Many data engineers coming from traditional batch processing frameworks have questions about real time data processing systems, like
“What kind of data model did you implement, for real-time processing?” “trying to figure out how people build real-time data warehouse solution”
This post is a review of what real-time data processing means and how it is used in most companies.
What is real-time data processing
First we need to define what real-time data processing is. When someone says real time we think micro seconds but that is not always the case. There are different levels of real-time systems
micro second systems (e.g. space ships which require custom hardware)
milli second systems (e.g. real time auctions )
second or minute systems (
real-timedata processing pipeline )We are going to be talking about the
real-timedata processing pipeline and for convenience let’s say the taken to process the data is max 5 minutes.
1. Decide what needs to be real-time
First step is deciding what data needs to be made available in real-time. This is usually driven by the business requirements. Most real-time data required for analysts or data scientists, would be ok with about a 1h delay. When the consumer of your real-time data is another service or application then a lower time delay would be ideal, since this data may be used for automatic consumption (e.g anomaly detection). Usually in most companies the data that is processed in real time is a very small subset of the incoming data. A trade-off between the business requirements and software development costs need to be made here, this will depend on the individual business requirement.
2. Modeling Technique
Most companies populate their data ware houses using a combination of real-time and batch processing. The consumer of the data will need to know when and how to use the real time data v the batch data that is available. This is called a lambda architecture. When processing data in real-time most data processing is at a row level, if you want to do aggregates (eg number of clicks on the last minute, etc) you will need to use windowing (also called mini-batching).
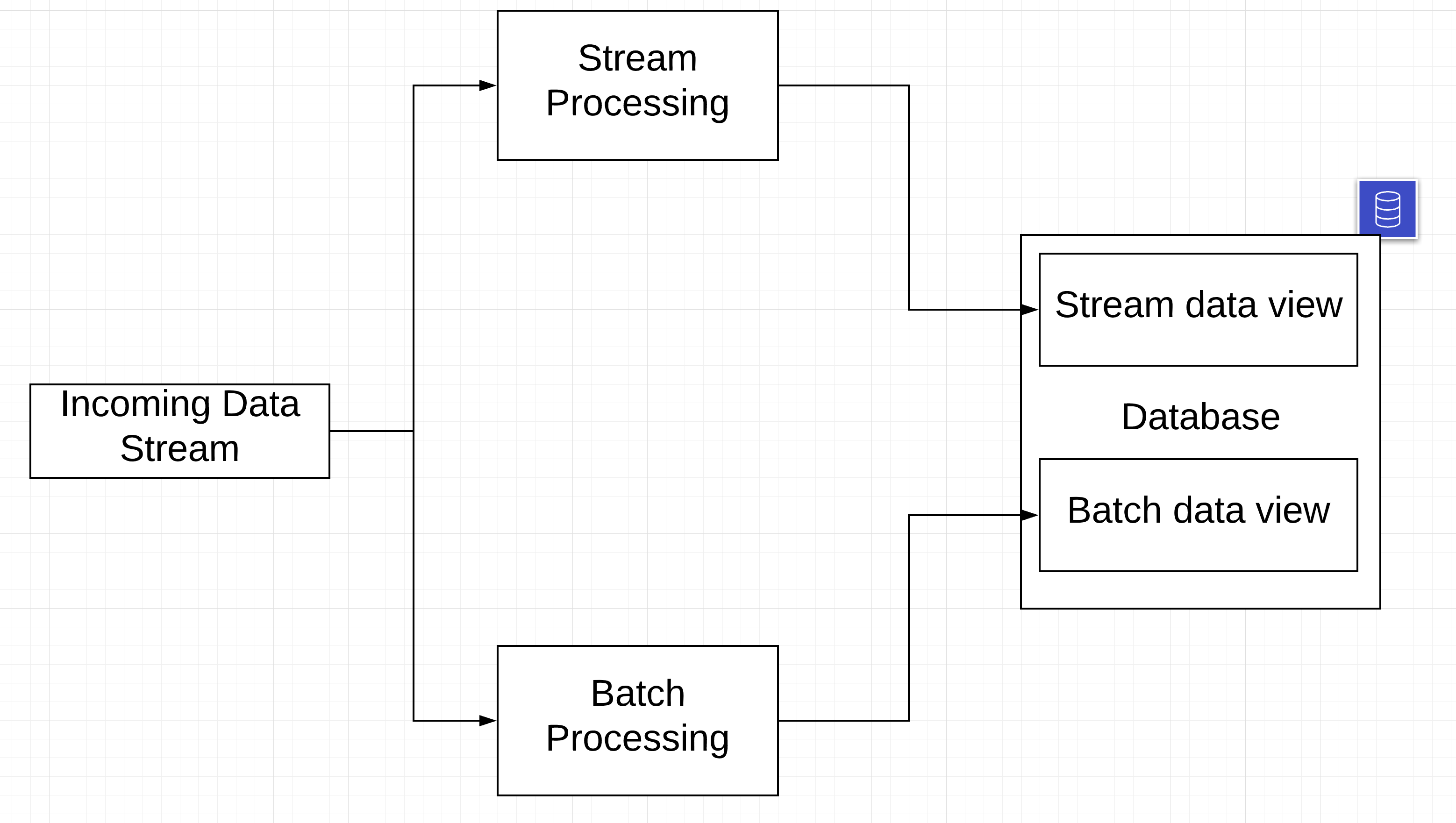
3. Always write time modular data processors
This concept applies to not only real-time data processing, but all data processing systems. Write your data processing logic in such a way that it can scale to any arbitrary time frame. This is important because you may be doing the same processing over a large batch in batch processing and over a very small (mini) batch in your real-time processing. In this scenario real-time processing will give you the most recent data, but may miss out on late arriving events or out of order events, but the batch process can be designed to catch them (handle late arriving events).
For example if you are writing a SQL query to aggregate the errors in your log data
# DO NOT DO THIS
def _get_data_proc_query():
return 'select log_id, count(errors) err_count from log_data where datetime_field > now() - 5 min'
# DO THIS
def _get_data_proc_query(start_time, end_time):
return f'select log_id, count(errors) err_count from log_data where datetime_field >= {start_time} and datetime_field < {end_time}'Note that in the above the recommended function can
- Be executed over any time input interval v the non recommended one as it is not modular on time.
- Be preventing late arriving messages from corrupting the err_count of another time frame.
4.Tools
There are many open source stream processing tools that do real-time data processing, deciding which one to use depends on your current and future business requirements. Given below are some of the most popular options
Apache Spark : One the most popular data processing frameworks, if not the most popular one. It has a huge community and is a very active framework. Apache Spark was initially a batch processing framework but later incorporated streaming by using batch on a much smaller scale (mini-batch), but recently have release a pure streaming implementation.
Apache Flink : This was designed as a streaming first framework and as such provides advanced stream based processing mechanisms and is usually faster than spark when performing stream based repetitive processing (e.g ML optimizations).
Akka : This is a library available in Java and Scala based on the actor model. This is generally used when the requirements are more domain specific, than can be achieved with the Apache Spark or Apache Flink data processing model. For example if you are streaming in data and based on very complex domain requirements, using the incoming data to build a knowledge graph.
Conclusion
Hope this gives you a good overview of real-time data processing and an idea of how to get started with it. If you have any questions please leave a comment below or contact us.