I have seen, heard and been asked questions and comments like
What is Kafka and When should I use it?
I don’t understand why we have to use Kafka
The objective of this post is to get you up to speed with what Apache Kafka is, when to use them and the foundational concepts of Apache Kafka with a simple example.
What is Apache Kafka
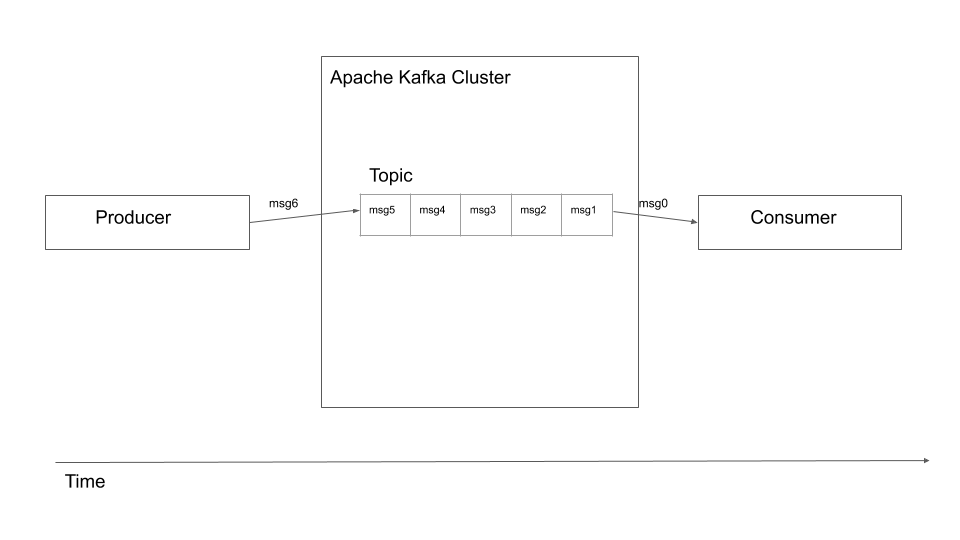
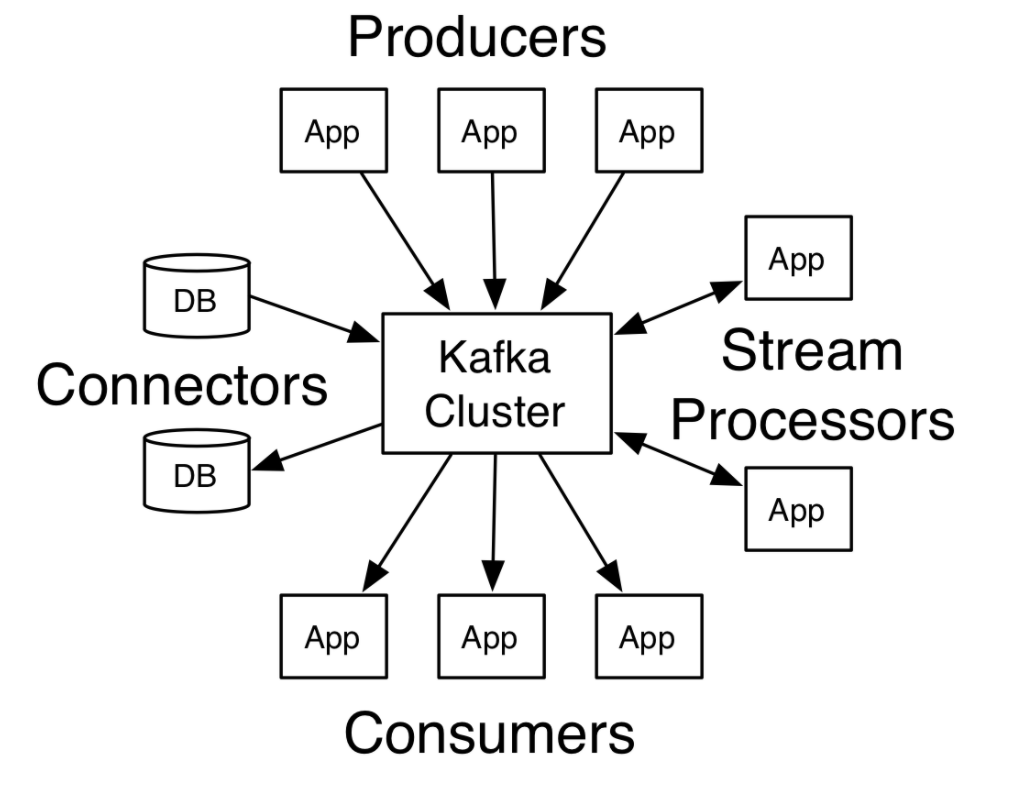
First let’s understand what Apache Kafka is. According to the official definition, it is a distributed streaming platform. This means that you have a cluster of connected machines (Kafka Cluster) which can
Receive data from multiple applications, the applications producing data(aka messages) are called
producers.Reliably store the received data(aka message).
Allow applications to read the stored data, these applications are called
consumerssince they are consuming the data(aka message). Consumers usually read one message at a time.Guarantee order of data. That is, if a message, say m1, is received by the cluster at time t1 and another message, say m2, is received by the cluster at later time t1 + 5 sec, then a consumer reading the messages will read m1 before m2.
Provide
at-least oncedelivery of data. This means every message sent to the Apache Kafka cluster is guaranteed to be received by a consumer at least once. This means that at the consumer there may be duplication of data. The most common reason for this is that the message sent by producer getting lost due to network failures. There are techniques to deal with this, which we will see in a future post.Has support for running apps on the Kafka cluster using
connectorand framework to process messages calledStreams API.
Going forward we will be using message to denote the data that the producer sends to the Apache Kafka cluster and the data that the consumer reads from Apache Kafka cluster.
Why use Apache Kafka
In order to understand why Apache Kafka is popular with streaming apps, lets understand what is generally used, and why Apache Kafka is a better choice for certain use cases.
Currently used, RESTful systems - HTTPS
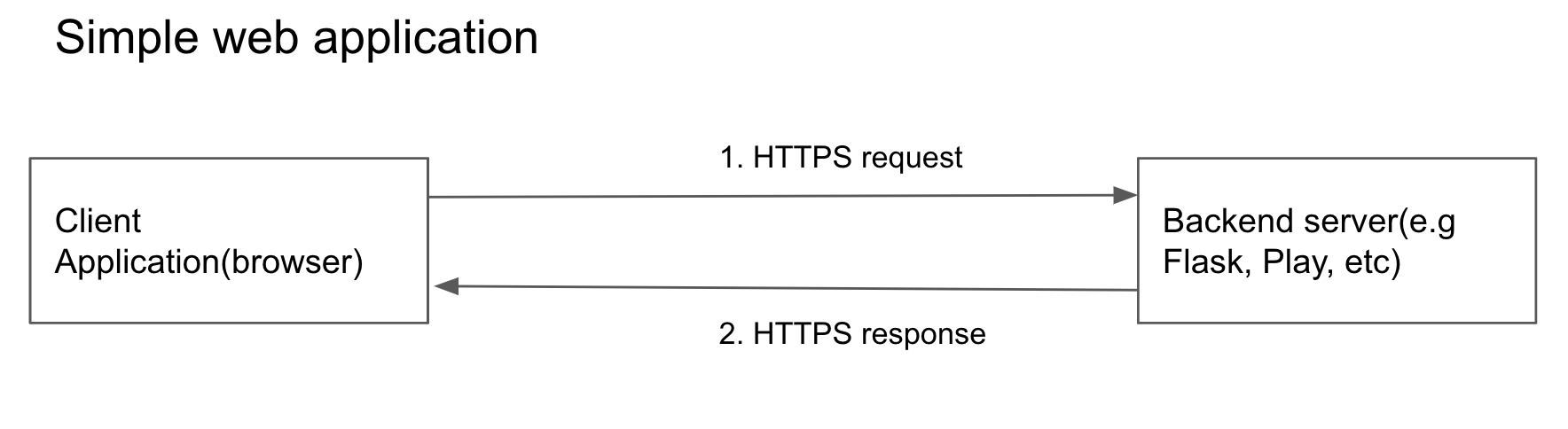
Modern web applications are RESTful services. What this means is that
A server or client (Usually your browser) sends a HTTP(S)(either
GET,PUT,POST,DELETEthere are more, but these are the popular ones) request to another server(the backend server).The server that receives this HTTP(S) request, authenticates the request, does custom processing according to the logic you have and responds with a status code and data in most cases.
The server or client making the request receives the response and proceeds with the logic you have defined.
In most cases the request is made from the client(your browser) to a server(aka backend) running on the cloud which does the required processing and responds with the appropriate data.
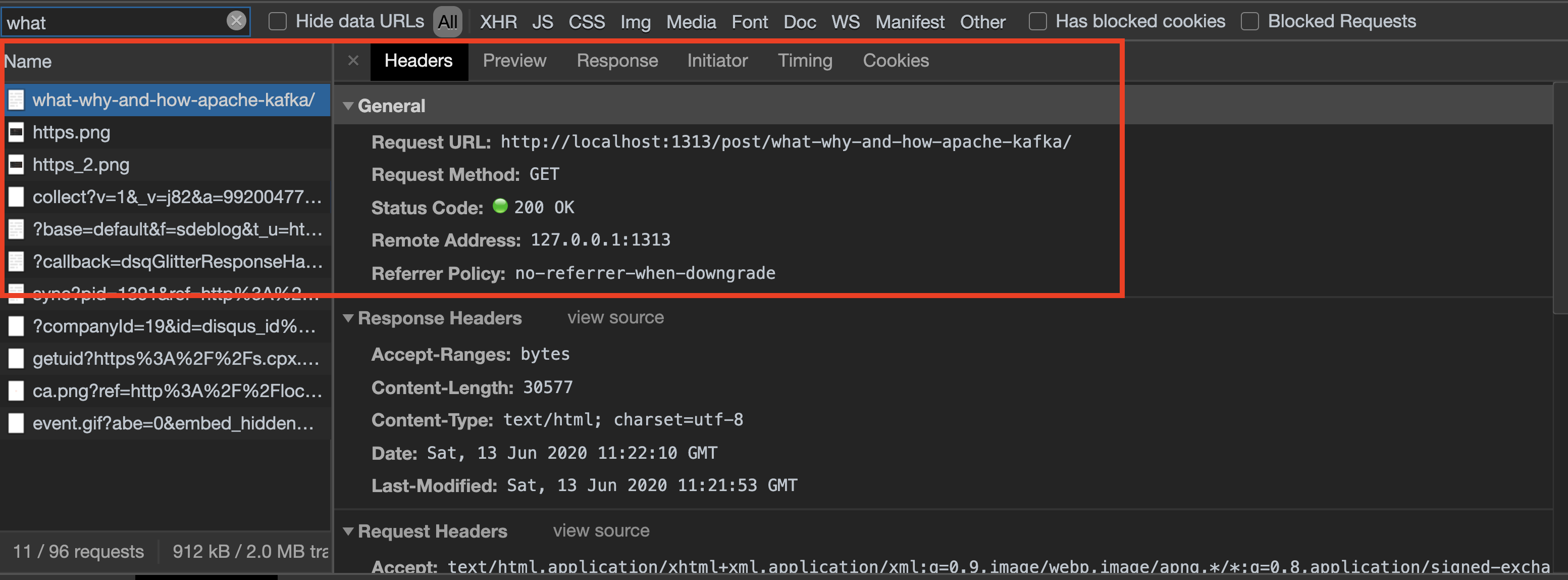
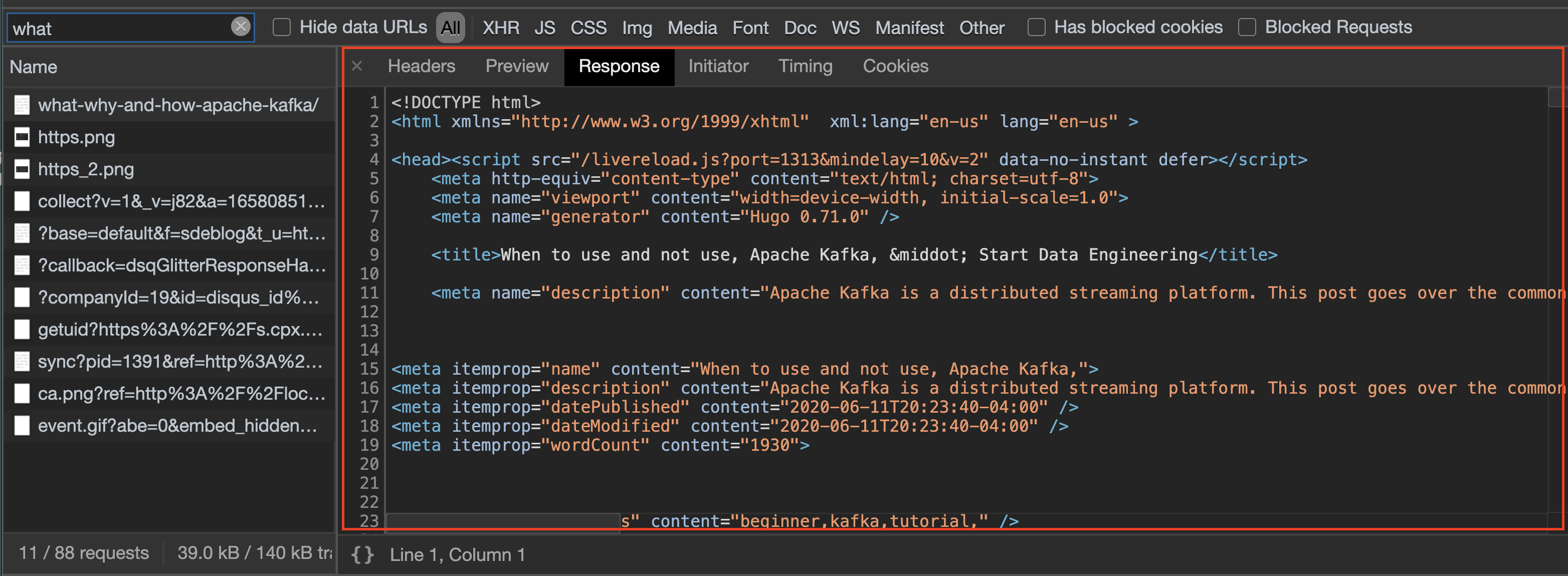
For example, in this website if you right click on this page -> inspect -> network tab and refresh the webpage, search for what, Click on it and select the Headers tab, you will be able to see the HTTPS requests that your client(aka browser) has sent to the backend. In the Response tab you will also be able to see the response, which in this case will be an HTML to be displayed.
Common use cases
The RESTful services model works fine for most cases. Let’s go over the use cases below and try to think of efficient ways to solve them
Let’s assume our application has 10Million users and we want to record user actions(hover, move, idle, etc) every 5 seconds. This will create 120Million user action events per minute. In this case we don’t have to make the user aware that we have successfully processed their action information. To respond to 120Million requests per minute, we will need multiple servers running copies of your application. How will you solve this?
Let’s say one of our applications need to send a message to 3 other applications. In this case assume the application that sends the message does not need to know if the message was processed. How will you solve this?
Spend some time brainstorming the above use cases before reading on.
One key thing that sets apart the above use cases from a normal web request is that we don’t have to process the data and respond immediately. In case 1 we don’t have to process the data immediately, we can just store the data in some place and process it later, depending on project constraints. In case 2 we can send HTTPS requests to 3 other applications and get responses from those applications, but since we do not need the sender application to know the state of the process we can write the data to a location and have the other 3 applications read from it.
This is basically what Apache Kafka does. In Apache Kafka cluster you have Topics which are ordered queues of messages.
Solution for case 1
We will send 120Million messages per minute into a Topic lets say user-action-event from the your user client(web browser) and you can have your producer applications read from them at their own pace of processing.
Solution for case 2
We will have our producer application send messages to a Topic lets say multi-app-events then all the 3 applications can read from this topic. This reduces the burden on the producer as it only cares about sending the messages.
You can set up the producer as a fire and forget model, where the producer sends a message to the Apache Kafka cluster and moves on or message acknowledgement model where the producer sends a message to the Apache Kafka cluster and waits to receive a confirmation from the Apache Kafka cluster. Use fire and forget model if a few message losses is tolerable and to increase the producer speed. Use message acknowledgement model when you need to be certain that you don’t want lose a message due to network failures or such.
 ref: https://kafka.apache.org/documentation/
ref: https://kafka.apache.org/documentation/
Simple Example
Let’s understand how Apache Kafka works with a simple example.
prerequisites
Setup
First let’s set up an Apache Kafka docker container. For this example we will use the popular wurstmeister image. We can use the Confluent docker image as well, but it requires 8GB of docker memory.
First let’s clone the wurstmeister repo.
Then we modify the kafka service section in the docker-compose.yml file, to have the following configuration
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper:3.4.6
ports:
- "2181:2181"
kafka:
build: .
ports:
- "9092:9092"
expose:
- "9093"
environment:
KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka:9093,OUTSIDE://localhost:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_LISTENERS: INSIDE://0.0.0.0:9093,OUTSIDE://0.0.0.0:9092
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sockThe environment variables KAFKA_* are settings allowing connection between Apache Kafka, Apache Zookeeper(the service that does cluster management) and from producers and consumers outside the docker container.
Now start the Apache Kafka and Apache Zookeeper docker containers as shown below
The -d runs the docker containers in detached mode. Each node within the Apache Kafka cluster is called a broker. Now you can check the list of containers running using
You will see
| Name | Command | State | Ports |
|---|---|---|---|
| kafka-docker_kafka_1 | start-kafka.sh | Up | 0.0.0.0:9092->9092/tcp, 9093/tcp |
| kafka-docker_zookeeper_1 | /bin/sh -c /usr/sbin/sshd … | Up | 0.0.0.0:2181->2181/tcp, 22/tcp, 2888/tcp, 3888/tcp |
You can see that your kafka-docker_kafka_1 (Apache Kafka container) and kafka-docker_zookeeper_1 have started.
For this simple example we will be using Python’s Kafka library. You can install it using
In Apache Kafka, as we saw earlier messages are stored in queues called topics. By default topics are created automatically when a producer pushes a message to that topic. This is controlled using the auto.create.topics.enable broker configuration variable.
Producer & Consumers
Let’s assume we have a simple event listener on the client which sends a message to the backend server every 3 seconds, we can write a naive producer in python and lets call it user_event_producer.py
from datetime import datetime
import json
from kafka import KafkaProducer
import random
import time
import uuid
EVENT_TYPE_LIST = ['buy', 'sell', 'click', 'hover', 'idle_5']
producer = KafkaProducer(
value_serializer=lambda msg: json.dumps(msg).encode('utf-8'), # we serialize our data to json for efficent transfer
bootstrap_servers=['localhost:9092'])
TOPIC_NAME = 'events_topic'
def _produce_event():
"""
Function to produce events
"""
# UUID produces a universally unique identifier
return {
'event_id': str(uuid.uuid4()),
'event_datetime': datetime.now().strftime('%Y-%m-%d-%H-%M-%S'),
'event_type': random.choice(EVENT_TYPE_LIST)
}
def send_events():
while(True):
data = _produce_event()
time.sleep(3) # simulate some processing logic
producer.send(TOPIC_NAME, value=data)
if __name__ == '__main__':
send_events()Now the consumer script. Let’s call it user_event_consumer.py
import json
from kafka import KafkaConsumer
TOPIC_NAME = 'events_topic'
consumer = KafkaConsumer(
TOPIC_NAME,
auto_offset_reset='earliest', # where to start reading the messages at
group_id='event-collector-group-1', # consumer group id
bootstrap_servers=['localhost:9092'],
value_deserializer=lambda m: json.loads(m.decode('utf-8')) # we deserialize our data from json
)
def consume_events():
for m in consumer:
# any custom logic you need
print(m.value)
if __name__ == '__main__':
consume_events()Some key points from the above python script
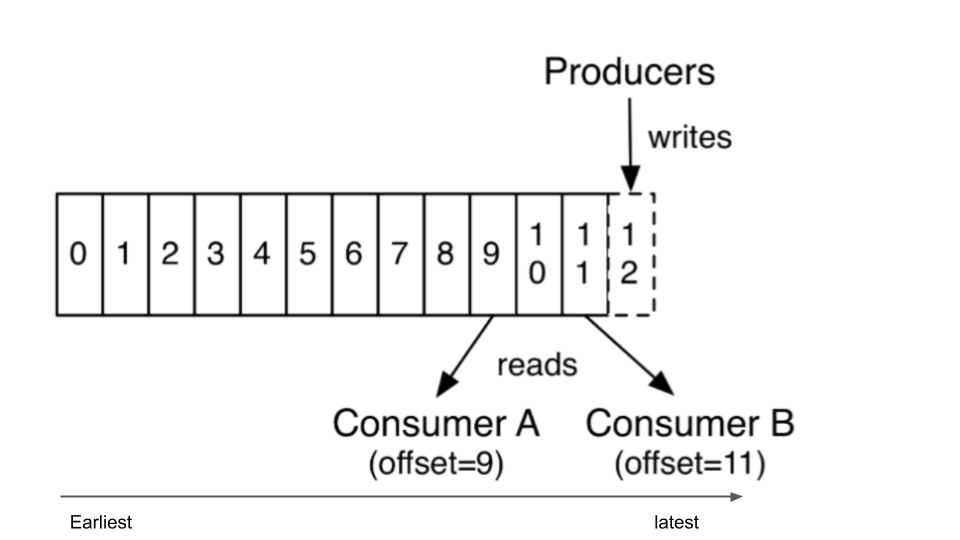
offset: denotes the position of a message within the topic. This helps the consumers decide from which message to start reading.auto_offset_reset: The possible values areearliestandlatestwhich tells the consumer to read from the earliest available message or the latest message the consumer has yet to read in the topic respectively.group_id: denotes the group the consumer application is a part of. Usually multiple consumers are run in a group and group id enables consumers to keep track of which messages have been read and which have not.
 ref: https://kafka.apache.org/documentation/
ref: https://kafka.apache.org/documentation/
Let’s start the python scripts
you will start seeing something like
{"event_id": "3f847c7b-e015-4f01-9f5c-81c536b9d89b", "event_datetime": "2020-06-12-21-12-27", "event_type": "buy"}
{"event_id": "e9b51a88-0e86-47cc-b412-8159bfda3128", "event_datetime": "2020-06-12-21-12-30", "event_type": "sell"}
{"event_id": "55c115f1-0a23-4c89-97b2-fc388bee28f5", "event_datetime": "2020-06-12-21-12-33", "event_type": "click"}
{"event_id": "28c01bae-5b5b-421b-bc8b-f3bed0e1d77f", "event_datetime": "2020-06-12-21-12-36", "event_type": "sell"}
{"event_id": "8d6b1cbe-304f-4dec-8389-883d77f99084", "event_datetime": "2020-06-12-21-12-39", "event_type": "hover"}
{"event_id": "50ffcd7c-5d40-412e-9223-cc7a26948fa9", "event_datetime": "2020-06-12-21-12-42", "event_type": "hover"}
{"event_id": "6dbb5438-482f-4f77-952e-aaa54f11320b", "event_datetime": "2020-06-12-21-12-45", "event_type": "click"}You can stop the python consumer script using ctrl + c. Remember your producer is running in the background. You can stop this using
The above kills a process based on its name. Now let’s check out Apache Kafka cluster to see the list of available topics, we must see the topic that was created by our producer at events_topic.
docker exec -it $(docker ps -aqf "name=kafka-docker_kafka") bash # get inside the Kafka container
$KAFKA_HOME/bin/kafka-topics.sh --list --bootstrap-server kafka:9092 # list all the topics in this Kafka cluster
# you will see the topics
# __consumer_offsets
# events_topic
# view messages stored in the `events_topic` topic
$KAFKA_HOME/bin/kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic events_topic --from-beginning
exit # exit the containerAuto commit
Now let’s assume that our consumer does some processing and writes the processed data to our database. In this case, if our consumer dies and we restart it, based on our current configuration setting we will reprocess already processed data. Take some time to think about why this happens and what configuration setting we can use to prevent this.
We can avoid this issue by setting the auto_offset_reset setting to latest instead of the earliest that we have in our KafkaConsumer code sample. Every consumer commits the latest offset position of the message it reads into a metadata topic in Kafka every 5 seconds(set as default using auto.commit.interval.ms). This feature is set by default to true using enable.auto.commit. The topic which holds the offset information is called __consumer_offsets.
Partitions
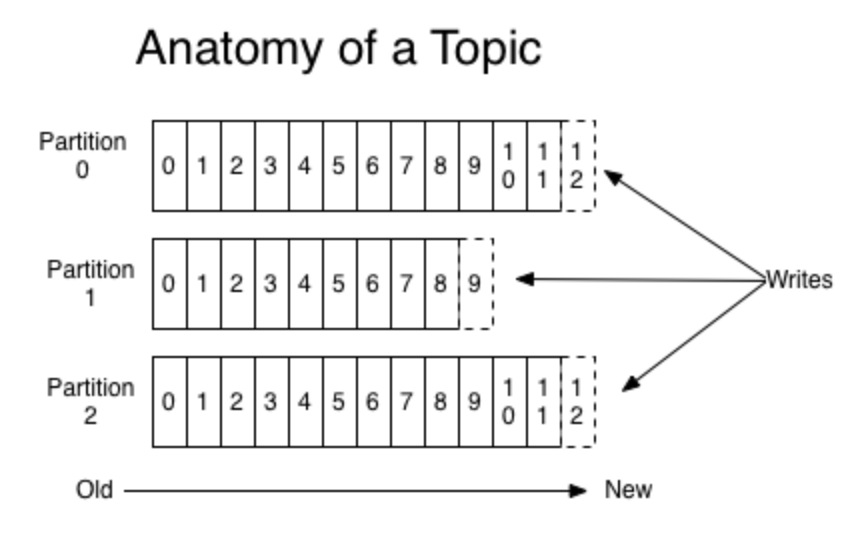
As with most distributed systems, Apache Kafka distributes its data across multiple nodes within the cluster. A topic in Apache Kafka is chunked up into partitions which are duplicated(into 3 copies by default) and stored in multiple nodes within the cluster. This prevents data loss in case of node failures.
 ref: https://kafka.apache.org/documentation/
ref: https://kafka.apache.org/documentation/
In the above diagram you can see how a topic is split up into partitions and how the incoming messages are duplicated amongst them.
You can stop all the running docker containers using
Recap
In this post we saw
What Apache Kafka is
When to use Apache Kafka with a few common use cases
Apache Kafka concepts - Producer, Topic, Broker, Consumer, Offset and auto commit
There are more advanced concepts like partition size, partition function, Apache Kafka Connectors, Streams API, etc which we will cover in future posts.
Conclusion
Hope this article gives you a good introduction of Apache Kafka and insights into when to use and not use it. Let me know if you have any comments or question in the comments section below.