and password isairflow). (Each project can have its UI ports)
Note Make sure to switch off the codespaces instance; you only have limited free usage; see the docs here.
2.2. Run locally
To run locally, you need:
- git
- Github account
- Docker with at least 4GB of RAM and Docker Compose v1.27.0 or later
Clone the repo and run the following commands specified in their GitHub repo.
Note: Do not use the Docker images in the projects below for production, as they are not optimized.
3. Projects
3.1. Projects from least to most complex
While you can pick and choose the projects you like, here is a recommended order for people new to DE:
3.2. Batch pipelines
| Attribute | bitcoin_monitor | simple_dbt_project | cost_effective_data_pipelines | data_engineering_project_template | beginner_de_project | rainforest |
|---|---|---|---|---|---|---|
| Blog and code links | Blog: Project to impress Hiring Manager and Code: bitcoin_monitor | Blog: dbt tutorial and Code: simple_dbt_project | Blog: Pipelines with DuckDB and Code: cost_effective_data_pipelines | Blog: Data Engineering Project Template and Code: data_engineering_project_template | Blog: Beginner Data Engineering Project-Batch and Code: beginner_de_project | Blog: - and Code: Rainforest |
| Source | CoinCap API | csv | sqlite3 (OLTP db with TPC-H data) | CoinCap API | csv and Postgres | Postgres |
| Destination | Postgres warehouse | DuckDB warehouse | DuckDB | DuckDB warehouse | DuckDB warehouse | Cloud storage |
| Scheduler | cron | - | - | Airflow | Airflow | - |
| Orchestrator | Python native | dbt | Python native | Airflow | Airflow | Spark DAG |
| Data processor | Python standard library | DuckDB | DuckDB in Python | Python native and DuckDB | Apache Spark and DuckDB | Apache Spark |
| Data quality | - | dbt tests | - | Cuallee | Cuallee | Great Expectations |
| Storage | file system | file system | file system | Minio (open source S3) | Minio (open source S3) | Minio (open source S3) |
| Visualization | Metabase | - | - | Quarto | Quarto | - |
| Monitoring and alerting | - | dbt UI for monitoring | - | Airflow UI | Airflow UI | Prometheus and Grafana |
| CI/CD | GitHub Actions | - | - | GitHub Actions | GitHub Actions | - |
| IAC | Terraform | - | - | Terraform | Terraform | - |
| Code testing | Pytest | - | - | Pytest | Pytest | Pytest |
| Linting and formatting | black, isort, mypy, and flake8 | - | - | black, isort, mypy, and flake8 | black, isort, mypy, and flake8 | black, isort, mypy, and flake8 |
3.3. Stream pipelines
| Attribute | Data Engineering Project - Stream Edition |
|---|---|
| Blog and code links | Blog: Data Engineering project Stream and Code: beginner_de_project_stream |
| Source | Postgres tables |
| Destination | Postgres warehouse and Kafka |
| Scheduler | Continuously running stream |
| Orchestrator | Apache Flink DAG |
| Data processor | Apache Flink |
| Data quality | - |
| Storage | Apache Flink metastore and OLTP table for enrichment |
| Visualization | Apache Flink UI and Grafana |
| Monitoring and alerting | Prometheus and Grafana |
| CI/CD | - |
| IAC | - |
| Code testing | - |
| Linting and formatting | black, isort, mypy, and flake8 |
3.4. Event-driven pipelines
| Attribute | CDC with Kafka and Debezium | End to end pipeline test, simulating AWS Lambda |
|---|---|---|
| Blog and code links | Blog: Change data capture with Debezium and Kafka and Code: change_data_capture | Blog: End to end tests for AWS Lambda pipelines and Code: e2e_datapipeline_test |
| Source | csv, kafka | csv on SFTP |
| Destination | DuckDB warehouse | Postgres warehouse |
| Triggering event | Event-driven, by insert/delete/update on Postgres table | AWS Lambda triggers event on S3 inserts |
| Orchestrator | Debezium and Kafka connect | Python native |
| Data processor | Debezium to read WAL and S3 sink to push data to S3 | Python |
| Data quality | - | - |
| Storage | S3 (we use Minio to simulate S3) | S3 (we use Minio to simulate S3) |
| Visualization | - | - |
| Code testing | - | moto, Pytest |
| Linting and formatting | black, isort, mypy, and flake8 | black, isort, mypy, and flake8 |
3.5. LLM RAG pipelines
Blog at Building Retrieval Augmented Generation with LLM pipeline and Code at data_helper.
4. Conclusion
To recap, we saw
- How to quickly run data pipelines with GitHub codespaces
- Batch, Stream and Event-driven pipeline examples
Please bookmark this page and use it to build your own data pipelines! Try out new tools/frameworks and showcase your expertise to potential employers.
Send me your pipeline repo, and I will provide you with feedback!
Please let me know in the comment section below if you have any questions or comments.