I have seen and been asked the following questions by students, backend engineers and analysts who want to get into the data engineering industry.
What approach should i take to land a Data Engineering job?
I really want to get into DE. What can I do to learn more about it?
In this article, I will try to provide a general approach that you as a beginner, student, backend engineer or analyst can use to land your first data engineering job. This is the approach I followed to get my first data engineering job.
What is a Data Engineer
Before we try to solve a problem, we should define it clearly. The job definition of a data engineer varies widely depending on the company and team. Many backend engineers are basically data engineers in many cases. For our case, we define a data engineer purely based on the skills and not on the job title.
Upon researching the popular job boards, understanding the current direction of the data engineering industry, interviewing and hiring data engineers, we can define a beginner data engineer as someone with the skills shown below
Knowledge of a scripting language such as
python.In depth knowledge of OLTP data modeling and when to use it such as
star schema,indexes, etcIn depth knowledge of OLAP data modeling and when to use it such as
distribution key,partitioning, etcUnderstanding of Unix based system and commands.
Knowledge of a distributed data store such as
HDFS,S3.Knowledge of a distributed batch data processing framework such as
Apache sparkKnowledge of a data pipeline orchestration tool such as
Apache AirflowBasic knowledge of queuing system such as
kafkaWorking knowledge using a cloud provider,
AWS,GCP,Azure
There is a more detailed list here.
As you can see, it is an extensive list. This is in addition to knowing CS engineering basics such as basics of web development, FE constructs, BE constructs, APIs and databases.
Starting point
Now that we have defined what a data engineer is, we can form a plan to get there. Your starting point may be different given your individual circumstances, but generally people who want to move into data engineering fall into one of the following categories
Beginner (no knowledge of computers)
Student (CS degree either undergrad or grad school)
Backend/ Fullstack/ Frontend Engineer (either FE or BE or other disciplines that involves creating software)
Data Analyst/ Scientist
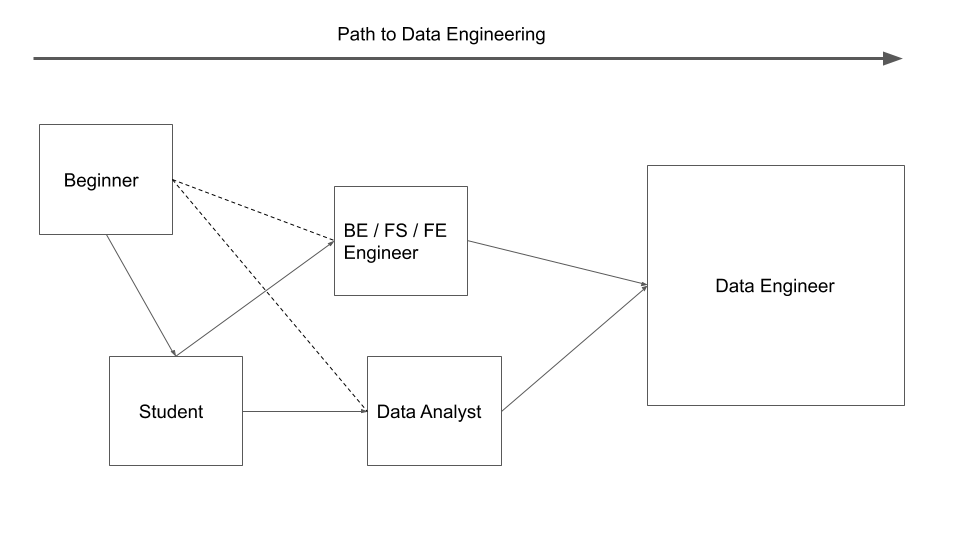
1. Beginner
Everyone starts here. The best and surest way for someone here to get into data engineering is to first get a job as a Backend Engineer or Fullstack Engineer. These jobs will provide you the basic skills you will need to land a DE role. So how do you get into Backend/Fullstack Engineering? There are 3 main approaches
College, CS Degree - very long, tried and true approach, expensive, good chance of getting an engineering job(depending on the college and individual pre)
Coding Bootcamp - short, a bit of wild west but mostly good approach, expensive, ok-ish chance of getting an engineering job (this may be changing)
Self learning - can be very very long, without a mentor or someone to guide you this can get tricky, not a great chance of getting an engineering job
Which route you choose will depend on your individual circumstances. Irrespective of the route you take, Leetcode is crucial. make sure you know the commonly asked interview questions for the company you are going to be interviewing at.
2. Student (CS)
This is a good place to be in. You have good knowledge of computers, a few programming languages, what an API is, algorithms, data structures, machine learning, distributed systems and operating systems. If you are here, there is a possibility that you might be able to land a junior data engineer but these roles are very rare. In order to land a good Backend/Fullstack engineer role, you will need to
Build a few projects(ideally >=3 or a big one), probably a CRUD based web app with mid-complex logic and a database (
MySQLorpostgres). Make sure it actually works and that potential employers can try it out easily online, host it on a cloud provider such asAWS,Heroku,Netlify,GCP, etc. Adding in adesign diagram, description, why and how you built it as aREADME.mdongithubwould show understanding of product requirements and clear communication.Leetcode is crucial. For better or worse, companies heavily rely on algorithms and data structure type questions to recruit engineers. Make sure you know the commonly asked interview questions for the company you are going to be interviewing at.
3. Backend / Fullstack / Frontend Engineer
You might already be doing some data engineering work. Luckily, you have most of the skills needed to learn the rest. Side projects are great, but work experience weighs a lot more in hiring decisions. Here are some actions you can take to increase your chances of getting an interview
Take initiative and build a data pipeline at your current job. Try to work on a project that adds real value to your company, this can be something simple from increasing developer productivity by identifying common bug patterns to complex ones such as replicating tables from databases(usually caused by
microservice hellproblem) to an OLAP database. This will become a key point on your resume which leads to interviews. For example- If you are working on a
webappat your job, in your free time, build a simple data processing pipeline usingpythonandcronto analyze the logs and find the places where the most errors occur in your code base. This might have the potential to reduce bugs. - If this provides valuable information, present it to your boss. Even if there are no new projects building trust, showing interest and recognition will make sure that when a new project comes in, you are the go-to person.
- Most companies these days are aware of the benefits of data and analytics, so keep trying to come up with and implement new ideas for work. This will lead to more valuable experience than just side projects.
- If you are working on a
Another interesting project maybe understanding the changes in your database using
debeziumandkafka, like shown here.Sometimes it is difficult to implement a new project at work for various reasons. In such cases, try building a side project (example) and make sure to write out a detailed
README.mdon yourgithubrepo and note the skills you learnt on yourlinkedinprofile for keyword based search discovery by recruiters.In order to become a data engineer the most crucial skill is understanding the data. Most companies have really bad data documentation so take some time to really understand what data your company has, where it comes from, how it is collected, the ETL process (if any), what are the nuances in the data, etc. This is by far what helps you create efficient and effective data projects.
You can also create a data dictionary for your company. While this may not be technical, this will prove extremely valuable to your company, build trust and you will be able to see patterns in the data pipeline that you can improve. You will be in a really good position to get any data work that may happen in the future at your company.
Ask for it, not a lot of engineers ask their managers for specific work. Engineers are usually ok with whatever gets assigned to them. A very important skill to have is to
manage up, i.e letting your manager know what work you want to do and coming up with a selling point that adds value to the company.
As I mention in the previous sections, Leetcode is crucial for interviews.
4. Data Analyst/ Scientist
You are already in a good position to transition, but there will probably need to be work done in the engineering part. You might already be using SQL to pull data from a data warehouse and python to do analysis. You can start by
Automating one data pull using python.
Scheduling that data pull to run at certain time every day using
cron.Automating more data pulls. For complex data pulls setup
Airflow. You can try it here sample airflow project.Understand your data warehouse infrastructure. (e.g. size of the warehouse cluster, partitions, how data is loaded etc).
If you can, do some NLP or big data processing in
Apache SparkusingAWS EMRor inGCP dataflow. This would be great.As a data analyst/scientist you probably have a very clear understanding of the data, where it comes from, how it is used, nuances in it, etc. Use this knowledge to build or advise a better data processing pipeline.
You can also create a data dictionary for your company. While this may not be technical, this will prove extremely valuable to your company, build trust and you will be able to see patterns in the data pipeline that you can improve.
Ask for it, It is usually difficult to get cross team work but you won’t know unless you try. A very important skill to have is to
manage up, i.e letting your manager know what work you want to do and coming up with a selling point that adds value to the company.
As I mention in the previous sections, Leetcode is crucial for interviews.
Conclusion
TL; DR
Research the data engineering job postings.
Use the technical requirements as a base to build projects at work/self that actually help your company/you in some way.
Put those points as experience on your resume.
Practice interview questions on Leetcode regularly.
Remember sometimes the job title may be
engineerorbackend engineerbut the job responsibilities may be that of adata engineer
Repeat the above 4 steps and you will be in a much better place in 3 months.
Hope this article gives you some direction and helps you land your first data engineering job. Good luck. Let me know the approach you plan to take in the comments below or send us an email here.