1. Introduction
If you’ve worked on a data team, you’ve likely encountered situations where multiple teams define metrics in slightly different ways, leaving you to untangle why discrepancies exist.
The root cause of these metric deviations often stems from rapid data utilization without prioritizing long-term maintainability. Imagine this common scenario: a company hires its first data professional, who writes an ad-hoc SQL query to compute a metric. Over time, multiple teams build their own datasets using this query—each tweaking the metric definition slightly.
As the number of downstream consumers grows, so does the volume of ad-hoc requests to the data team to investigate inconsistencies. Before long, the team spends most of its time firefighting data bugs and reconciling metric definitions instead of delivering new insights. This cycle erodes trust, stifles career growth, and lowers team morale.
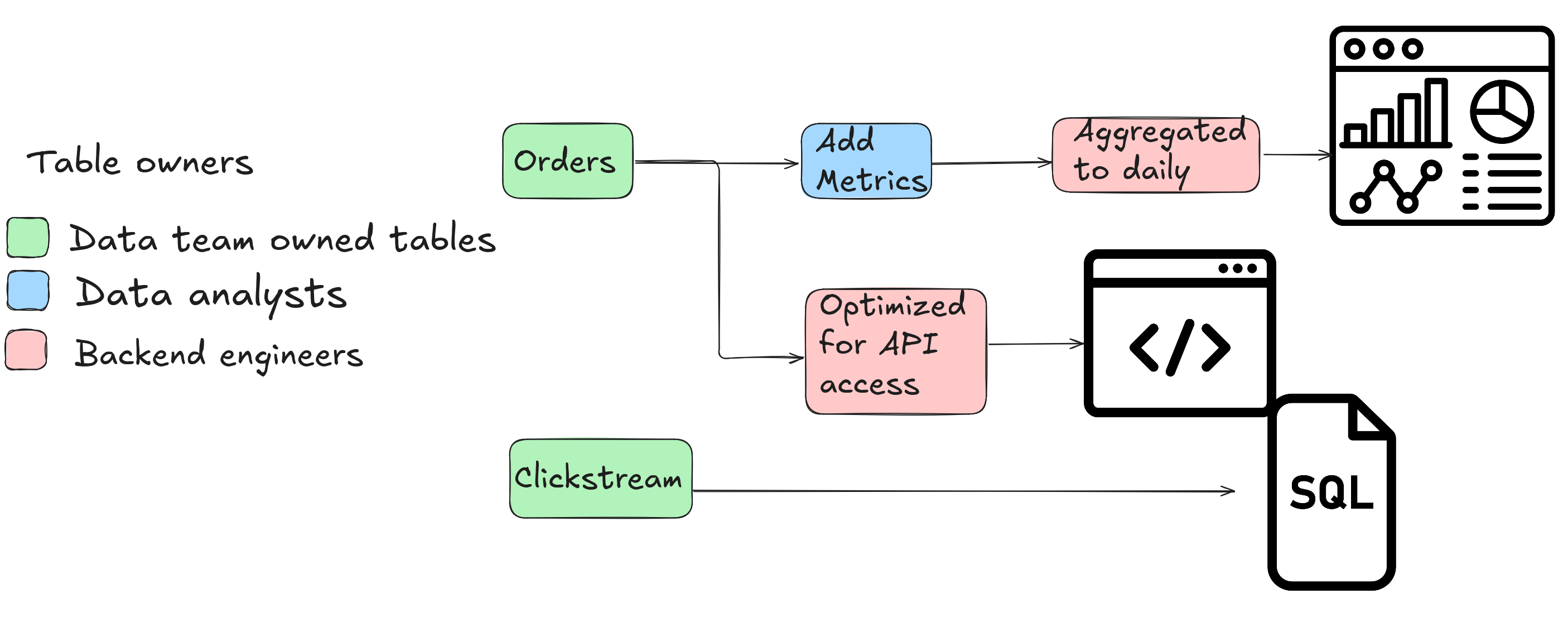
This post explores two options to reduce ad-hoc data issues and empower consumers to derive insights independently.
2. Centralize Metric Definitions in Code
The foundation of consistency lies in defining critical metrics in a single repository. While code organization varies (e.g., medallion architecture, dbt), metric consolidation typically follows one of two approaches.
Option A: Semantic Layer for On-the-Fly Queries
A semantic layer allows you to define dimensions (columns in the GROUP BY clause) and metrics (computed columns) in a static format, often YAML files. Consumers (APIs, BI tools) query this layer, which dynamically generates SQL against raw tables.
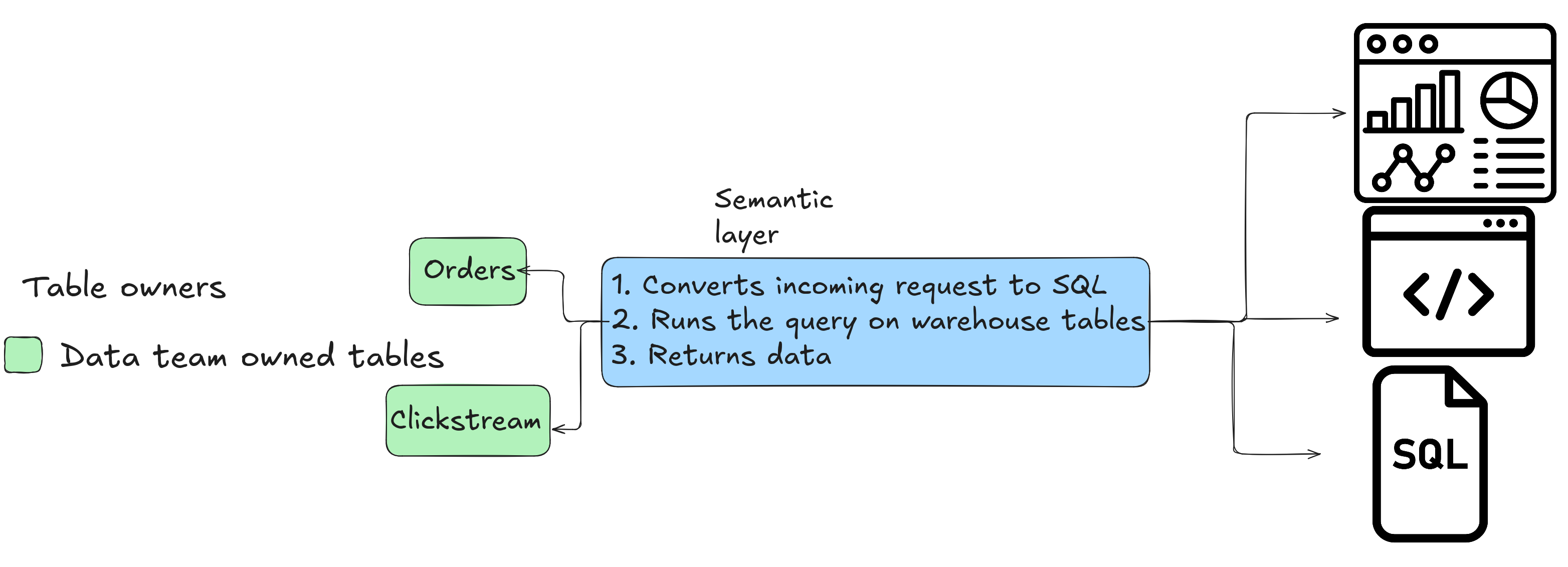
Pros: - Flexibility: No need to pre-build tables for every use case; aggregations adapt to query requirements. - Transparency: Centralized definitions in human-readable formats (YAML) for technical and non-technical teams. - Freshness: Real-time data access without dependency on pre-computed tables.
Cons: - Cost: Repeated query execution can increase compute expenses (mitigated by caching in some tools). - Tooling: Limited mature open-source options (Cube.js is a notable exception).
Option B: Pre-Aggregated Tables for Consumers
This approach involves creating pre-computed tables with fixed metrics and dimensions tailored to specific use cases.
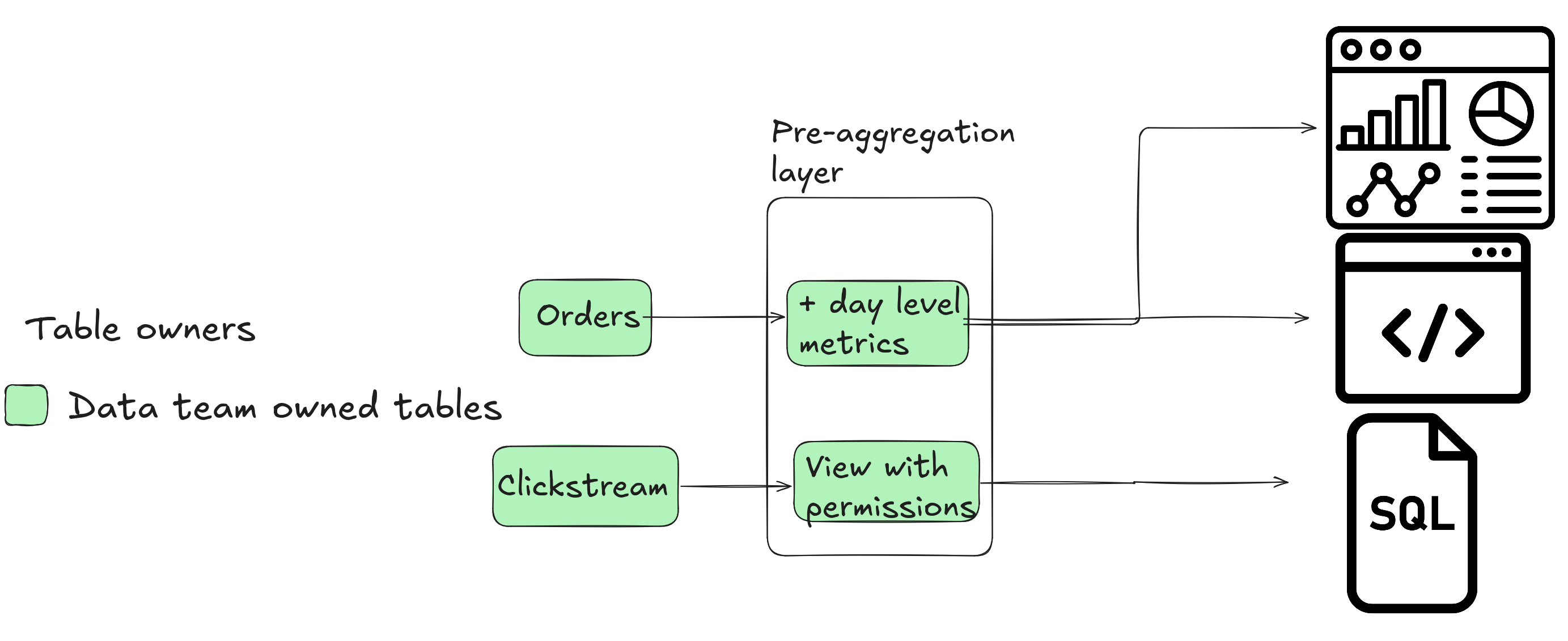
Pros: - Simplicity: Easy to implement for small-scale use cases. - Cost Efficiency: Reduced compute costs compared to dynamic querying. - Control: Metrics are explicitly defined in code.
Cons: - Scalability: Managing custom tables becomes unwieldy as consumers multiply. - Maintenance: Metric consistency across tables is challenging (often leading teams to reinvent a semantic layer).
3. Conclusion & Recap
Recap: - Semantic Layers offer dynamic querying and centralized definitions but require investment in tooling and optimization. - Pre-Aggregated Tables are simple but unsustainable at scale, often forcing teams to build internal semantic layers.
Recommendation: If possible, adopt a semantic layer tool like Cube.js early to balance flexibility and scalability. Reserve pre-aggregated tables for niche use cases with strict cost constraints.
Please let me know in the comment section below if you have any questions or comments.