flowchart TD
A[Genrate data] -->B[Check if the data is good]
B --> C[Log the results of the check]
C --> D{Did the data pass the check}
D -->|Yes| E[Write the data to its storage location]
D -->|No| F[Raise an alert and warn DEs]
E --> G[Ready for downstream consumers]
F --> H[Fix the issue]
H --> A
1. Introduction
There are a lot of data projects available on the web (e.g., my list of data eng projects). While these projects are great, starting from scratch to build your data project can be challenging. If you are
Wondering how to go from an idea to a production-ready data pipeline
Feeling overwhelmed by how all the parts of a data system fit together
Unsure that the pipelines you build are up to industry-standard
If so, this post is for you! In it, we will go over how to build a data project step-by-step from scratch.
By the end of this post, you will be able to quickly create data projects for any use case and see how the different parts of data systems work together.
NOTE: If you’d like an interactive approach to building data projects step-by-step, please follow the steps on this repo to learn using a jupyter notebook.
Video walkthrough
2. Setup
The project (de_project) is runnable on GitHub codespaces and locally. You have two options to run the code.
Option 1: Github codespaces (Recommended)
Steps:
- Create Github codespaces with this link.
- Wait for Github to install the requirements.txt. This step can take about 5minutes.

- Now open the
setup-data-project.ipynband it will open in a Jupyter notebook interface. You will be asked for your kernel choice, choosePython Environmentsand thenpython3.12.00 Global.
- The setup-data-project notebook that goes over how to create a data pipeline.
- In the terminal run the following commands to setup input data, run etl and run tests.
Option 2: Run locally
Steps:
- Clone this repo, cd into the cloned repo
- Start a virtual env and install requirements.
- Start Jupyter lab and run the
setup-data-project.ipynbnotebook that goes over how to create a data pipeline.
- In the terminal run the following commands to setup input data, run etl and run tests.
3. Parts of data engineering
Most data engineering tool falls into one of the parts shown below (as explained in this post)

In this post, we will review the parts of a data project and select tools to build a data pipeline. While we chose TPCH data for this project, anyone can choose any data set they find interesting and follow the below steps to quickly build their data pipeline.
Recommended reading: What are the key parts of data engineering
3.1. Requirements
The first step before you start should be defining precise requirements. Please work with the end users to define them (or define them yourself for side projects).
We will go over a few key requirements below.
Recommended reading: this post that goes over how to gather requirements for data projects in detail!.
3.1.1. Understand input datasets available
Let’s assume we are working with a car part seller database (tpch). The data is available in a duckdb database. See the data model below:

We can create fake input data using the create_input_data.py as shown below:
3.1.2. Define what the output dataset will look like
Let’s assume that the customer team has asked us to create a dataset that they will use for outreach (think cold emails, calls, etc.).
Upon discussion with the customer team, you discover that the output dataset requires the following columns:
For each customer (i.e., one row per customer)
- customer_key: The unique identifier for the customer
- customer_name: The customer name
- min_order_value: The value of the order with the lowest value placed by this customer
- max_order_value: The value of the order with the highest value placed by this customer
- avg_order_value: The average value of all the orders placed by this customer
- avg_num_items_per_order: The average number of items per order placed by this customer
Let’s write a simple query to see how we can get this (note that this process will take much longer with badly modeled input data). Run the below code in a Python REPL:
# simple query to get the output dataset
import duckdb
con = duckdb.connect("tpch.db")
con.sql("""
WITH order_items AS (
SELECT
l_orderkey,
COUNT(*) AS item_count
FROM
lineitem
GROUP BY
l_orderkey
),
customer_orders AS (
SELECT
o.o_custkey,
o.o_orderkey,
o.o_totalprice,
oi.item_count
FROM
orders o
JOIN
order_items oi ON o.o_orderkey = oi.l_orderkey
)
SELECT
c.c_custkey AS customer_key,
c.c_name AS customer_name,
MIN(co.o_totalprice) AS min_order_value,
MAX(co.o_totalprice) AS max_order_value,
AVG(co.o_totalprice) AS avg_order_value,
AVG(co.item_count) AS avg_num_items_per_order
FROM
customer c
JOIN
customer_orders co ON c.c_custkey = co.o_custkey
GROUP BY
c.c_custkey, c.c_name;
""")
con.commit()
con.close() # close connection, since DuckDB only allows one connection to tpch.db3.1.3. Define SLAs so stakeholders know what to expect
SLAs stand for service level agreement. SLAs define what end-users can expect from your service(data pipeline, in our case). While there are multiple ways to define SLAs, the common ones for data systems are:
Data freshnessData accuracy
Let’s assume that our stakeholders require the data to be no older than 12 hours. This means that your pipeline should run completely at least once every 12 hours. If we assume that the pipeline runs in 2 hours, we need to ensure that it is run at least every 10 hours so that the data is not older than 12 hours at any given time.
For data accuracy, we should define what accurate data is. Let’s define accuracy in the following section.
3.1.4. Define checks to ensure the output dataset is usable
We need to ensure that the data we produce is good enough for end-users to use. Typically, the data team works with end users to identify the critical metrics to check.
Let’s assume we have the following checks to ensure that the output dataset is accurate:
- customer_key: Has to be unique and not null
- avg_: columns should not differ by more than 5% compared to prior runs (across all customers)
Recommended reading: Types of data quality checks & Implementing data quality checks with Great Expectations
3.2. Identify what tool to use to process data
We have a plethora of tools to process data, including Apache Spark, Snowflake, Python, Polars, and DuckDB. We will use Polars to process our data because it is small. The Polars library is easy to install and use.
Recommended reading: Choosing tools for your data project
3.3. Data flow architecture
Most data teams have their version of the 3-hop architecture. For example, dbt has its own version (stage, intermediate, mart), and Spark has medallion (bronze, silver, gold) architecture.
You may wonder why we need this data flow architecture when we have the results easily with a simple query shown here.
While this is a simple example, in most real-world projects, you want to have standard, cleaned, and modeled datasets(silver) to create specialized datasets for end-users(gold). See below for how our data will flow:
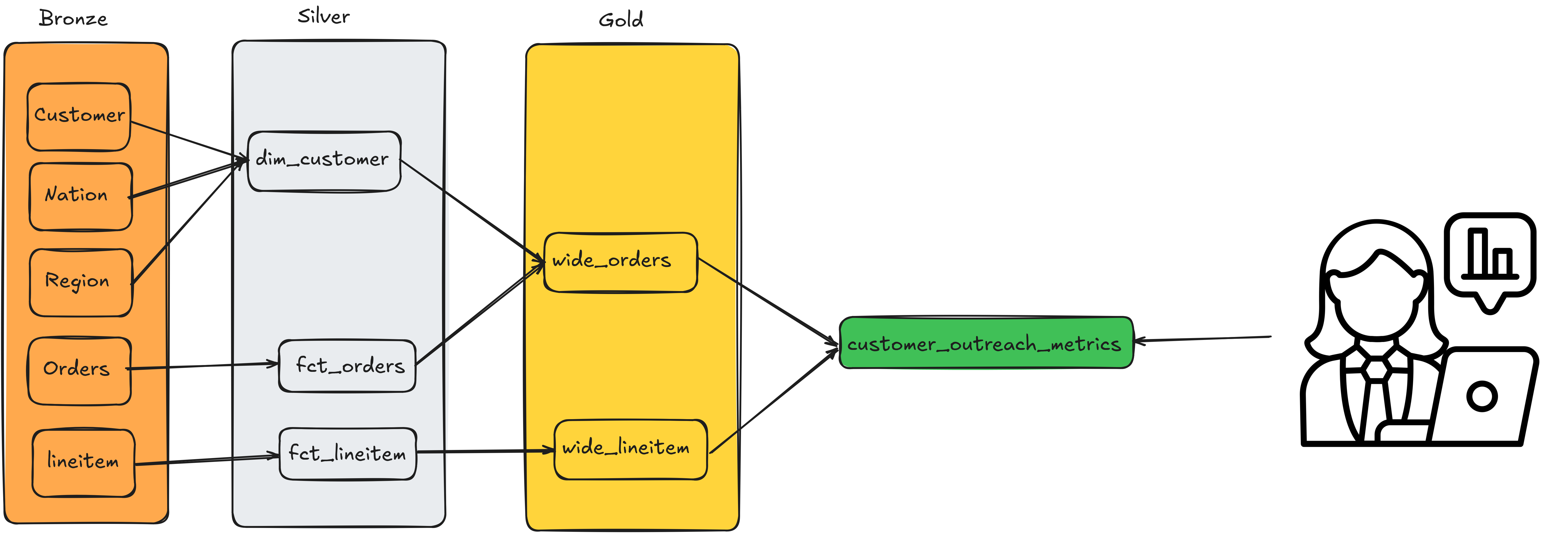
Recommended reading: Multi-hop architecture
3.3.1. Bronze: Extract raw data and confine it to standard names and data types
Since our dataset has data from customer, nation, region, order, and lineitem input datasets, we will bring those data into bronze tables. We will keep their names the same as the input datasets.
Let’s explore the input datasets and create our bronze datasets. In the Python REPL, do the following:
# read customer, order, and lineitem dataset from duckdb into Polars dataframe
import duckdb
import polars as pl
con = duckdb.connect("tpch.db")
customer_df = con.sql("select * from customer").pl()
orders_df = con.sql("select * from orders").pl()
lineitem_df = con.sql("select * from lineitem").pl()
nation_df = con.sql("select * from nation").pl()
region_df = con.sql("select * from region").pl()
con.close() #close DuckDB connection
# remove c_ and then rename custkey to customer_key
cleaned_customer_df = customer_df.rename(lambda col_name: col_name[2:]).rename({"custkey": "customer_key"})
# Remove the o_ and l_ from the order and lineitem table's column names
# We also rename customer key and order key
cleaned_orders_df = orders_df.rename(lambda col_name: col_name[2:]).rename({"custkey": "customer_key", "orderkey": "order_key"})
cleaned_lineitem_df = lineitem_df.rename(lambda col_name: col_name[2:]).rename({"orderkey": "order_key"})
# remove the n_ and r_ from the nation and region table's column names
cleaned_nation_df = nation_df.rename(lambda col_name: col_name[2:])
cleaned_region_df = region_df.rename(lambda col_name: col_name[2:])3.3.2. Silver: Model data for analytics
In the silver layer, the datasets are modeled using one of the popular styles (e.g., Kimball, Data Vault, etc.). We will use Kimball’s dimensional model, as it is the most commonly used one and can account for many use cases.
3.3.2.1. Data modeling
We will create the following datasets
- dim_customer: A customer-level table with all the necessary customer attributes. We will join nation and region data to the
cleaned_customer_dfto get all the attributes associated with a customer. - fct_orders: An order level fact(an event that happened) table. The fct_orders table will be the same as
cleaned_orders_dfsince theorderstable has all the necessary details about the order and is associated with dimension tables likecustomer_key. - fct_lineitem: A lineitem (items that are part of an order) fact table. This table will be the same as
cleaned_lineitem_dfsince thelineitemtable has all the lineitem level details and keys to associate with dimension tables likepartkeyandsuppkey.
Recommended reading: Data warehouse overview
Let’s create the silver tables in Python REPL as shown below:
# create customer dimension by left-joining all the necessary data
dim_customer = cleaned_customer_df\
.join(cleaned_nation_df, on="nationkey", how="left", suffix="_nation")\
.join(cleaned_region_df, on="regionkey", how="left", suffix="_region")\
.rename({
"name_nation": "nation_name",
"name_region": "region_name",
"comment_nation": "nation_comment",
"comment_region": "region_comment"
})
# Most fact tables are direct data from the app
fct_orders = cleaned_orders_df
fct_lineitem = cleaned_lineitem_df3.3.3. Gold: Create tables for end-users
The gold layer contains datasets required for the end user. The user-required datasets are fact tables joined with dimension tables aggregated to the necessary grain. In real-world projects, multiple teams/users ask for datasets with differing grains from the same underlying fact and dimension tables. While you can join the necessary tables and aggregate them individually for each ask, it leads to repeated code and joins.
To avoid this issue, companies typically do the following:
- OBT: This is a fact table with multiple dimension tables left joined with it.
- pre-aggregated table: The OBT table rolled up to the end user/team requested grain. The pre-aggregated dataset will be the dataset that the end user accesses. By providing the end user with the exact columns they need, we can ensure that all the metrics are in one place and issues due to incorrect metric calculations by end users are significantly reduced. These tables act as our end-users SOT (source of truth).
3.3.3.1. OBT: Join the fact table with all its dimensions
In our example, we have two fact tables, fct_orders and fct_lineitem. Since we only have one dimension, dim_customer, we can join fct_orders and dim_customer to create wide_orders. For our use case, we can keep fct_lineitem as wide_lineitem.
That said, we can easily see a case where we might need to join parts and supplier data with fct_lineitem to get wide_lineitem. But since our use case doesn’t require this, we can skip it!
Let’s create our OBT tables in Python REPL, as shown below:
3.3.3.2. Pre-aggregated tables: Aggregate OBTs to stakeholder-specific grain
According to our data requirements, we need data from customer, orders, and lineitem. Since we already have customer and order data in wide_orders, we can join that with wide_lineitem to get the necessary data.
We can call the final dataset customer_outreach_metrics (read this article that discusses the importance of naming).
Let’s create our final dataset in Python REPL, as shown below:
# create customer_outreach_metrics
# get the number of lineitems per order
order_lineitem_metrics = wide_lineitem.group_by(pl.col("order_key")).agg(pl.col("linenumber").count().alias("num_lineitems"))
# join the above df with wide_orders and group by customer key in wide orders to get avg, min, max order value & avg num items per order
customer_outreach_metrics = wide_orders\
.join(order_lineitem_metrics, on="order_key", how="left")\
.group_by(
pl.col("customer_key"),
pl.col("name").alias("customer_name"))\
.agg(
pl.min("totalprice").alias("min_order_value"),
pl.max("totalprice").alias("max_order_value"),
pl.mean("totalprice").alias("avg_order_value"),
pl.mean("num_lineitems").alias("avg_num_items_per_order"),
)3.4. Data quality implementation
As part of our requirements, we saw that the output dataset needs to have 1. Unique and distinct customer_key 2. Variance in avg_* columns between runs should not be more than 5% (across all customers)
While the first test is a simple check, the second one requires that we use the data from previous runs and compare it with the current run’s data or store the sum(avg_*) of each run. Let’s store the run-level metrics in a run_metadata table (in sqlite3).
Our pipelines should run data quality checks before making the data available to your end users. This ensures that you can catch any issues before they can cause damage.
Recommended reading: - Types of data quality checks - Implementing data quality checks with Great Expectations - Write-Audit-Publish pattern
Let’s see how we can implement DQ checks in a Python REPL, as shown below:
import json
# get current run's metrics
curr_metrics = json.loads(
customer_outreach_metrics\
.select(
pl.col("avg_num_items_per_order").alias("sum_avg_num_items_per_order"),
pl.col("avg_order_value").cast(int).alias("sum_avg_order_value")
)\
.sum()\
.write_json())[0]
# Store run metadata in a table
import sqlite3
# Connect to SQLite database
conn = sqlite3.connect('metadata.db')
# Create a cursor object
cursor = conn.cursor()
# Insert data into the run_metadata table
cursor.execute('''
INSERT INTO run_metadata (run_id, metadata)
VALUES (?, ?)
''', ('2024-09-15-10-00', json.dumps(curr_metrics)))
# Commit the changes and close the connection
conn.commit()
conn.close()
# Assume that another run of the data pipeline has been completed
# Get the most recent data from the run_metadata table
import sqlite3
# Connect to SQLite database
conn = sqlite3.connect('metadata.db')
# Create a cursor object
cursor = conn.cursor()
# Fetch the most recent row based on run_id
cursor.execute('''
SELECT * FROM run_metadata
ORDER BY run_id DESC
LIMIT 1
''')
# Get the result
most_recent_row = cursor.fetchone()
# Close the connection
conn.close()
# get the most recent metric
prev_metric = json.loads(most_recent_row[1])
# get current metric
# This assumes the pipeline is rerun
curr_metric = json.loads(
customer_outreach_metrics\
.select(
pl.col("avg_num_items_per_order").alias("sum_avg_num_items_per_order"),
pl.col("avg_order_value").cast(int).alias("sum_avg_order_value")
)\
.sum()\
.write_json())[0]
# Compare with current data for variance percentage
def percentage_difference(val1, val2):
if val1 == 0 and val2 == 0:
return 0.0
elif val1 == 0 or val2 == 0:
return 100.0
return abs((val1 - val2) / ((val1 + val2) / 2)) * 100
prev_metric['sum_avg_order_value'] = int(float(prev_metric['sum_avg_order_value']))
comparison = {}
for key in curr_metric:
if key in prev_metric:
comparison[key] = percentage_difference(curr_metric[key], prev_metric[key])
print(comparison)
# code to check if variance < 5
for k, v in comparison.items():
if v >= 5:
raise Exception(f"Difference for {k} is greater than 5%: {v}%")
# Insert current run data into the run_metadata table
# Store run metadata in a table
import sqlite3
# Connect to SQLite database
conn = sqlite3.connect('metadata.db')
# Create a cursor object
cursor = conn.cursor()
comparison_json = json.dumps(comparison)
# Insert data into the run_metadata table
cursor.execute('''
INSERT INTO run_metadata (run_id, metadata)
VALUES (?, ?)
''', ('2024-09-15-12-00', comparison_json))
# Commit the changes and close the connection
conn.commit()
conn.close()3.5. Code organization
Deciding how to organize your code can be overwhelming. Typically, companies use one of the following options to organize code:
- Based on multi-hop architecture. E.g. see this dbt folder structure
- Based on existing company standards.
3.5.1. Folder structure
We can use the following folder structure for our use case(and most real-life projects).
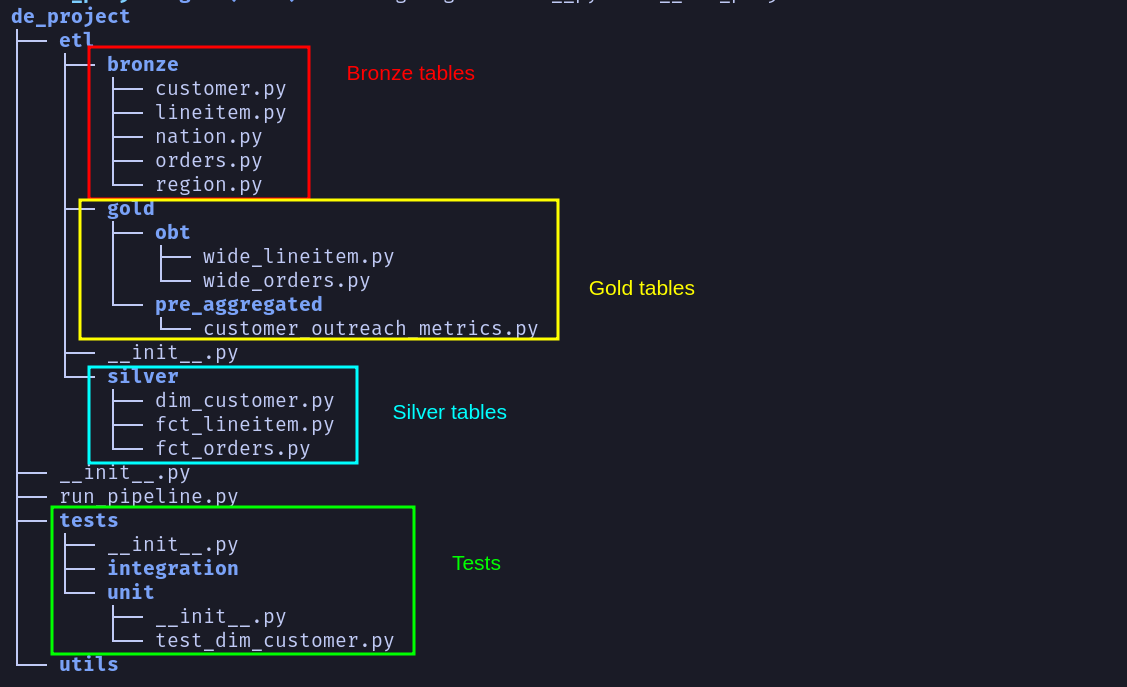
Each file under the elt folder will have the code necessary to generate that dataset. The above folder structure enables anyone new to the project to quickly understand where the code to create a certain dataset will be.
3.5.2. Code modularity
We have the code to create the necessary tables; now, we have to put them into functions that are easy to use and maintain.
Recommended reading: How to write modular python code
We will define the function create_dataset for each table in the Python script for our use case. Having a common named function will enable
- Consistent naming. For example:
dim_customer.create_dataset,customer_outreach_metrics.create_dataset - Pull out code commonalities into a base class. Moving code into a common base class will be covered in a future post.
Let’s see what functions we would want to include in the etl/gold/pre-aggregated/customer_outreach_metrics.py.
Note We have moved code that involves reading/writing to metadata into de_project/utils/metadata.py.
import json
import polars as pl
# The `de_project/utils/metadata.py` file has code to get and insert data into the metadata table
from utils.metadata import get_latest_run_metrics, insert_run_metrics
def create_dataset(wide_lineitem, wide_orders):
order_lineitem_metrics = wide_lineitem.group_by(pl.col("order_key")).agg(
pl.col("linenumber").count().alias("num_lineitems")
)
return (
wide_orders.join(order_lineitem_metrics, on="order_key", how="left")
.group_by(pl.col("customer_key"), pl.col("name").alias("customer_name"))
.agg(
pl.min("totalprice").alias("min_order_value"),
pl.max("totalprice").alias("max_order_value"),
pl.mean("totalprice").alias("avg_order_value"),
pl.mean("num_lineitems").alias("avg_num_items_per_order"),
)
)
def percentage_difference(val1, val2):
if val1 == 0 and val2 == 0:
return 0.0
elif val1 == 0 or val2 == 0:
return 100.0
return abs((val1 - val2) / ((val1 + val2) / 2)) * 100
def check_no_duplicates(customer_outreach_metrics_df):
# check uniqueness
if (
customer_outreach_metrics_df.filter(
customer_outreach_metrics_df.select(pl.col("customer_key")).is_duplicated()
).shape[0]
> 0
):
raise Exception("Duplicate customer_keys")
def check_variance(customer_outreach_metrics_df, perc_threshold=5):
prev_metric = get_latest_run_metrics()
if prev_metric is None:
return
prev_metric['sum_avg_order_value'] = int(float(prev_metric['sum_avg_order_value']))
curr_metric = json.loads(
customer_outreach_metrics_df.select(
pl.col("avg_num_items_per_order").alias("sum_avg_num_items_per_order"),
pl.col("avg_order_value").cast(int).alias("sum_avg_order_value"),
)
.sum()
.write_json()
)[0]
comparison = {}
for key in curr_metric:
if key in prev_metric:
comparison[key] = percentage_difference(curr_metric[key], prev_metric[key])
for k, v in comparison.items():
if v >= perc_threshold:
raise Exception(f"Difference for {k} is greater than 5%: {v}%")
def validate_dataset(customer_outreach_metrics_df):
# Data quality checks
check_no_duplicates(customer_outreach_metrics_df)
check_variance(customer_outreach_metrics_df)3.6. Code testing
We will use pytest to test our code. Let’s write a test case to test the create_dataset function for the dim_customer dataset. The test ccode is at de_project/tests/unit/dim_customer.py.
Recommended reading: How to use pytest to test your code
We can run the tests via the terminal using
3.7. Next steps
In the next post, we will cover the following:
- Containerizing the pipeline
- Scheduling pipeline with Airflow
- Moving common parts of code to the base class
- Persisting tables in a cloud storage system (e.g. S3)
- Deploying the pipeline to the cloud with Terraform
- Setting up monitoring and alerting infrastructure
- Setting up a dashboard to visualize the output
4. Conclusion
To recap, we saw:
- Gathering requirements
- Defining data flow
- Identifying data processor to use
- Implementing data quality checks
- Organizing code
- Testing code
If you want to quickly put together a data project, use the step-by-step approach in this post, and you will be up and running in no time.
Please let me know in the comment section below if you have any questions or comments.