When getting started with Apache Airflow, data engineers have questions similar to the two below
“What are people’s opinions of Airflow?” “any gotcha I need to be aware of, in Airflow?”
In this post, we look at why Airflow is popular(the good) and what are some of it’s pitfalls(the bad). This article assume you have a basic knowledge of what Apache Airflow is and the concept of DAGs and tasks.
The Good
Good news first
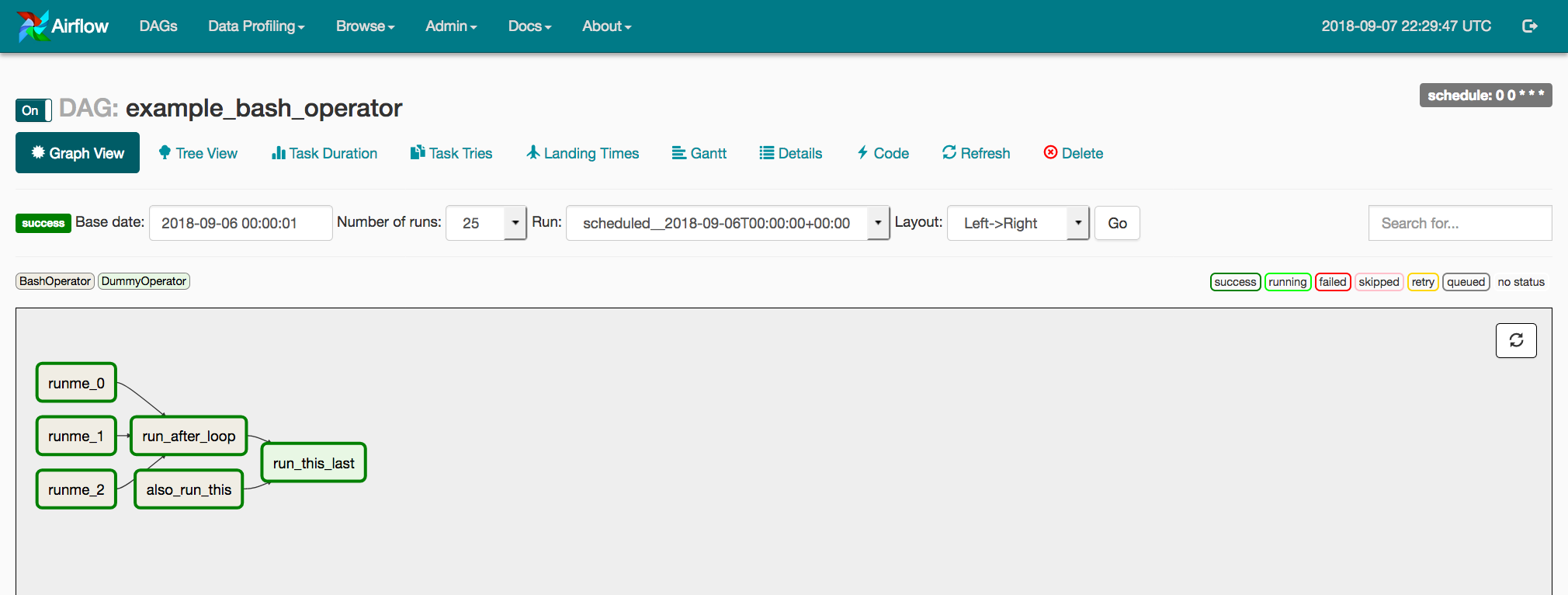
1. Dependency management
Dependency management represents the flow of data through the data pipeline. It can be visualized as some Task A -> Task B -> Task C for a simple case, but in real use cases it is very complex (eg a fan-out scenario where Task A then [Task B, Task C, Task D] in parallel then Task E )
In pre-Airflow days complex dependency was managed by writing the entire data pipeline in one script or having a database that handles the schedule time, run count, etc. But these had to be developed based on the use case and was time consuming. One of the major goals of Airflow was to handle dependency management. Airflow does this extremely well, it allows for standard data flow, complex branching using BranchPythonOperator, task retry, catchup runs, etc.
 (ref: https://airflow.apache.org/ )
(ref: https://airflow.apache.org/ )
2. Templating and Macros
The whole Airflow model is designed to operate on a time based schedule, usually rerunning the same scripts with different time ranges. As such there are option to have templated scripts that can be filled in with the appropriate time value at DAG run time. for example
from airflow import DAG
from airflow.operators.mysql_operator import MySqlOperator
default_arg = {'owner': 'airflow', 'start_date': '2020-02-28'}
dag = DAG('simple-mysql-dag',
default_args=default_arg,
schedule_interval='0 0 * * *')
mysql_task = MySqlOperator(dag=dag,
mysql_conn_id='mysql_default',
task_id='mysql_task'
sql='<path>/sample_sql.sql',
params={'test_user_id': -99})
mysql_taskand the sql file at sample_sql.sql as
USE your_database;
DROP TABLE IF EXISTS event_stats_staging;
CREATE TABLE event_stats_staging
AS SELECT date
, user_id
, sum(spend_amt) total_spend_amt
FROM event
WHERE date = {{ macros.ds }}
AND user_id <> {{ params.test_user_id }}
GROUP BY date, user_id;
INSERT INTO event_stats (
date
, user_id
, total_spend_amt
)
SELECT date
, user_id
, total_spend_amt
FROM event_stats_staging;
DROP TABLE event_stats_staging;In the above the macros.ds will be replaced with the execution_time when the DAG is being run. In addition to inbuilt macros you can also pass in parameters at run time, by passing it in the params field of the task operator.
3. Operators
Apache Airflow has a lot of operators that you can use to build your pipeline. If you are getting started with Airflow for your project, search for an operator for your use case before writing your own implementation. In case you have a unique use case, you can write your own operator by inheriting from the BaseOperator or the closest existing operator, if all you need is an additional change to an existing operator.
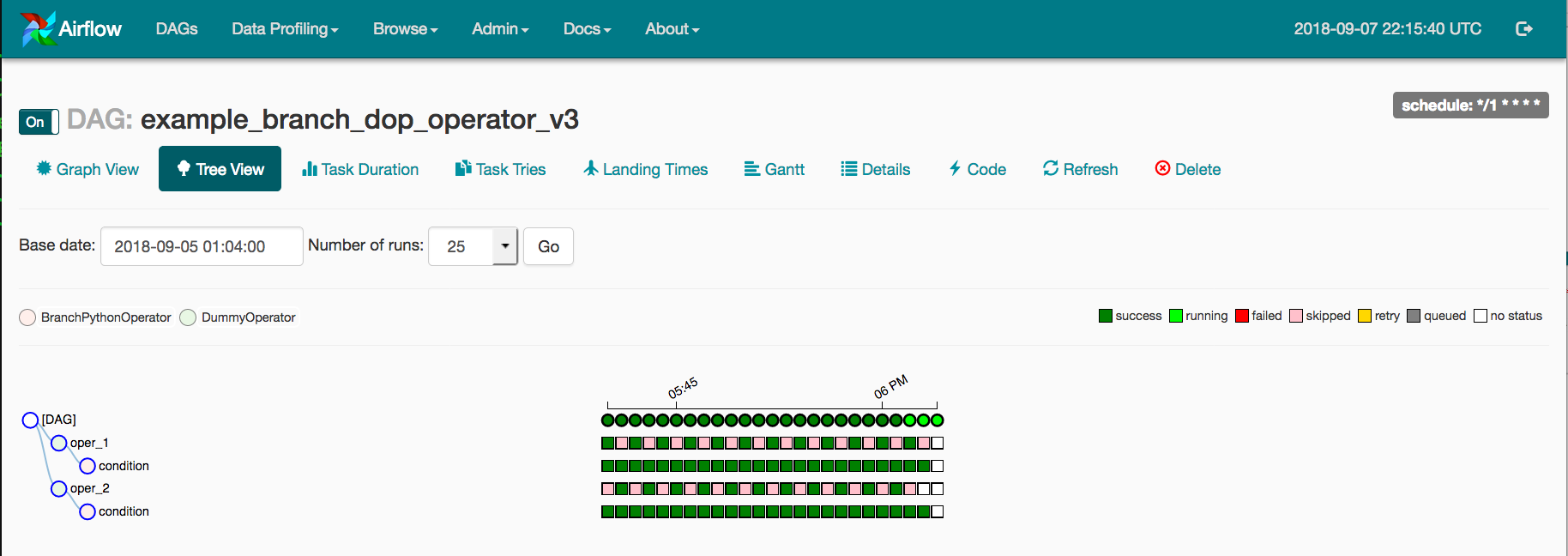
4. UI and logs
Apache Airflow has a great UI, where you can see the status of your DAG, check run times, check logs, re-run tasks and much more. By default these are open to every one who has access to the server, but you can set up additional authentication if required. The logs can be synced to external storage, providing an easy way to check for errors, etc.
 (ref: https://airflow.apache.org )
(ref: https://airflow.apache.org )
5. Based on functional principles
Apache Airflow was designed based on functional principles. The key ideas are data immutability and idempotence.
Data immutability in this context is storing the raw data and processing it and storing the processed data separately. This provides us the option to rerun the data process in case of errors. Idempotence process is a process where given an input, the output will always be the same. This makes the process easy to test and re-run.
Following these principles, the data flows through the data pipeline, being transformed at each task and producing an output being used in the next task. At the end of the data pipeline you will have the raw data and the transformed data. These concepts will help us manage, trouble shoot and backfill data. Backfill is the process where you have to rerun your data pipeline due to some change in business logic, code error, etc.
6. Open source
Apache Airflow is a very active open source project with a huge active community. This means for most of the issues you face, you can find an answer online, you can read the source code to understand how it works under the hood and you can make commits to Airflow.
The Bad
1. Data processing model is not intuitive to new engineers
New engineers have a hard time internalizing the way Airflow is meant to be used. The most common complaint is writing test cases. Writing test cases is extremely difficult for data pipelines handling raw data. There have been some improvements in this area, e.g.greatexpectations. The other complaints arise from writing non-idempotent tasks, which when failed and retried leads to duplicate data or messy data or failures. Read this article to get a good understanding of the recommended data processing model.
2. Changing schedule interval requires renaming the DAG
If you decide to change the schedule, you have to rename your DAG. Because the previous task instances will not align with the new interval.
3. CI/CD is tricky
If you are deploying Airflow on Docker, the CI/CD process that restarts the Docker container will kill any running processes, you will have to time your deploys to correspond with a no activity time or DAG run(s) that you would be ok with being restarted or being partially rerun. This approach would be ok, if you have a few DAGs, but if the number of DAGs are high it is advisable to use something like a git-sync or s3 sync, where your DAG files are synced to external storage and your deploy basically syncs them to your docker.
4. No native windows support
It is not straight forward to natively run Airflow on windows. But this can be mitigated by using Docker.
Conclusion
In spite of all the cons of Apache Airflow, it still provides an excellent batch data processing framework to manage ETL. There are a lot of companies which use Airflow for the benefits it provides. Hope this post gives you an idea of the pros and cons of Apache Airflow. If you have any questions, thoughts or comments, please leave a comment below.