1. Introduction
Have you worked, or are you working with a code base that “moved fast” but had zero to no tests? Every minor feature request makes you start sweating because looking at your codebase the wrong way makes things explode unpredictably. If you are
Wondering how to move fast without breaking existing pipeline logic
Wondering if you bump your Spark version (or package versions, or make any other environmental change), how do you know everything still works as expected?
Working with a massive write-only SQL code base with almost no tests in sight. That will eventually collapse like a gasoline-soaked house of cards.
Not even sure how or what exactly to test.
Then this post is for you. In this post, we will go over why tests are necessary, the main types of tests for data pipelines, and how to effectively use pytest to test your PySpark application.
Note: This post is about testing for code logic, not for data quality. See this post on data quality for defining and checking data quality as part of a pipeline.
2. Ensure the code’s logic is working as expected with tests
Testing data pipelines is critical for ensuring the reliability and accuracy of our data pipelines. Like any software application, data pipelines can contain bugs or logical errors that could lead to incorrect data or pipeline hanging/failing.
Tests help catch errors early in the development cycle, reducing the cost and complexity of fixing issues later.
Moreover, as data pipelines evolve with new features or modifications to existing processes, tests serve as a safety net that ensures new changes do not break the pipeline’s existing functionality. Integration testing is critical in complex data ecosystems where changes in one part of the system could have unforeseen impacts on downstream processes. For example, a change in the data format of an upstream source could affect downstream systems.
2.1. Test types for data pipelines
While there are multiple types of code testing, here are the critical ones for a data pipeline:
Unit testingrefers to testing individual units of code in isolation. Unit testing aims to ensure that a unit of code is working as expected. In our project, the tests under etl/test/unit are unit tests, which test the functionality of the transform function.Integration testingrefers to testing the interaction between components of our data pipeline. Our code tests that the data written into and read from the data store is as expected. In our project, the integration tests are under etl/test/integration.End-to-end testingrefers to testing where we test the entire pipeline from start to finish. End-to-end testing has a low ROI as the system grows in complexity. It may take a long time to run an e2e test, and setting up the infrastructure required to run them locally takes time and effort. In our project, the end-to-end tests are under etl/tests/end_to_end
2.2. pytest: A powerful Python library for testing
pytest is a robust testing framework for Python that makes it easy to write simple and scalable test cases for your code. We can use the pytest cli to run tests (individually or multiple) and it also has multiple flags that you can change as per your needs (docs for cli flags).
Prerequisite: Docker fundamentals for data engineers
The code for this post is available in the docker_for_de repo. We can run pytest as shown below:
You can run tests in one of two ways
- Bash into the docker container and then run pytest:
- Run pytest inside the docker container by submitting pytest to the spark-master container:
You can stop the containers using docker compose down.
2.2.1. Set context, run code, check results & clean up
When we test our code, we are testing the outputs of our code. You can think of a test as being broken down into four steps:
- The arranging step involves getting all the necessary fake data, functions, database tables, and so on (aka context) ready before we can test our code. We set the scene on which our code will run.
- The act step involves invoking the code we want to test.
- The assert step involves checking that the output of our code (from the act step) is what we expect it to be.
- The cleanup step involves removing any data/db tables, etc, that remain from the arranging step.
2.2.2. Tests are identified by their name
Pytest uses file and function names (prefaced with test_) to identify test functions (see this link for more details). In our example, our test scripts are named test_*.py, and the class names start with Test, and test function names begin with test_*.
2.2.3. Use fixture to create fake data for testing
Fixtures in pytest are reusable components you define to set up a specific environment before a test runs and tear it down after it completes. They provide a fixed baseline upon which tests can reliably and repeatedly execute. Fixtures are incredibly flexible and can be used for a variety of purposes, such as:
- Creating a SparkSession (with test-specific configs) to be shared across tests.
- Setting up database tables that are to be used for testing.
- Downloading jars necessary for our Spark application.
- Providing system configurations or test data.
- Cleaning up after tests are run.
Fixtures can be scoped at different levels (function, class, module, session), meaning you can set a fixture to be invoked once per test function, once per test class, once per module, or once per session, respectively.
In our example, we create fake data as a fixture and inject it into the function that requires it for testing:
# Create a DataFrame to be returned by the mock
@pytest.fixture
def fake_data(spark):
data = [
Row(user_id="1", first_time_sold_timestamp="2021-01-01 00:00:00"),
Row(user_id="2", first_time_sold_timestamp="2021-02-01 00:00:00"),
Row(user_id="1", first_time_sold_timestamp="2021-01-02 00:00:00"),
Row(user_id="2", first_time_sold_timestamp="2021-02-02 00:00:00"),
Row(user_id="3", first_time_sold_timestamp="2021-03-01 00:00:00"),
]
return spark.createDataFrame(data)
# Test function to check if run_code works as expected
def test_run_code(spark, fake_data):
# Mock the get_upstream_table function to return the fake_data
with patch('etl.simple_etl.get_upstream_table', return_value=fake_data):We define a fake_data function fixture with the @pytest.fixture decorator. By default, the fixture will be scoped to the function that uses the name of that fixture as an input.
The injected fixture fake_data is used as input for the test.
2.2.4. Define items to be shared among tests with conftest.py
In pytest, conftest.py is a configuration file used to define fixtures, hooks, and plugins that can be shared across multiple test files.
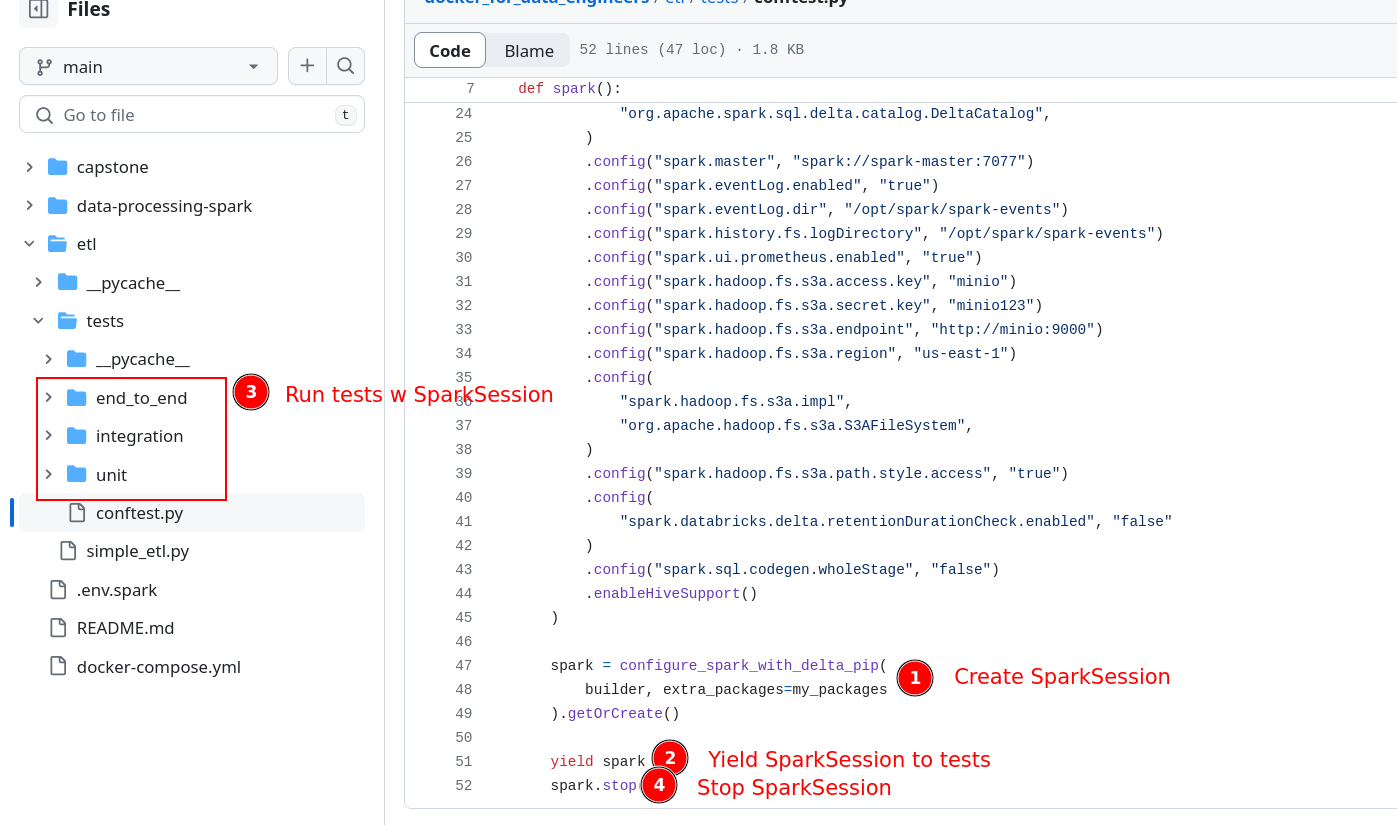
In our example conftest.py we create a SparkSession variable (called spark) as a fixture and this SparkSession will be injected into the functions that it is required.
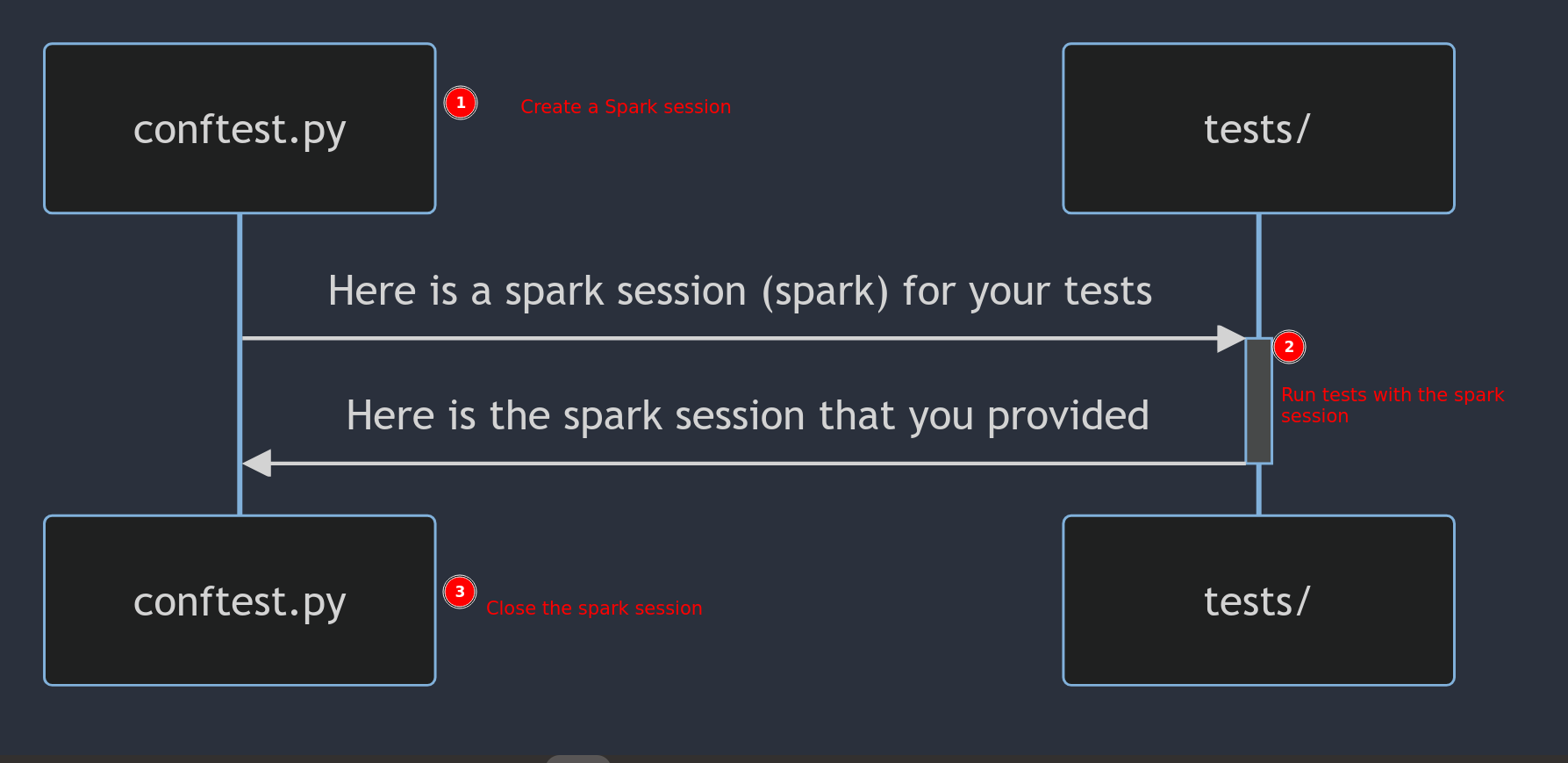
Our conftest fixture is at a session level, meaning that when a test session (invoked by pytest) starts, this function will be run, and the SparkSession created here will be shared among all the tests run in that session.
2.2.5. Modify code behavior during testing with mocking
When we run tests, we might want to override a function’s behavior. In such cases, we can use a mocker to do this.
In our example, to run our end-to-end test, we must ensure that our code pulls fake data from our Postgres db. We can do this using a mock of the get_upstream_table function as shown below:
Note that the keyword patch is used to replace part of code (code under the with block) with the mock function, i.e., patch is used to define what to mock.
3. Conclusion
This article gave you a good idea of how and what to test in your pyspark data pipelines. The next time you build a data pipeline, add a new feature, or test, your colleagues and future self will be grateful. You will ensure that your code behaves as expected and future-proof your code from being inadvertently affected by a change.
To recap, we saw