Event driven pipelines
Event driven systems represent a software design pattern where a logic is executed in response to an event. This event can be a file creation on S3, a new database row, API call, etc. A common use case is to process a file after it lands on a cloud storage system.
A key component of event-driven pipelines are serverless functions. Serverless functions are user defined functions that can be run, in response to an event. In this post, we will see how to trigger a spark job using AWS lambda functions, in response to a file being uploaded to an S3 bucket.

Every cloud provider has their own version of serverless functions. AWS has lambda, GCP has cloud functions and Azure has azure functions. There are also open source alternatives like openfaas and Apache OpenWhisk, which require some management.
Lambda function to trigger spark jobs
In the setup section we will set up S3 to send an event to our lambda function for every file uploaded. This event will be of the format:
{
"Records": [
{
"eventVersion": "2.1",
"eventSource": "aws:s3",
"awsRegion": "us-east-1",
"eventTime": "2021-04-04T15:46:16.575Z",
"eventName": "ObjectCreated:Put",
"userIdentity": {
"principalId": ""
},
"requestParameters": {
"sourceIPAddress": ""
},
"responseElements": {
"x-amz-request-id": "",
"x-amz-id-2": ""
},
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "landingZoneFileCreateTrigger",
"bucket": {
"name": "<your-bucket-prefix>-landing-zone",
"ownerIdentity": {
"principalId": ""
},
"arn": "arn:aws:s3:::<your-bucket-prefix>-landing-zone"
},
"object": {
"key": "review.csv",
"size": 120576,
"eTag": "",
"sequencer": ""
}
}
}
]
}In order to handle this incoming event, we will create a lambda_handler function. AWS Lambda requires that this python function accepts 2 input parameters.
- event: A JSON object indicating the type and information about the trigger of the event.
- context: This is a context object that provides information about the invocation details, function, and execution environment.
Our spark cluster, (which we will create in the setup section) will be AWS EMR, which is an AWS managed spark cluster. AWS EMR provides a standard way to run jobs on the cluster using EMR Steps. These steps can be defined as a JSON (see SPARK_STEPS in code below).
On accepting an incoming S3 file upload event, our lambda function will add 3 jobs (aka steps) to our spark cluster that:
- copies the uploaded file from S3 to our EMR cluster’s HDFS file system.
- runs a naive spark text classification script that classifies the data from the previous step.
- copies the clean data to a destination S3 location.
Here is the sequence diagram for the code flow and the code.
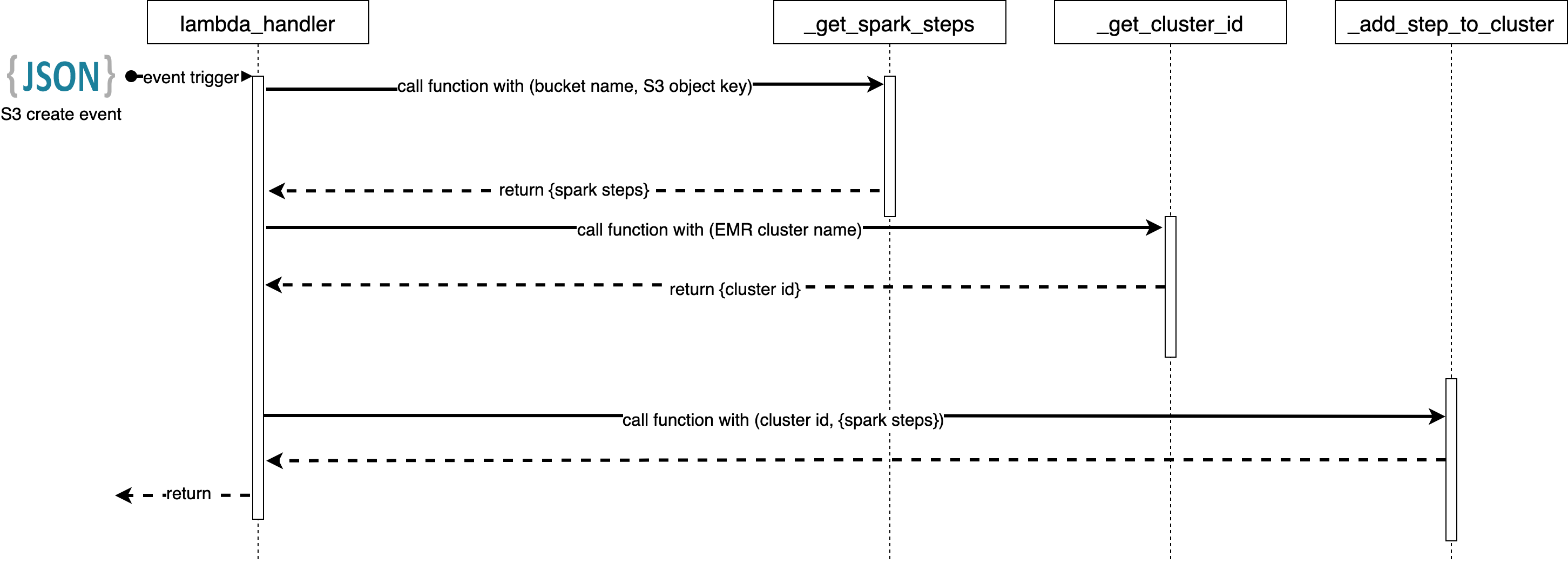
We get the name of the bucket and the file that was uploaded from the event json.
import json
import os
from typing import Dict, Any, List
import urllib.parse
import boto3
def _get_spark_steps(ip_data_bkt: str, ip_data_key: str) -> List[Dict[str, Any]]:
# These are environment variables of the lambda function
output_bkt = os.environ.get("OUTPUT_LOC")
script_bkt = os.environ.get("SCRIPT_BUCKET")
SPARK_STEPS = [
{
"Name": "Move raw data from S3 to HDFS",
"ActionOnFailure": "CANCEL_AND_WAIT",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"s3-dist-cp",
f"--src=s3://{ip_data_bkt}/{ip_data_key}",
"--dest=/movie",
],
},
},
{
"Name": "Classify movie reviews",
"ActionOnFailure": "CANCEL_AND_WAIT",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"spark-submit",
"--deploy-mode",
"client",
f"s3://{script_bkt}/random_text_classifier.py",
],
},
},
{
"Name": "Move clean data from HDFS to S3",
"ActionOnFailure": "CANCEL_AND_WAIT",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"s3-dist-cp",
"--src=/output",
f"--dest=s3://{output_bkt}/clean_data/",
],
},
},
]
return SPARK_STEPS
def _get_cluster_id(cluster_name: str = "sde-lambda-etl-cluster") -> str:
"""
Given a cluster name, return the first cluster id
of all the clusters which have that cluster name
"""
client = boto3.client("emr")
clusters = client.list_clusters()
return [c["Id"] for c in clusters["Clusters"] if c["Name"] == cluster_name][0]
def _add_step_to_cluster(cluster_id: str, spark_steps: List[Dict[str, Any]]) -> None:
"""
Add the given steps to the cluster_id
"""
client = boto3.client("emr")
client.add_job_flow_steps(JobFlowId=cluster_id, Steps=spark_steps)
def lambda_handler(event, context):
"""
1. get the steps to be added to a EMR cluster.
2. Add the steps to the EMR cluster.
"""
bucket = event["Records"][0]["s3"]["bucket"]["name"]
key = urllib.parse.unquote_plus(
event["Records"][0]["s3"]["object"]["key"], encoding="utf-8"
) # this will give us the name of the uploaded file
spark_steps = _get_spark_steps(ip_data_bkt=bucket, ip_data_key=os.path.dirname(key))
_add_step_to_cluster(cluster_id=_get_cluster_id(), spark_steps=spark_steps)
returnSetup and run
In order to try along with the code, you will need the following:
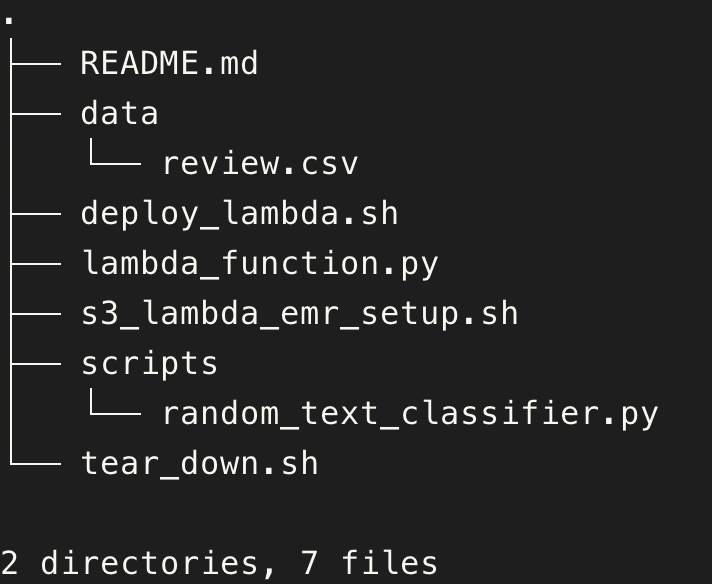
You can clone this repository to get the code.
The folder structure will look like the following:
If this is your first time using AWS, make sure to check for presence of the EMR_EC2_DefaultRole and EMR_DefaultRole default roles as shown below.
If the roles are not present, create them using the following command:
The setup script, s3_lambda_emr_setup.sh does the following:
- Sets up S3 buckets for storing input data, scripts, and output data.
- Creates a lambda function and configures it to be triggered when a file lands in the input S3 bucket.
- Creates an EMR cluster.
- Sets up policies and roles granting sufficient access for the services.
Note In the following sections, replace <you-bucket-prefix> with a bucket prefix of your choosing. For example, if you choose to use a prefix of sde-sample, then in the following sections, use sde-sample in the place of <your-bucket-prefix>.
The EMR cluster can take up to 10 minutes to start. In the meantime, we can trigger our lambda function by sending a sample data to our input bucket. This will cause the lambda function to add the jobs to our EMR cluster.
In the AWS EMR UI, you can see that the steps are added to your EMR cluster. The steps are ordered in reverse in the UI.
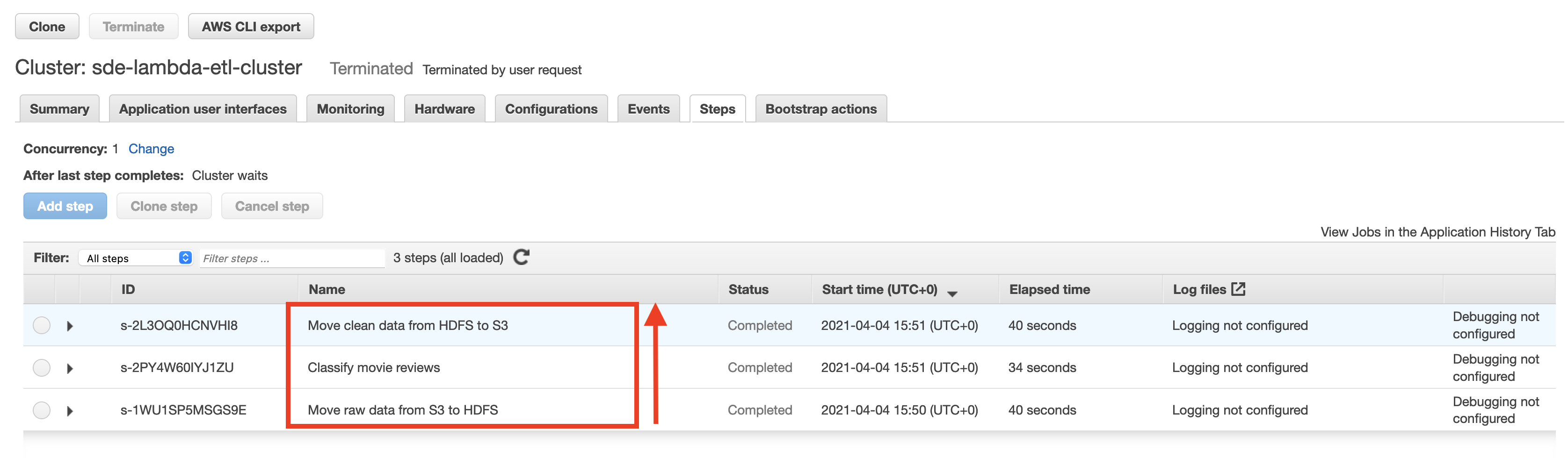
Once the EMR cluster is ready, the steps will be run. You can check the output using the following command
You will see a clean_data folder which will contain your clean data, in parquet format. To understand the classification script, please read the random_text_classifier.py script file.
Monitoring and logging
Our lambda functions’ executions (and any print statements) will be logged in AWS CloudWatch. Go to the lambda UI and select monitor. You will be taken to the AWS CloudWatch logs page.
| Click monitor icon in lambda UI | click the log file |
|---|---|
 |
 |
You can also enable lambda re-tries in case of failures and setup AWS CloudWatch failure alerts. ## Teardown
When you are done, don’t forget to tear down the buckets, lambda function, EMR cluster, roles and policies. Use the tear_down.sh script as shown below.
Conclusion
Hope this article gives you a good understanding of how to trigger a spark job from a lambda function. Event driven patterns are very helpful when your input arrives at non deterministic times. We can also configure retries on errors with lambda, have multiple triggers, have forking logics, and have concurrencies, etc with AWS lambdas.
Since lambdas have a quick response time, they are also ideal for near real time data processing pipelines. The next time you have to develop a data pipeline that must run when a particular event occurs, try out lambda. As always, please leave any questions or comments in the comment section below.