1. Introduction
Slowly changing dimension 2 is a critical data modeling technique used in most warehouses. If you are
Wondering if there is a simple way to create an SCD table
Struggling to handle edge cases with SCD2 creation
Having to write a lot of code to ensure that SCD2 pipeline failures don’t corrupt your data
Then this post is for you.
By the end of this post, you will have learned how to effectively use MERGE INTO to build an SCD2 pipeline. Imagine being able to enable end users to see how the data looked at any point in time. What if you could replace multiple SQL queries with a single-small query that just works.
In this post, we will explain how MERGE INTO works and how to use it to build an SCD2 pipeline. You will also receive a code recipe that you can repurpose for your use case.
Prerequisites
1.1. Code and setup
The code and setup instructions for the code in this post are available here.
2. MERGE INTO is used to UPDATE/DELETE/INSERT rows into a target table based on data in the source table
MERGE INTO is used to update, delete, or insert rows into a target table based on data in a source table.
Merge into is similar to a full outer join. Instead of the join clause, you have a target USING source on t.id=s.id, and instead of producing an output, it updates the target table.
The updates to the target table are based on 3 clauses:
WHEN MATCHEDThe rows from the source that match rows from the target can be used to UPDATE or DELETE target rows.WHEN NOT MATCHEDThe rows from the source with no match in the target table can be INSERTED into the target table.WHEN NOT MATCHED BY SOURCEThe rows from the target that do not match in the source table can be UPDATED or DELETED.
| Clause | INSERT | UPDATE | DELETE |
|---|---|---|---|
WHEN MATCHED |
❌ | ✅ | ✅ |
WHEN NOT MATCHED |
✅ | ❌ | ❌ |
WHEN NOT MATCHED BY SOURCE |
❌ | ✅ | ✅ |
The 3 clauses can have additional conditions. You can define multiple of the above clauses with additional conditions, which will be evaluated in the order that they are specified.
Note: In the WHEN MATCHED clause, we should ensure that each row in the source table matches only one row in the target table for UPDATE or DELETE. This restriction ensures that each target row can only be updated by a single source row, as MERGE INTO was designed primarily as a row-level update mechanism.
3. SCD2 table pipeline: INSERT new data, UPDATE existing data, and DELETE stale data
Consider the following example: An upstream customer table used by your company’s application populates an SCD2 dim_customer table managed by the data engineering team.
To keep the SCD2 dim_customer up to date, you need to do the following:
- You will need to
insert a new row in the dim_customer table for each new customerin the upstream customer table. - If an
existing customer changed their data(e.g., email address change), you will need to update the dim_customer table and do the following:- Mark the existing row for the customer as old by setting an appropriate valid_to date and is_current to False.
- Insert a new row for the customer (with the updated email address) and set appropriate valid_from date and is_current to True.
- If an existing customer has been
deleted in the upstream customer table, mark the customer as is_active = False in the dim_customer table.
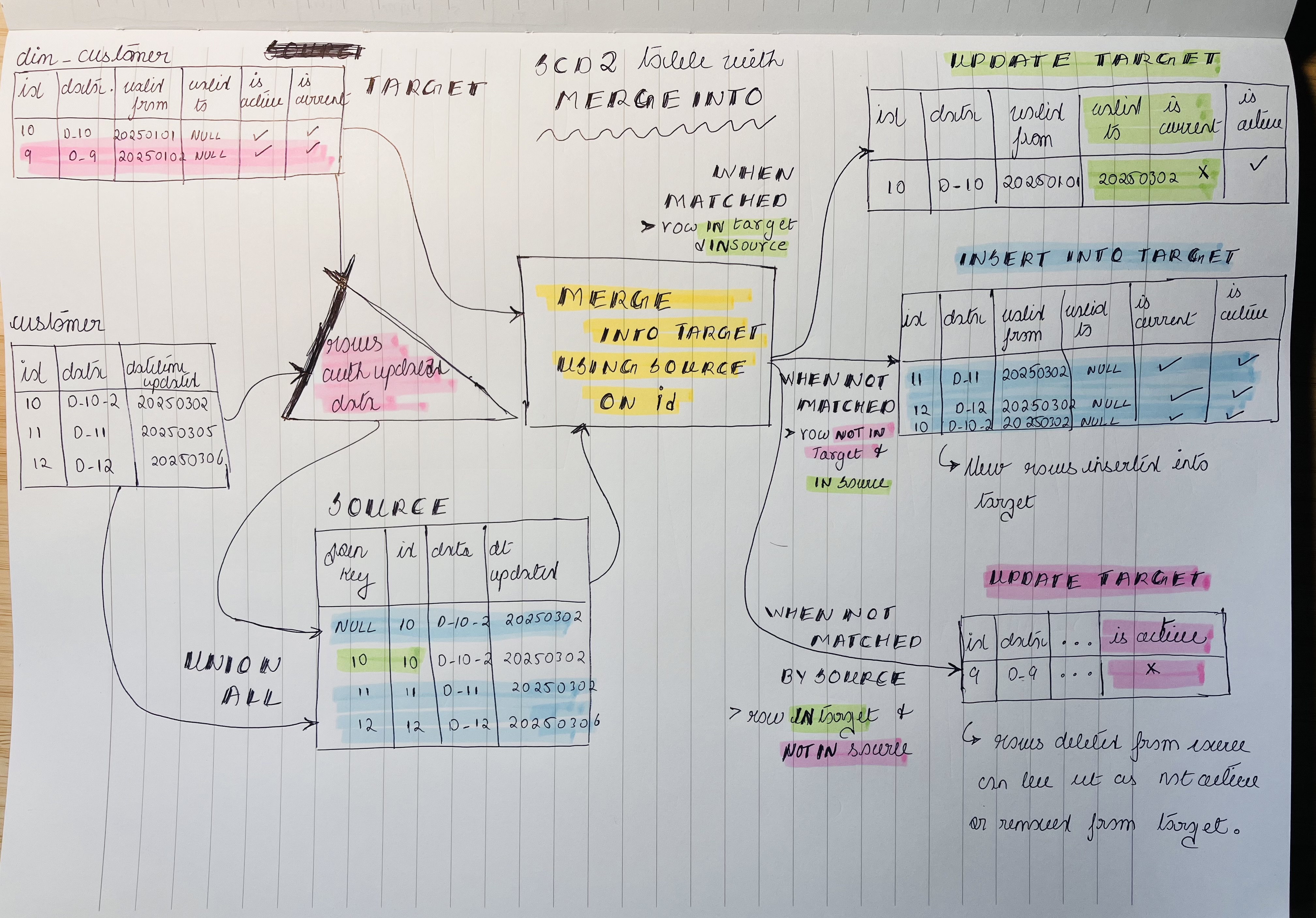
Let’s look at the MERGE INTO code for our SCD2 pipeline:
With customers_with_updates as (
select c.*
from prod.db.customer c
join prod.db.dim_customer dc
on c.customer_id = dc.customer_id -- Customer exists in dim_customer
where c.datetime_updated > dc.datetime_updated -- ensure that the update in upstream customer is newer than the latest data in dim_customer
and dc.is_current = true -- only look at the most current state of customer in dim_customer
)
MERGE INTO prod.db.dim_customer t -- target dim_customer to update
USING (
select customer_id as join_key, * from prod.db.customer -- New customers to be INSERTED, existing customers to be UPDATED
union all
select NULL as join_key, * from customers_with_updates -- Existing customers with updated values to be INSERTED
) s
ON t.customer_id = s.join_key -- natural key for customer
WHEN MATCHED AND is_current = true AND s.datetime_updated > t.datetime_updated -- condition to UPDATE most recent customers in dim_customer that have had updates
THEN UPDATE SET is_current = false, valid_to = s.datetime_updated
WHEN NOT MATCHED
THEN INSERT (customer_id,email,first_name,datetime_updated,valid_from,is_current,is_active) -- condition to INSERT new customers and customers with updates
VALUES (s.customer_id,s.email,s.first_name,s.datetime_updated,s.datetime_updated,true,true)
WHEN NOT MATCHED BY SOURCE -- condition to set deleted customers in dim_customer to be in-active
THEN UPDATE SET is_active = false AND valid_to = current_timestamp()In the above SQL, there are 3 key columns: 1. customer_id, a natural key (upstream customer’s primary key) uniquely identifies a customer. 2. The datetime_updated timestamp column indicates when the upstream customer row was updated (it could be inserted or updated). This provides us with a mechanism to identify the new changes with each pipeline run. If you do not have a timestamp column, you can compare the data values to check for changes. 3. valid_from and valid_to timestamp columns indicate the time range during which a row in the SCD2 table was active.
3.1. Source includes 2 versions of upstream customer data: one for insert and the other for update
As the SCD2 pipeline involves INSERTS and UPDATES, we need to define the rows to be considered for updates and inserts. In the code, we will define our source as a combination of the following:
- All the data from the customer table to ensure that
new rows are inserted and existing rows (in target) are updatedwith appropriate valid_to and that is_current is set to False. - Only the data in the source that has corresponding rows in the table -> These indicate updated data and will be
inserted as new rows into the target.
We implement the above in SQL as follows:
source as is + an additional column called
join_keywhose value will be the natural key of this table. This includesnew rows to be inserted and existing rows (in target) to be updated.source as is + an additional column called
join_keywhose value will be NULL. This includesnew rows to be inserted into the target.
With customers_with_updates as (
select c.*
from prod.db.customer c
join prod.db.dim_customer dc
on c.customer_id = dc.customer_id -- Customer exists in dim_customer
where c.datetime_updated > dc.datetime_updated -- ensure that the update in upstream customer is newer than the latest data in dim_customer
and dc.is_current = true -- only look at the most current state of customer in dim_customer
)
MERGE INTO prod.db.dim_customer t -- target dim_customer to update
USING (
select customer_id as join_key, * from prod.db.customer -- New customers to be INSERTED, existing customers to be UPDATED
union all
select NULL as join_key, * from customers_with_updates -- Existing customers with updated values to be INSERTED
)
-- .....There are 2 key techniques we use: 1. NULL as join_key technique to insert rows (that have IDs in the target table). 2. The c.datetime_updated > dc.datetime_updated and dc.is_current = true technique indicates rows needing updating. * The datetime comparison ensures that the upstream change is more recent than the value in dim_customer. * The is_current = true ensures that we only get one row per customer (in SCD2, there will be multiple rows per customer, but only one is_current=True per customer).
3.2. Updates to the target table
The target table is updated by 3 MATCHING clauses, they are:
- The
WHEN MATCHED AND is_current = true AND s.datetime_updated > t.datetime_updatedclause is used to update existing SCD2 rows, set them as not current, and set the vaid_to date as the date that the upstream customer table was last updated. - The
WHEN NOT MATCHEDclause inserts “new” rows into the SCD2 table. In this context, new customers and customers with updated data are inserted into the dim_customer table. - The
WHEN NOT MATCHED BY SOURCEclause is used to update rows in the Target that no longer have a corresponding row in the upstream customer table(due to customer deletion) as inactive.
-- condition to UPDATE most recent customers in dim_customer that have had updates
WHEN MATCHED AND is_current = true AND s.datetime_updated > t.datetime_updated THEN UPDATE SET is_current = false, valid_to = s.datetime_updated
-- condition to INSERT new customers and customers with updates
WHEN NOT MATCHED THEN INSERT (customer_id,email,first_name,datetime_updated,valid_from,is_current,is_active) VALUES (s.customer_id,s.email,s.first_name,s.datetime_updated,s.datetime_updated,true,true)
-- condition to set deleted customers in dim_customer to be in-active
WHEN NOT MATCHED BY SOURCE THEN UPDATE SET is_active = false AND valid_to = current_timestamp()4. Conclusion
To recap, we saw
- How MERGE INTO works
- How to create an SCD2 pipeline with MERGE INTO
- Techniques to create the source data for MERGE INTO
The next time you are working on a pipeline to manage an SCD2 table, use MERGE INTO to make your (and your colleagues) life a whole lot easier.
Since MERGE INTO is atomic, even when your pipeline fails, you can rest assured that you are not providing end users with partial or incorrect data.
Please let me know in the comment section below if you have any questions or comments.