One of the most common issues when ingesting and processing user generated events is, how to deal with late arriving events. Yet this topic is not extensively discussed. Some of the general issues that data engineers usually have are
“What should be considered the event time?” “How to choose the date partition so our data pipelines are idempotent?” “there must be some deterministic pattern for generating batch runs so that time partitions are immutable and so that backfill tasks can be generated?”
In this post we cover 3 key decisions you will need to make when dealing with late arriving events.
Lets look at a data infrastructure for ingesting and processing events.
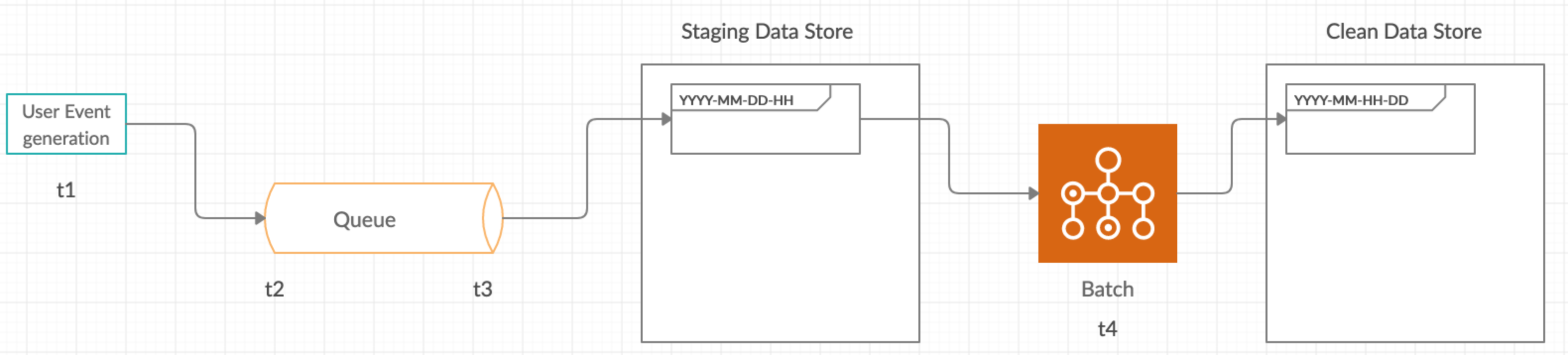
In the above diagram we see a common pattern used to ingest, process and store events data in a format that can be used.
- Events are produced by multiple clients (eg. a user like event on a social media app).
- The events are pushed to a queue such as Apache Kafka/ Amazon Kinesis.
- The events from the queue are written to a raw staging data store (eg. AWS S3), partitioned by date with hour level granularity yyyy-mm-dd-hh. The level of granularity depends on the use case.
- A scheduled batch process, that runs every hour, processes data from raw staging data store and stores it in the final data store.
- The final data store will be used as the source of truth for running analytical queries.
- The final data store will usually be partitioned by date with hour level granularity yyyy-mm-dd-hh. This is to enable the query engine to do partition pruning.

What is a late arriving event ?
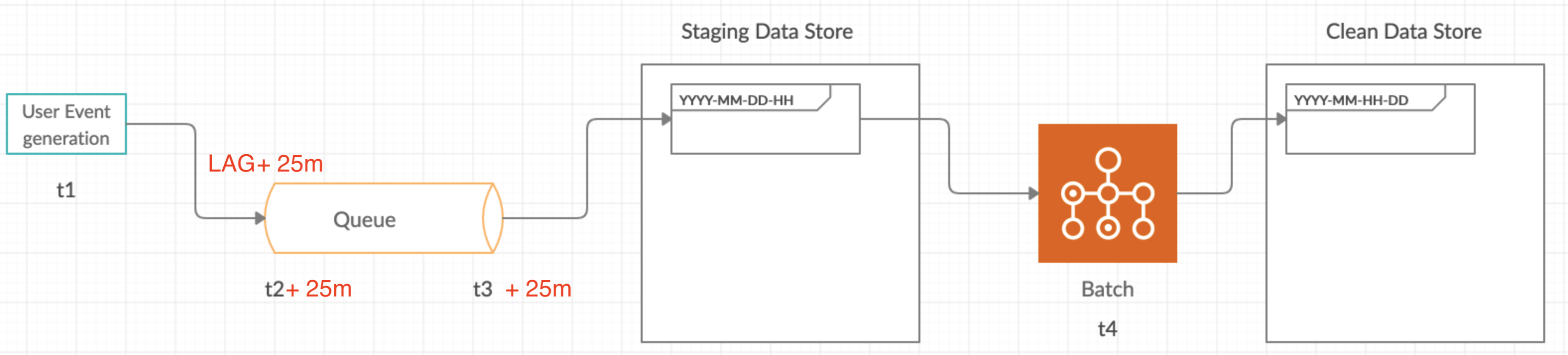
A late arriving event is an event which gets generated at a time, say t1 but due to network latency or instability arrives later, by say 25 minutes, so t2 + 25. How do we deal with this? If the batch process has already run for that partition before the event arrives, we will have failed to process that event.
Let’s look at 3 decisions to make when faced with this scenario
1. Choosing a “partition” time for the raw staging area
When we store data from the stream to a staging data store we would want to partition them by time, as granular as you need. But in most cases it is by the hour. So which time should we use for this? Is it the time the event was generated at the client side(t1)? or the time the event entered the queue(t2)? or the time the event gets stored(t3)?
The natural approach would be to use t1. But choosing this would lead to late arriving events not getting processed.
Consider an example say an event(e1) happens at 9:50PM (t1) but arrives at the staging data store at 10:10PM (t3) and since our batch process runs at the beginning of every hour with the input being the last hours data partition this means we have missed the event e1. And our batch process is no longer idempotent(process which produces the same output for the same input each time).
A more stable approach would be to use the event store time as the date to partition by for the raw data store. This approach will make our batch process idempotent since the data in the raw staging area will always produce the same output when run over any partition. This will also make running backfills on the staging data store stable.
2. Choosing data and partitioning schema
While we do have an idempotent data pipeline, we need to consider the actual event time since that represents the real data. If a user wants to see all the events that were produced in the last hour we cannot use the event store time because it does not represent the actual time the events were produced.
One way to deal with this is to partition the data by both event store time and event time. This will provide the answer for when the event was created and when it was actually processed. But will increase the data model complexity since we now have 2 partition keys. The next point will help you decide.
3. Business event loss tolerance
This is the key to deciding the tradeoff between a complex or a simple data model. You can have the data on a single partition by event processing time and define a tolerance range for late arriving events at query time. For instance if you are ok with loosing events which are late by more than an hour, your query can be something like
The above query will look at 2 partitions 2020-04-05-11 and 2020-04-05-12 and filter by event_time within them. If you are using a columnar format(which you should be using for analytical databases) such as parquet or ORC the predicate on event_time within a event processing time partition folder will be much faster.
Conclusion
Hope the points above gives you an idea of the tradeoffs that need to be made to handle late arriving events. The single date partition v double date partition tradeoff depends on your specific use case. For most cases a single partition on the event store time and defining a suitable tolerance range should be sufficient. If you have any questions, please reach out or leave a comment below.