How to go from knowing just SQL to building pipelines from scratch?
In production, you need to handle complex queries, perform performance tuning, and make ambiguous design decisions. No amount of YouTube videos will teach you how to think about their tradeoffs.
Anyone can build a pipeline that works, but getting it to produce the right dataset and ensuring it’s maintainable requires knowing exactly how to build one for your use case.
You know you can put in the work to land a well-paying data job. But you don’t have a step-by-step guide to get you there.
"I had a job interview and they asked me why you would need Spark and not just use Python to build ETL. I just couldn't answer that on the spot. Now I completely understand it."
— Eduardo, Data Engineer, Texas
Confidently build data products that delight stakeholders
Solve business problems with technology. Enable data-driven decision making for any org.
Demonstrate expertise by focusing on business outcomes.
Guide stakeholders from “hey, can I get revenue data?” to data products that are intuitive for decision-making.
Make your stakeholders’ lives easy, and you will go far in your career.
Apply the right data design principles for your use case
Learn the key data engineering design patterns & how they fit together.
Data Warehousing: Build tables analysts actually want to usePipeline Design: Handle late events, backfills, and failures gracefullyData Flow(Medallion): Standardize how data flows through your system
Data Quality: Ensure that the data you present to your stakeholders is correctScheduling and Orchestration patterns: Create pipelines that produce output data on timeData Storage Patterns: Choose the right storage strategy to make analytics fast and cost-effectiveDistributed Data Processing Patterns: Scale your pipeline confidently as data volume grows
Tool’s you’ll use:



"I always thought when we go to a new client and we saw a very big table with hundreds of columns, we always thought this is not the best thing to do, but now going back to some of the clients... they might be right. I'm seeing my past work completely differently now."
— Marlo, Data Engineer, Brazil
Learn industry standard best practices with capstone projects
Practice building real-world data products with two capstone projects.
- Data Warehouse for advertisement analytics.
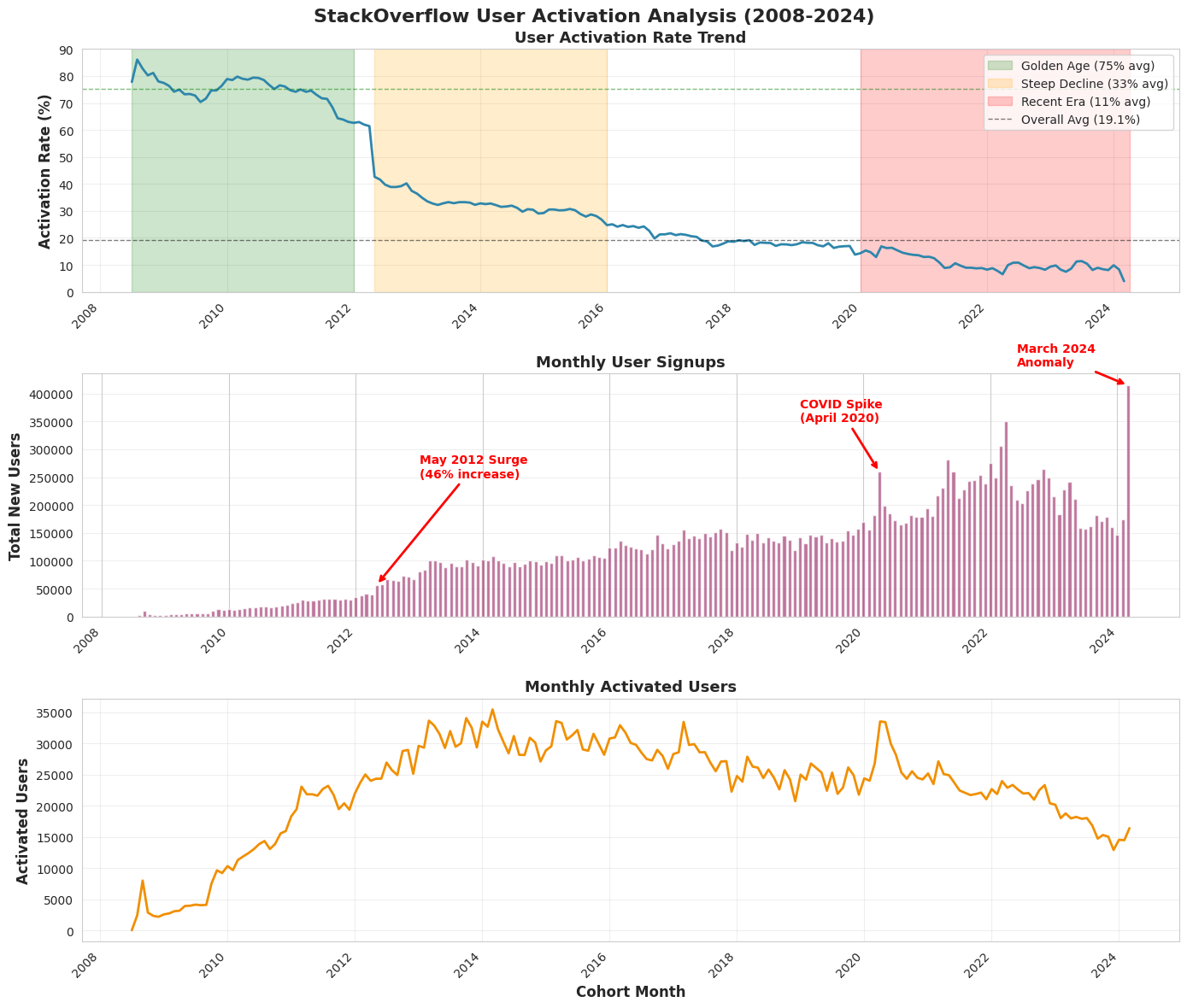
- Data Warehouse built with 50GB+ real StackOverflow data
You’ll learn how to show outcomes based on real data (E.g., StackOverflow User Trends)
Learn how to build an end-to-end project by following a step-by-step approach.
Enroll in my course and start learning the key data engineering concepts and how to apply them in real life.
Confidently build data products from start to finish.
"This workshop covered many important topics such as how to organize code, how to write modular code, and what a standard industry-level data engineering project looks like. These are aspects that most people on YouTube tend to neglect, but you addressed them in depth. This content has been very helpful for me & gave me the clarity I was looking for."
— Student
"I knew the tools, but never knew how to put them all together. Your posts are well-detailed, but the workshop demystified things for me. Because your code-organization is consistent, I think I'll now be able to run through various tools/examples."
— Student
Enroll now
Complete bundle
$499
Self-paced video course · One-time payment · Lifetime access
Total video hours
10 hrs
Examples & exercises
160+
Office hours
Thu
7–9 PM EST
Weekly office hours
Thu · 7:00 PM – 9:00 PM EST
1 month
All sessions are recorded and available for watching at your own pace.
What you'll learn
- Data Warehouse design & Medallion Architecture
- Pipeline Design Patterns & Data Quality checks
- Orchestration & Scheduling Patterns
- Spark API & Data Storage Optimization
- Distributed Data Processing & Optimizations
- Interview Prep & two capstone projects
Tools you'll use
Enroll Now
Syllabus
Part 1: Data Engineering Design Patterns
- Data Warehousing
- Data Pipeline Design
- Medallion Data Flow Architecture
- Data Quality
- Scheduling & Orchestration Patterns
- Testing Your Code
- Data Contracts
- Capstone Project
- Interview Preparation
Part 2: Distributed Data Processing with Apache Spark
- Processing Data with Apache Spark
- Data Storage Patterns to Optimize Your Pipelines
- Data Process Optimizations in Apache Spark
- Capstone Project
"I have 15 years of experience but I used to work on a different tool altogether. I transitioned as a data engineer one and a half year ago. The course is helping me fill those gaps."
— Srija, Data Engineer
FAQs
The course is workshop-style. You follow along and write code as you learn, not just watch. Every chapter includes fully runnable notebooks with examples and exercises, so you actually internalize what you’re learning.
Here’s a sample lesson so you can see it for yourself:
Chapter: Sample chapter
Code: Code for sample chapter
Most courses teach you how to build a pipeline. This one teaches you how to think about building the right one.
- Concept before code — every technique is grounded in the why before the how.
- Tradeoffs over tutorials — each chapter covers caveats, rules of thumb, and when not to use something.
- Cumulative structure — chapters build on each other so you understand how design decisions interact, not just how each one works in isolation.
- Wisdom-level exercises — you practice making judgment calls, not just following steps. By the end you don’t just have a portfolio project. You have a mental model for designing data systems from scratch.
Yes. LLMs give you answers. This course builds the judgment to know which answer is right for your situation.
- Tradeoff judgment — internalized reasoning for ambiguous design decisions, not just information recall.
- Mental model shifts — changes how you see problems, not just how you solve them.
- How systems fit together — understanding how each concept constrains the others, built cumulatively in order. LLMs are a great reference. This course is how you stop needing one for every decision.
Yes, it is designed for beginners. Read the following for a quick primer on prerequisites.
Office hours are 7 PM - 9 PM EST on Thursdays, for 1 month after purchase. All sessions are recorded and available for watching at your own pace.
Have a question not answered here? Send me an email at help@startdataengineering.com and I will get back to you shortly.